


什么是监督式学习?
监督学习是一个机器学习的子集,在这个子集里,机器学习模型是在标记的(输入)数据上训练的。因此,受监督的模型能够尽可能准确地预测进一步的结果(输出)。
监督学习背后的概念可以从现实生活中的场景来解释,比如老师第一次给孩子辅导一个新课题。
为简化起见,我们假设老师想教孩子成功识别一只猫和一只狗的形象。在辅导过程中,老师会不断向孩子展示猫或狗的图像,并让老师告知孩子该图像是狗还是猫。
猫和狗的图像可以被认为是有标签的数据,因为儿童/机器学习模型的训练过程将被告知哪些数据属于哪个类别。
监督学习的用途是什么?监督学习可以用于回归和分类问题。分类模型允许算法确定给定数据所属的组别。例子可能包括真/假,狗/猫,等等。
而 回归模型能够根据以前的数据来预测数值,例子可能包括预测某个雇员的工资,或者房地产的销售价格。
在本教程中,我们将列出监督学习中最常见的一些算法,以及关于此类算法的实用教程。
请注意,这些教程是用Python编码的。所有使用的数据集都在Kaggle上提供,因此不需要下载任何大型数据集。
线性回归
线性回归是一种监督学习算法,它根据给定的输入值来预测输出值。当目标(输出)变量返回一个连续值时,就会使用线性回归。
有两种主要的线性算法。 简单和 多重线性回归。
简单线性回归只使用一个独立(输入)变量。一个例子是通过一个孩子的给定身高来预测他的年龄。
另一方面,多元线性回归可以使用多个独立变量来预测其最终结果。一个例子是根据一个给定的房地产的位置、大小、需求等来预测它的房地产价格。
以下是线性回归的公式
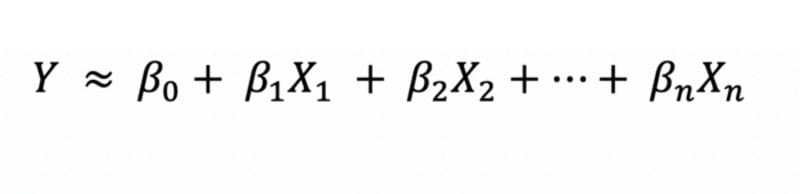
对于我们的Python例子,我们将使用线性回归来预测与给定X值有关的Y值。
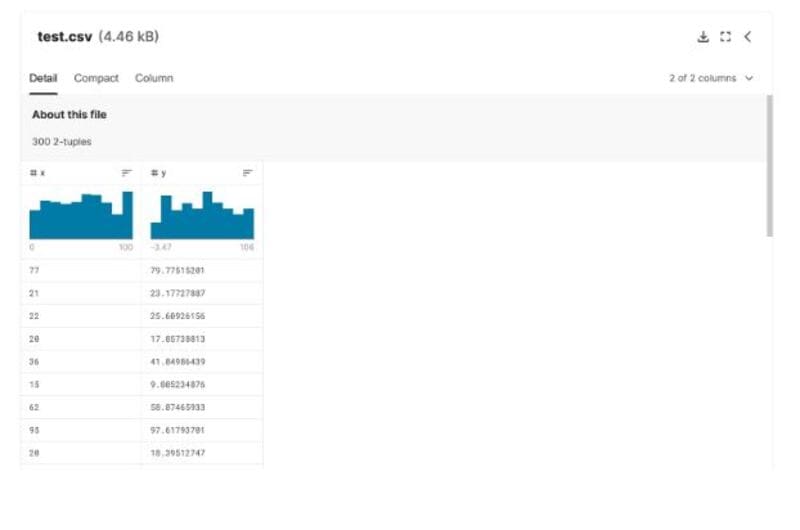
我们给定的数据集只包括两列;x和y。注意,y的结果将返回连续值。
要找到所用的数据集,请查看Kaggle上的 随机线性回归数据集。下面是给定数据集的截图。
用Python做线性回归模型的例子
1.导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import linear_model
from sklearn.model_selection import train_test_split
import os
2.读取和取样我们的数据集
为了简化我们的数据集,我们取了50个数据行的样本,并将数据值四舍五入到两位有效数字。
