


引言
时间序列数据是对同一变量在多个时间点上的测量序列,在现代数据世界中无处不在。就像表格数据一样,我们经常想要生成合成时间序列数据来保护敏感信息,或者在真实数据很少的情况下创建更多的训练数据。合成时间序列数据的一些应用包括传感器读数、带有时间戳的日志信息、金融市场价格和医疗记录。额外的时间维度,即不同时间的趋势和相关性与变量之间的相关性一样重要,这给合成数据带来了额外的挑战。
在Gretel,我们以前发表过关于合成时间序列数据的博客(金融数据,时间序列基础知识),但我们一直在寻找能够改善我们合成数据生成的新模型。我们非常喜欢DoppelGANger模型和相关论文(使用GANs共享网络时间序列数据。Lin等人的《使用GANs共享网络时间序列数据:挑战、初步承诺和开放问题》),并正在将这个模型纳入我们的API和控制台。作为这项工作的一部分,我们在PyTorch中重新实现了DoppelGANger模型,并很高兴将其作为我们开源的gretel-synthetics 库的一部分发布。
在这篇文章中,我们简要介绍了DoppelGANger模型,提供了PyTorch实现的示例用法,并在合成每日维基百科网络流量的任务中展示了出色的合成数据质量,与TensorFlow 1的实现相比,运行时间提高了约40倍。
DoppelGANger模型
DoppelGANger是基于生成对抗网络(GAN),并进行了一些修改以更好地适应时间序列生成任务。作为一个GAN,该模型使用对抗性训练方案,通过比较合成数据和真实数据,同时优化鉴别器(或批评者)和生成器网络。一旦训练完成,任意数量的合成时间序列数据就可以通过向生成器网络传递输入噪声来创建。
在他们的论文中,Lin等人回顾了现有的合成时间序列方法和他们自己的观察,以确定局限性,并提出了几个具体的改进措施,构成了DoppelGANger。这些改进包括从通用的GAN改进,到时间序列的具体技巧。下面列出了其中一些关键性的修改。
- 生成器包含一个LSTM以产生序列数据,但有一个批处理设置,每个LSTM单元输出多个时间点以改善时间相关性。
- 在训练和生成中支持可变长度的序列(计划中,但尚未在我们的PyTorch版本中实现)。例如,一个模型可以使用和创建10或15秒的传感器测量值。
- 支持不随时间变化的固定变量(属性)。这种信息经常出现在时间序列数据中,例如,金融价格历史数据中与每只股票相关的行业或部门。
- 支持连续变量的每例缩放,以处理具有大动态范围的数据。例如,受欢迎的维基百科页面与罕见的维基百科页面的页面浏览量存在几个数量级的差异。
- 使用带有梯度惩罚的Wasserstein损失来减少模式崩溃并改善训练。
