


图片来自Pexels的Ella Olsson
贝叶斯定理为我们提供了一种根据新证据更新我们信念的方法,同时考虑到我们先前信念的强度。运用贝叶斯定理,你要回答的问题是:根据新的证据,我的假设的可能性是多少?
在这篇文章中,我们将讨论贝叶斯定理可以改善你的数据科学实践的三种方式。
- 更新
- 沟通
- 分类
到最后,你会对这个基础概念有一个深刻的理解。
#1 - 更新
贝叶斯定理提供了一个测试假设的结构,考虑到了先前假设和新证据的强度。这个过程被称为 "贝叶斯更新"。
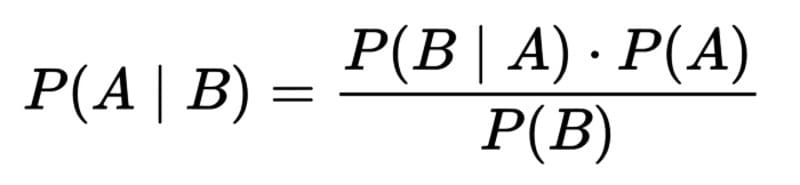
贝叶斯定理,其中A代表假设,B代表与假设相关的新证据。
用话说,这个公式是 "给定B的A的可能性 等于*(开放式括号*) 给定A的B的可能性 倍A的可能性*(闭括号*)。 除以 B的可能性"。
让我们再看一遍这个公式,这次要加上变量的定义。
"根据新证据,假设的可能性 等于假设假说也是真的,新证据为真的可能性 倍在观察到新证据之前假设的可能性,全部(除以) ,新证据的可能性。"
这可以进一步缩短。
"后验概率 等于可能性 倍先验概率除以边际概率"。
无论贝叶斯定理现在听起来是否直观,我保证你一直在使用它。
现实世界的例子
假设你的朋友打电话告诉你,她非常抱歉,但她今晚不能来吃饭了。她最近收养了一只宠物考拉,它已经患上了鼻炎。她真的需要呆在家里观察情况。
你的假设是,你的朋友不会毫无理由地抛弃你。(毕竟,你做了一个卑鄙的PH值,你的朋友会疯狂地跳出来。)鉴于最近她的新宠物的证据,你的假设是真的可能性有多大?

照片:Valeriia MillerfromPexels
为了评估我们的朋友没有参加晚餐是因为她在照顾考拉的后验概率 ,我们需要考虑你的朋友需要留在家里照顾考拉的可能性,因为假设你的朋友是一个正直的人,不会毫无理由地放弃晚餐计划。你可能会得出结论,一个典型的负责任的好朋友很有可能会留在家里照顾宠物。
接下来,我们把这个可能性乘以先验概率。在你的朋友打电话之前,你对她对晚餐计划的承诺有多大的信心?如果你相信你的朋友坚如磐石,通常不愿意在最后一刻改变计划,那么你的先验概率就很高,无论有什么新的证据,你都不太可能改变这个观点。另一方面,如果你的朋友很古怪,而且你已经在想她是否会打电话取消计划,那么你的先验概率就很弱,这也可能让人怀疑她关于留在家里陪考拉的说法。
最后,我们将上述计算结果除以考拉所有权的边际可能性?
贝叶斯推理是建立在这种灵活的、常识性的方式上的,即根据我们的先验的强度和新证据的可能性来更新我们关于世界的模型。事实上,贝叶斯定理的最初应用是用来评估上帝的存在。
当涉及到生命和数据科学的关键问题时,作为一种评估信仰如何随时间变化的直观方式,你无法击败贝叶斯定理。
#2 - 沟通
正如贝叶斯定理可以帮助你理解和阐明你在面对新证据时如何更新你的理论一样,贝叶斯也可以使你成为一个更强大的数据科学交流者。
数据科学从根本上讲是关于应用数据来改善决策的。
只有两件事能决定你的生活结果:运气和你的决定的质量。你只能控制这两件事中的一件。- 安妮-杜克,扑克冠军和作家
提高决策质量往往意味着要说服决策者。正如每个人的情况一样,你的组织的决策者正在进入对话中
现实世界的例子
我曾经是一家热气球制造商的顾问。我的任务是帮助建立一个数据库,以提高客户对其供应链、制造过程和销售的端到端理解。
当工厂经理在第一天带我们参观车间时,他自豪地描述了一个新的供应商合同,以获得更轻、更便宜的输入材料。
但是有一个问题。当我的团队将整个企业不同数据源的数据表连接起来时,我们发现了新供应商的材料与2.5%的废品增加之间的联系。