注意,你应该在最终完成这一步之前导入给定的数据集。
df = pd.read_csv("../input/random-linear-regression/train.csv")
df=df.sample(50)
df=round(df,2)
3.过滤空值和无限值
如果我们的数据集包含空值和无限值,可能会产生不必要的错误。因此,我们将使用clean_dataset函数来清除我们的数据集中的这些值。
def clean_dataset(df):
assert isinstance(df, pd.DataFrame), "df needs to be a pd.DataFrame"
df.dropna(inplace=True)
indices_to_keep = ~df.isin([np.nan, np.inf, -np.inf]).any(1)
return df[indices_to_keep].astype(np.float64)
df=clean_dataset(df)
4.选择我们的因果和独立值
请注意,我们将我们的数据转换为DataFrame格式。 数据框架数据类型是一个二维结构,将我们的数据排列成行和列。
5.分割数据集
我们将把我们的数据集分成训练和测试两部分。我们选择测试数据集的大小为总数据集的20%。
请注意,通过Random_state=1,每次模型运行时都会发生相同的数据分割,从而产生完全相同的训练和测试数据集。
这在你想进一步调整你的模型的情况下是很有用的。
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=1)
6.建立线性回归模型
使用导入的线性回归模型,我们可以在我们的模型中自由使用线性回归算法,绕过我们为给定模型获得的x和y训练变量。
lm=linear_model.LinearRegression()
lm.fit(x_train,y_train)
7.以分散的方式绘制我们的数据
df.plot(kind="scatter", x="x", y="y")
8.绘制我们的线性回归线
plt.plot(X,lm.predict(X), color="red")
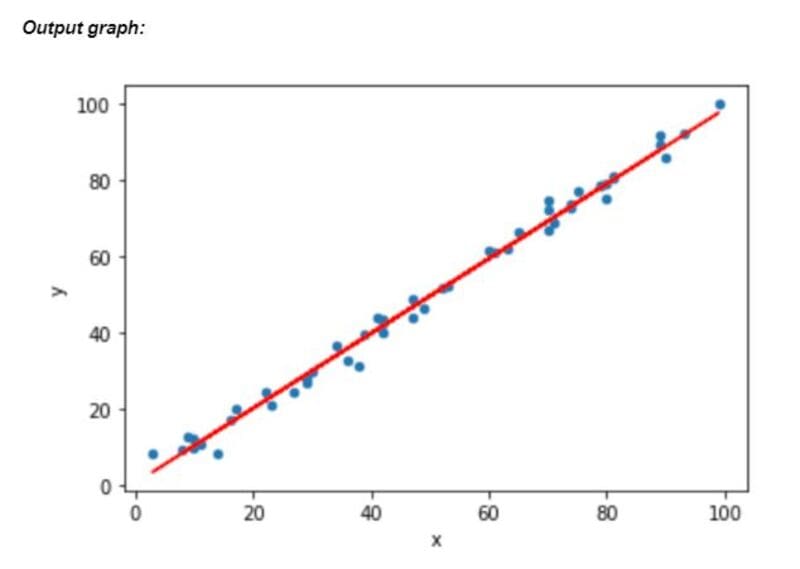
蓝色的点表示我们的数据点,而红色的线是我们的模型所画的最适合的线性回归线。线性模型算法会一直尝试画出最适合的线,以尽可能准确地预测结果。
逻辑回归
与线性回归类似,逻辑回归也是用来预测一个取决于定义的输入变量的输出值,但这两种算法的主要区别是,逻辑回归算法的输出应该是一个分类(离散)变量。