关于术语和数据设置的一个小说明。DoppelGANger需要有多个时间序列例子的训练数据。每个例子由0个或更多的属性值、不随时间变化的固定变量和每个时间点上观察到的1个或更多的特征组成。当组合成一个训练数据集时,这些例子看起来就像一个2D的属性阵列(例子x固定变量)和一个3D的特征阵列(例子x时间x时间变量)。根据任务和可用的数据,这种设置可能需要将一些长的时间序列分割成较短的块状,作为训练的例子。
总的来说,对基本GAN的这些修改提供了一个富有表现力的时间序列模型,产生了高保真的合成数据。我们对DoppelGANger学习和生成具有不同尺度的时间相关性的数据的能力印象特别深刻,如每周和每年的趋势。关于该模型的全部细节,请阅读Lin等人的优秀论文。
使用样本
我们的PyTorch实现支持两种输入方式(numpy数组或pandas DataFrame)以及一些模型的配置选项。完整的参考文档请见synthetics.docs.gretel.ai/
使用我们模型的最简单方法是将训练数据放在pandas DataFrame中。对于这种设置,数据必须是 "宽 "格式,每一行是一个例子,一些列可能是属性,其余的列是时间序列值。下面的片段演示了从DataFrame中训练和生成数据。
# Create some random training data
df = pd.DataFrame(np.random.random(size=(1000,30)))
df.columns = pd.date_range("2022-01-01", periods=30)
# Include an attribute column
df["attribute"] = np.random.randint(0, 3, size=1000)
# Train the model
model = DGAN(DGANConfig(
max_sequence_len=30,
sample_len=3,
batch_size=1000,
epochs=10, # For real data sets, 100-1000 epochs is typical
))
model.train_dataframe(
df,
df_attribute_columns=["attribute"],
attribute_types=[OutputType.DISCRETE],
)
# Generate synthetic data
synthetic_df = model.generate_dataframe(100)
如果你的数据还不是这种 "宽 "格式,你也许可以使用pandas的pivot方法将其转换为预期的结构。目前,DataFrame的输入有些局限,尽管我们有计划在未来支持其他接受时间序列数据的方式。为了获得最大的控制权和灵活性,你也可以直接传递numpy数组进行训练(同样,在生成数据时也可以接收属性和特征数组的回馈),如下所示。
