Alexander Andrewsvia Unsplash
为了让你理解什么是Q学习,你需要一些强化学习的知识。
强化学习是机器学习的分支,它的目的是训练一个模型,利用为特定问题创建的一系列解决方案返回一个最佳解决方案。
该模型将有各种解决方案,当它选择正确的解决方案时,会产生一个奖励信号。如果模型的表现更接近目标,就会产生一个正的奖励;但是,如果模型的表现离目标更远,就会产生一个负的奖励。
强化学习包括两种类型的算法
- 无模型。这排除了环境的动态变化,以估计最佳政策。
- 基于模型。 这包括环境的动态变化来估计最佳策略。
什么是Q-Learning?
Q-Learning是一种无模型的强化学习算法。它试图随机地找到能使奖励最大化的下一个最佳行动。该算法根据一个方程式更新价值函数,使其成为一个基于价值的学习算法。
这就像当你试图找到一个解决你当前情况的方案,以确保你获得最大的利益。该模型可以生成自己的规则,甚至在提供的政策之外进行操作。暗示不需要政策,使其成为一个非政策学习者。
非政策性学习者是指模型学习最佳政策的价值,而不考虑代理人的行动。政策性学习者是指模型学习代理人所执行的政策的价值,找到一个最佳政策。
让我们来看看基于推荐系统的广告。广告没有一天是基于你的搜索历史或以前的手表。然而,Q-Learning可以更进一步,优化广告推荐系统,推荐已知经常一起购买的产品。奖励信号是如果用户购买或点击推荐的产品。
Q-Learning中的 "Q "代表质量。它代表一个给定的行动在获得奖励方面的有效性。
贝尔曼方程
贝尔曼方程是以理查德-E-贝尔曼命名的,他被称为动态编程之父。动态编程的目的是简化复杂的问题/任务,将其分解为较小的问题,然后在攻击较大的问题之前递归地解决这些较小的问题。
贝尔曼方程确定了一个特定状态的价值,并得出了在该状态下的价值的结论。Q函数使用贝尔曼方程并使用两个输入:状态(s)和行动(a)。
如果我们知道每个行动的所有预期回报,我们怎么知道采取哪种行动呢?你可以选择产生最佳奖励的行动序列,我们可以把它表示为Q值。使用这个方程式。

- Q(s, a)代表在状态 "s "和选择行动 "a "时所产生的Q值。
- 这是由r(s, a)计算出来的,r(s, a)代表收到的即时奖励+来自状态's'的最佳Q值。
是控制和决定对当前状态的重要性的折扣系数。
该方程由当前状态、学习率、折扣系数、与该特定状态相关的奖励和最大预期奖励组成。这些都是用来寻找代理人的下一个状态的。
什么是Q表?
你可以想象Q-learning提供的不同路径和解决方案。因此,为了管理和确定哪个是最好的,我们使用Q-表。
Q-表只是一个简单的查找表。它的创建是为了让我们能够计算以及管理最大的预期未来回报。我们可以很容易地确定环境中每个状态的最佳行动。在每个状态下使用贝尔曼方程,我们得到预期的未来状态和奖励,然后将其保存在一个表中,以便与其他状态进行比较。
比如说
| 状态。 | 行动。 | |||
 |  |  |  | |
| 0 | 0 | 1 | 0 | 0 |
| .. | ||||
| 250 | -2.07469 | -2.34655 | -1.99878 | -2.03458 |
| .. | ||||
| 500 | 11.47930 | 7.23467 | 13.47290 | 9.53478 |
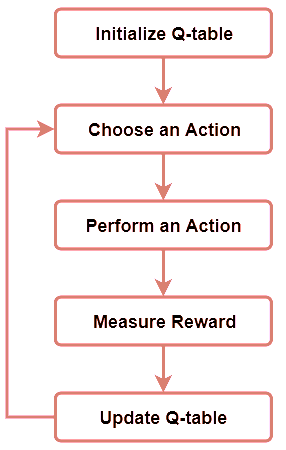
Q-learning过程
1.初始化Q-表
第一步是创建Q表
- n = 行动的数量
- m = 状态的数量
例如,n可以是左、右、上、下,而m可以是开始、空闲、正确的行动、错误的行动,以及游戏的结束。
2.选择并执行一个行动
我们的Q表应该全部为0,因为没有执行过任何行动。然后,我们选择一个行动,并将其更新到Q表的正确部分。这说明该行动已经被执行。
3.使用贝尔曼方程计算Q值
使用贝尔曼方程,计算实际奖励的价值和刚刚执行的行动的Q值。
4.继续步骤2和3
重复步骤2和3,直到一个情节结束或Q表被填满。