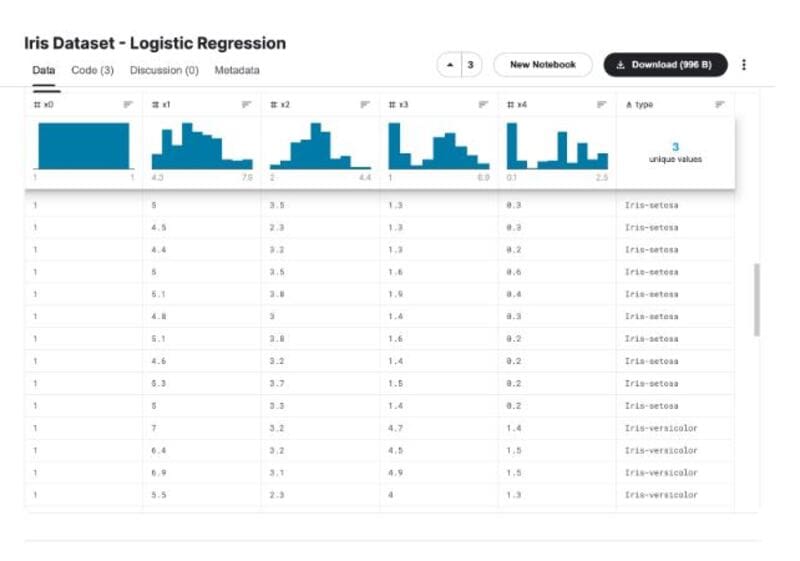
对于我们的Python例子,我们将使用逻辑回归将给定的花朵分为两个不同的类别/物种。我们给定的数据集将包括不同花种的多个特征。
我们的模型的主要目的是将给定的花识别为鸢尾花、鸢尾色或 鸢尾花。
要找到使用的数据集,请查看Kaggle上的 Iris Dataset?-?Logistic Regression。下面是给定数据集的截图。
用Python建立Logistic回归模型的例子
1.导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
2.导入我们的数据集
data = pd.read_csv('../input/iris-dataset-logistic-regression/iris.csv')
3.选择我们的因果和独立值
对于我们的独立值(x),我们将包括所有可用的列,除了类型列。至于我们的依赖值(y),我们将只包括类型列。
X = data[['x0','x1','x2','x3','x4']]
y = data[['type']]
4.分割我们的数据集
我们将把我们的数据集分成两部分,80%用于训练数据集,20%用于测试数据集。
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.2, random_state=1)
5.运行我们的逻辑回归模型
我们将从 linear_model 库中导入整个逻辑回归算法。然后我们可以将我们的X和y训练数据拟合到逻辑模型中。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state = 0)
model.fit(X_train, y_train)
6.评估我们模型的性能
print(lm.score(x_test, y_test))
返回的值是 0.9845128775509371,这表明我们的模型性能很高。
注意,随着测试分数的增加,模型的性能也在增加。
7.绘制我们的图表
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(range(len(X_test)), pred,'o',c='r')
输出图。
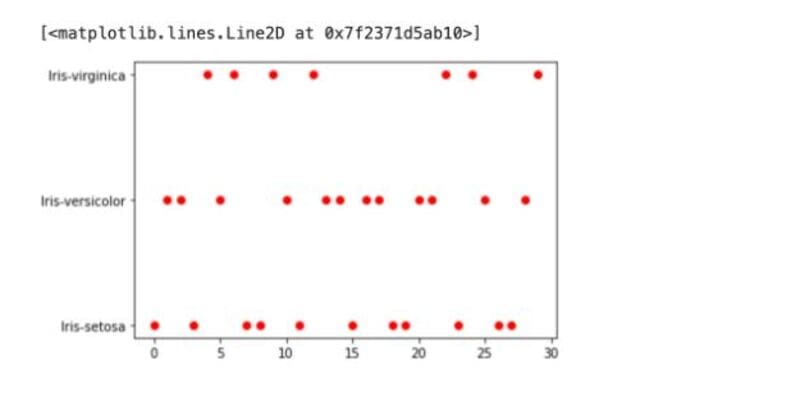
在逻辑图中,红色的点表示我们给定的数据点。这些点被清楚地划分为3个类别,即处女花、多色花和Setosa花种。