照片:Darren LeeonUnsplash
该工厂的经理有一个非常强烈的预感,即新的供应商对他的业务是一个净的积极因素。我们有一些相反的证据。我们也有贝叶斯定理。我们理解这个事实。
先验越强,改变它需要的证据就越多。
在向工厂经理说明我们的发现之前,我们需要收集更多的证据,证明没有其他因素(如破旧的机器、新员工、环境条件等)导致了不同的废品水平。
最终,我们带着更多的证据找到了这位经理,并帮助他重新谈判了供应商合同。
#3 - 分类
贝叶斯定理可以应用于文本分析用例,这种技术被称为天真贝叶斯,因为它天真地假设数据集中的每个输入变量(在这种情况下,每个词)是独立的。
现实世界的例子
假设你发现了一堆由你祖父母写的信。他们的关系有点动荡,有足够的戏剧性来证明坎坷的爱情并不局限于真人秀节目中的年轻人。

照片:RODNAE ProductionsfromPexels
你想建立一个情感分类器来确定大多数内容是积极的还是消极的。做到这一点的一个方法是利用天真贝叶斯。
像天真贝叶斯这样的生成式分类器 将建立一个模型,说明一个类别(在这种情况下,正面或负面)如何产生一些输入数据。给出一个观察结果(来自我们的信件测试语料库的一个新句子),它将返回最可能产生该观察结果的类别。这与判别性分类器(如逻辑回归)形成对比,后者学习输入特征的预测能力。
Naive Bayes是建立在词包技术之上的--基本上是将文档转化为直方图,统计每个词的使用次数。
你可以使用我们在第一部分学习的贝叶斯推理公式的一个略微修改的版本来计算每个观察的最有可能的类别。稍作修改的是天真贝叶斯的天真 部分:假设每个词的概率在给定的类别下是独立的,因此你可以将它们相乘,以产生该句子落入该类别的概率。
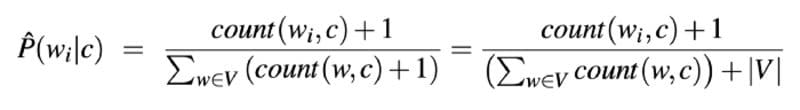
通过 语音和语言处理 作者 :Daniel Jurafsky & James H. Martin
在上面的公式中,w 代表文件c 中的一个词的计数*。* 公式的分母是词落入给定类别的条件概率之和。
公式中的+1可以防止在一个类别中没有观察到一个词的情况下乘以零的机会。这种加一的技术被称为拉普拉斯平滑法。
最后,|V|由所有类别中的所有词的联合组成。
贝叶斯定理的词汇
- 后验概率:根据新证据,假设的可能性
- 可能性:假设假设为真的情况下,证据为真的可能性
- 先验概率:在新证据出现之前,你相信假设为真的强度
- 边际可能性:证据
- 天真贝叶斯(Naive Bayes):一种分类算法,假定数据集的特征之间是天真的独立。
- 生成式分类器:对某一特定类别如何产生输入数据进行建模
- 字袋:文本的简化表示,将文件转化为柱状图
- 拉普拉斯平滑法:一种简单的加法平滑技术,以避免乘以零。
摘要
我有一个强烈的先验信念,即贝叶斯定理对数据科学家是有用的,但我将根据你在评论中给我留下的反馈更新后验概率。我期待着听到你讲述你在生活和工作中如何使用贝叶斯定理。