# Create some random training data
attributes = np.random.randint(0, 3, size=(1000,3))
features = np.random.random(size=(1000,20,2))
# Train the model
model = DGAN(DGANConfig(
max_sequence_len=20,
sample_len=4,
batch_size=1000,
epochs=10, # For real data sets, 100-1000 epochs is typical
))
model.train_numpy(
attributes, features,
attribute_types = [OutputType.DISCRETE] * 3,
feature_types = [OutputType.CONTINUOUS] * 2
)
# Generate synthetic data
synthetic_attributes, synthetic_features = model.generate_numpy(1000)
这些片段的可运行版本可以在sample_usage.ipynb中找到。
结果
作为一个从TensorFlow 1切换到PyTorch的新实现(底层组件如优化器、参数初始化等的潜在差异),我们想确认我们的PyTorch代码如预期般工作。为了做到这一点,我们复制了原始论文中的一些结果。由于我们目前的实现只支持固定长度的序列,我们专注于维基百科网络流量(WWT)的数据集。
WWT数据集由Lin等人使用,最初来自Kaggle,包含对各种维基百科网页的每日流量测量。每个页面都有3个离散属性(域名、访问类型和代理),以及1.5年(550天)的每日页面浏览量的单一时间序列特征。请看图片1,这是WWT数据集的几个时间序列例子。
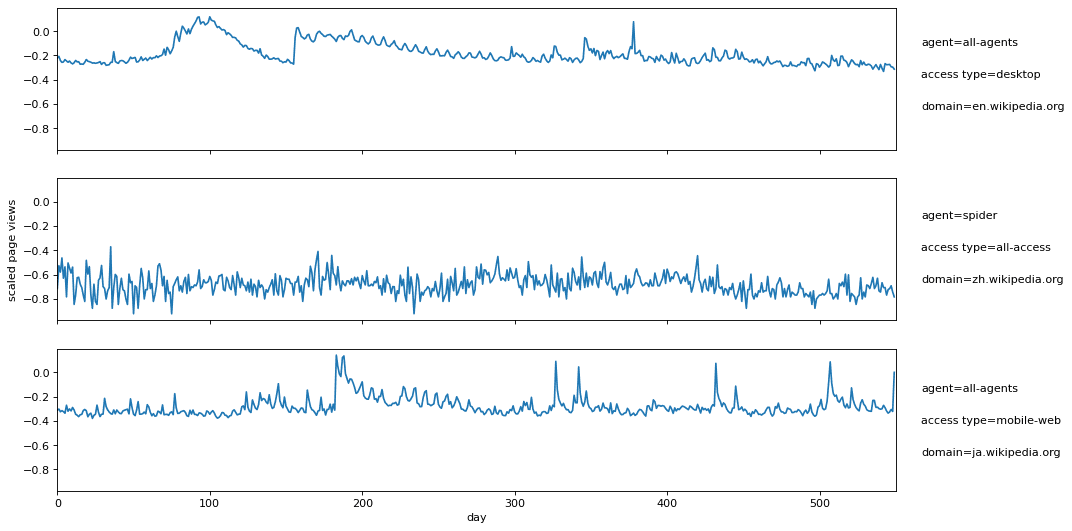
图片1:3个维基百科页面的按比例的每日页面浏览量,页面属性列在右边。
注意页面浏览量是根据整个数据集的最小/最大页面浏览量按对数比例调整为[-1,1]。我们在实验中使用的5万个页面的训练数据(已经缩放)可以在S3上以csv格式提供。
我们展示了3张图片,显示了合成数据保真度的不同方面。在每张图片中,我们将真实数据与3个合成版本进行比较。1)具有较大批次规模和较小学习率的快速PyTorch实现,2)具有原始参数的PyTorch实现,3)TensorFlow 1实现。在图片2中,我们看一下合成数据与真实分布接近的属性分布(仿照Lin等人附录中的图19)。
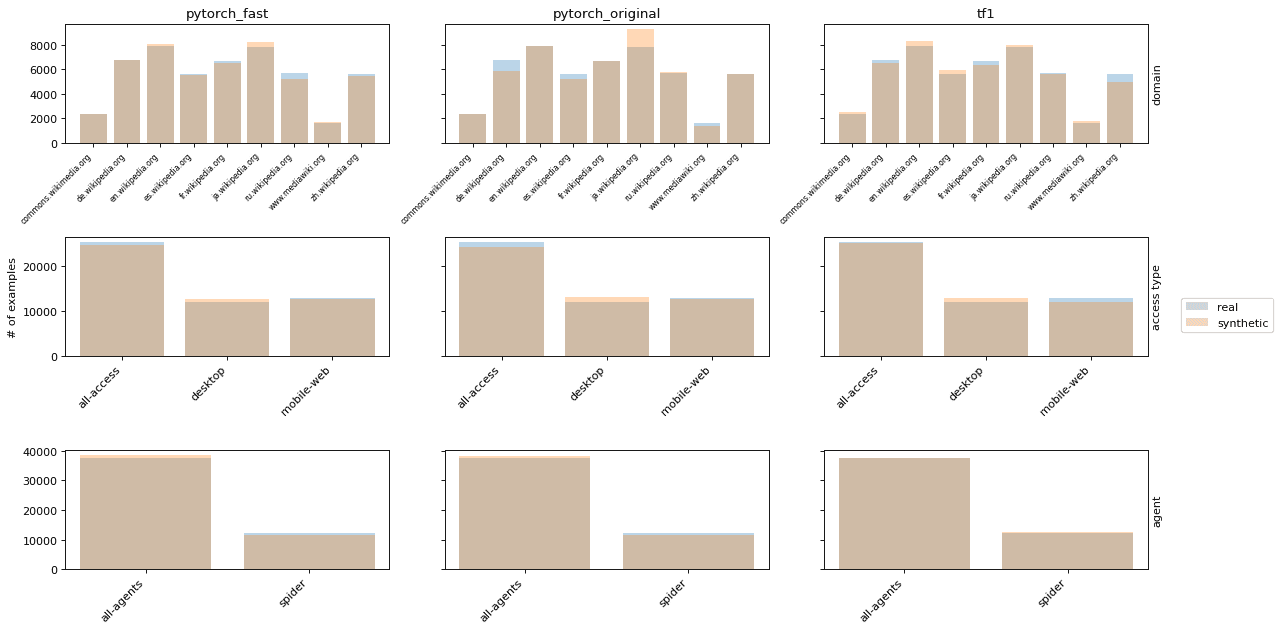