使用这种技术,逻辑回归模型可以很容易地根据它在图上的位置对花的种类进行分类。
支持向量机
支持向量机(SVM)算法是另一个著名的监督机器学习模型,由Vladimir Vapnik创建,能够处理分类和回归问题。虽然,它更常用于分类问题而不是回归问题。
SVM算法能够将给定的数据点分割成不同的组。这是通过让我们的算法绘制数据,然后画出最合适的线将数据分成多个类别来实现的。
正如你在下图中所看到的,所画的线完美地将数据集分成了2个不同的组,蓝色和绿色。

SVM模型可以根据绘制的图形的维度来画线或超平面。线条只能适用于二维数据集,即只有两列的数据集。
由于多个特征可能被用来预测给定的数据集,更高的维度将是必要的。在我们的数据集将导致超过2个维度的情况下,支持向量机模型将绘制一个更适合的超平面。
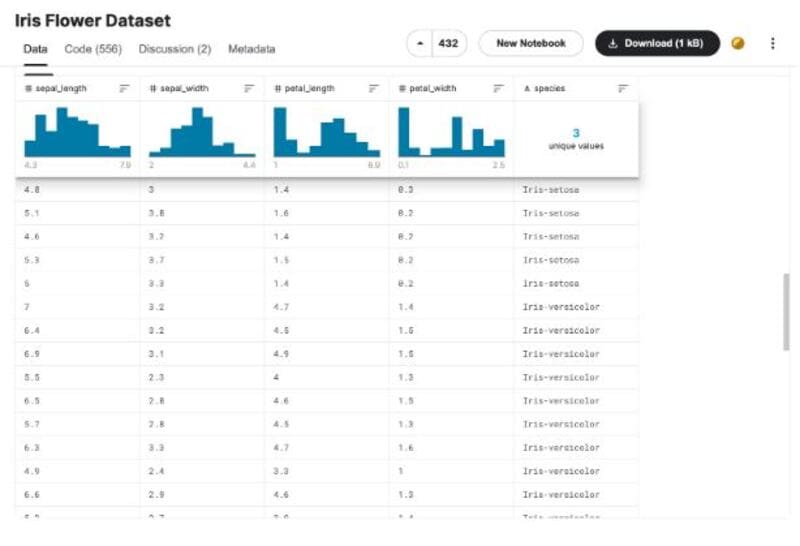
对于我们的支持向量机Python例子,我们将对3种不同的花卉类型进行物种分类。我们的自变量将包括某种花的所有给定特征,而我们的因变量将是该花确实属于的指定物种。
我们的花种包括Iris-setosa, Iris-versicolor, 和Iris-virginica。
要找到所用的数据集,请在Kaggle上查看 鸢尾花数据集。下面是给定数据集的截图。
用Python建立支持向量机模型的例子
1.导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
2.读取给定的数据集
注意,在进行这一步之前,你应该导入给定的数据集。
data = pd.read_csv(‘../input/iris-flower-dataset/IRIS.csv’)
3.将数据列分成因变量和自变量
我们将X值作为自变量,它包含除物种列以外的所有列。
对于我们的因变量,Y变量将只包含我们模型应该预测的物种列。
X = data.drop(‘species’, axis=1)
y = data[‘species’]
4.将数据集分成训练和测试数据集
我们将数据集分成两部分,其中80%的数据放入我们的训练数据集,20%放入测试数据集。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
5.导入SVM并运行模型
我们把支持向量机算法作为一个整体导入。然后,我们使用从以前的步骤中收到的X和Y训练数据集来运行它。
from sklearn.svm import SVC