图片2:真实和合成WWT数据的属性分布。
WWT数据的一个挑战是,不同的时间序列有非常不同的页面浏览量范围。一些维基百科页面一直收到大量的流量,而另一些页面则不那么受欢迎,但偶尔会因为一些相关的当前事件而出现峰值,例如,与该页面有关的突发新闻事件。Lin等人发现,DoppelGANger在生成不同尺度的时间序列方面非常有效(原始论文的图6)。在图片3中,我们提供了类似的图,显示了时间序列中点的分布。对于每个例子,中点是550天内达到的最低和最高页面浏览量之间的一半。我们的PyTorch实现显示了类似的中点的保真度。
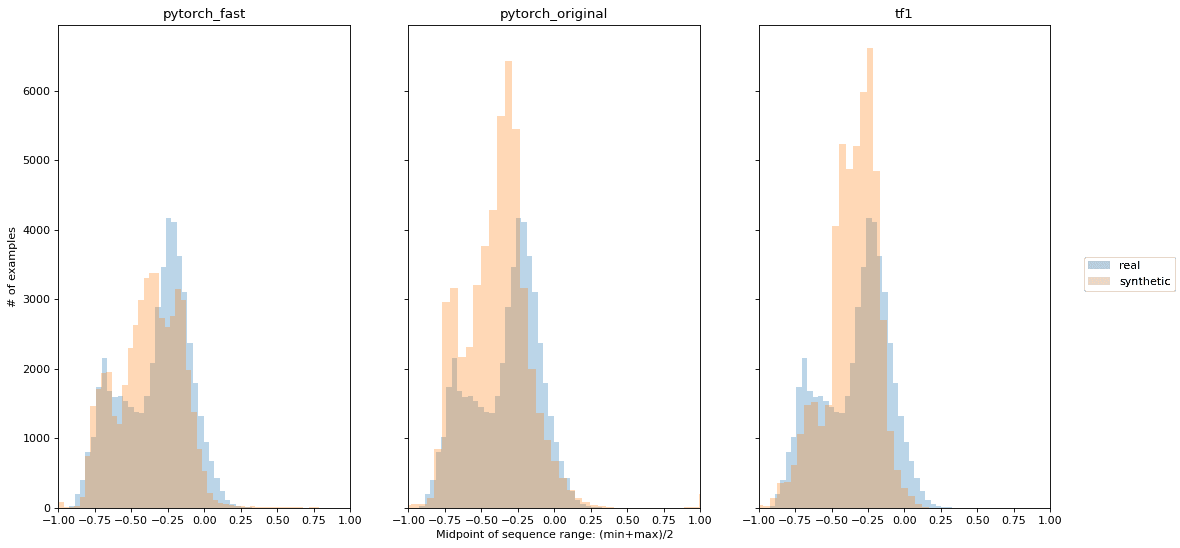
图片3:真实和合成WWT数据的时间序列中点分布。
最后,大多数维基百科页面的流量表现为每周和每年的模式。为了评估这些模式,我们使用自相关,即不同时间滞后(1天、2天等)的页面浏览量的皮尔逊相关。3个合成版本的自相关图显示在图片4中(类似于原始论文的图1)。
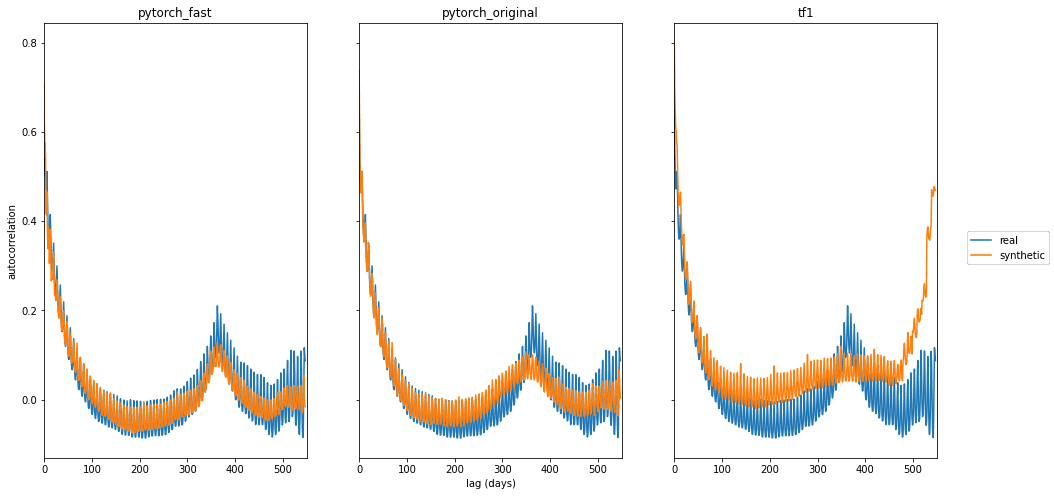
图片4:真实和合成的WWT数据的自相关。
两个PyTorch版本都产生了原论文中观察到的每周和每年的趋势。TensorFlow 1的结果与Lin等人的图1并不完全一致,因为上述图是来自我们的实验。我们观察到使用原始参数的训练有些不一致,在那里模型偶尔没有发现年度(甚至是每周)的模式。在我们的快速版本中使用的较低的学习率(1e-4)和较大的批处理量(1000)使得重新训练更加一致。
制作本节中的图像和训练3个模型的分析代码在github上以笔记本形式共享。
运行时间
最后但同样重要的是,更复杂的模型的一个关键方面是运行时间。一个需要几周时间训练的惊人模型比一个需要一小时训练的模型更有实际意义。在这里,PyTorch的实现相比之下非常好(尽管作者在论文中指出,他们没有对TensorFlow 1的代码做性能优化)。所有的模型都是用GPU训练的,并在GCP n1-standard-8实例(8个虚拟CPU,30GB RAM)上运行,并配有NVIDIA Tesla T4。从13个小时到0.3个小时,对于使这个令人印象深刻的模型在实践中更加有用是非常关键的!
| 版本 | 训练时间 |
| TensorFlow 1 | 12.9小时 |
| PyTorch, batch_size=100 (原始参数) | 1.6小时 |
| PyTorch, batch_size=1000 | 0.3小时 |
总结
Gretel.ai在我们的开源gretel-synthetics库中添加了DoppelGANger时间序列模型的PyTorch实现。我们表明这个实现可以产生高质量的合成数据,并且比之前的TensorFlow 1实现快很多(约40倍)。