model = SVC( )
model.fit(X_train, y_train)
6.测试我们模型的性能
model.score(X_test, y_test)
为了评估我们模型的性能,我们将使用得分函数。在这个过程中,我们将把我们在第四步中已经创建的X和Y的测试值输入评分方法。
返回的值是 0.9666666666667表明我们的模型具有很高的性能。
请注意,随着测试分数的增加,模型的性能也在增加。
其他流行的监督机器学习算法
虽然线性、逻辑和SVM算法相当可靠,但我们也会提到一些存在的光荣的监督机器学习算法。
1.决策树
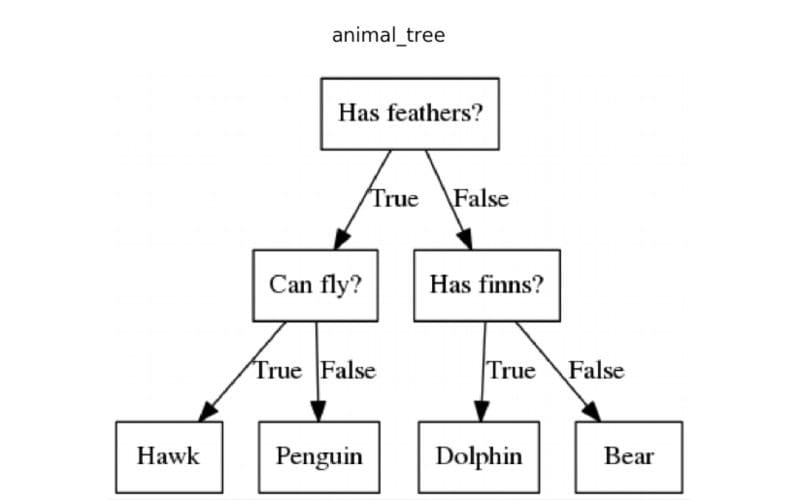
决策树算法是一种监督机器学习模型,利用树状结构进行决策。决策树通常用于分类问题,该模型可以决定数据集中的某个项目属于哪个组。
请注意,所使用的树的格式是倒置的树。
2.随机森林
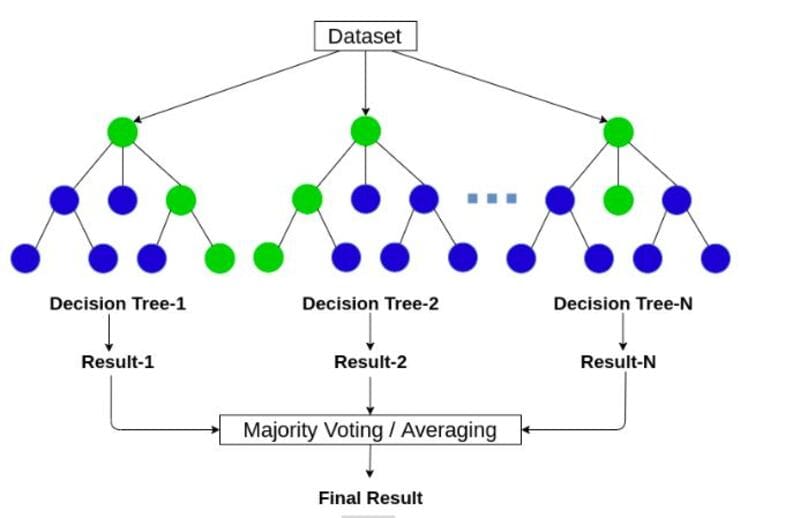
随机森林算法被认为是一种更复杂的算法,它通过构建大量的决策树来达到其最终目标。
意味着同时构建多个决策树,每个决策树都会返回自己的结果,然后将其合并以获得更好的结果。
对于分类问题,随机森林模型会生成多个决策树,并根据大多数树所预测的分类组对给定对象进行分类。
这样一来,该模型就可以修复由一棵树引起的任何过度拟合。随机森林算法也可用于回归,尽管它们可能导致不良的结果。
3.K-最近的邻居
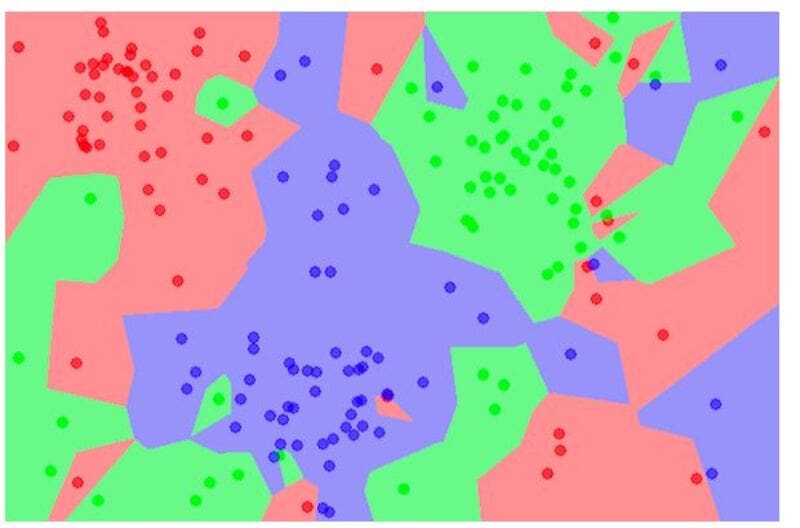
k-近邻(KNN)算法是一种有监督的机器学习方法,它将所有给定的数据分为不同的组。
这种分组是基于不同个体之间共享的共同特征。KNN算法可用于分类和回归问题。
一个KNN问题的例子是将动物图像分类到不同的组中。
总结
为了回顾我们在这篇文章中所学到的知识,我们首先定义了监督机器学习和它所能解决的两类问题。
接着,我们解释了分类和回归问题,并给出了每种问题的一些输出数据类型的例子。
然后我们解释了什么是线性回归,以及它是如何工作的,并在Python中提供了一个具体的例子,试图根据独立的X变量来预测Y值。
我们还解释了一个与线性回归相似的模型,即逻辑回归模型。我们说明了什么是逻辑回归,并给出了一个分类模型的例子,将给定的图片归入给定的花种。
对于我们的最后一种算法,我们有支持向量机算法,我们也用它来预测3种不同花种的给定花种。
在文章的最后,我们简单地解释了其他著名的监督式机器学习算法,如决策树、随机森林和K-近邻算法。
无论你是为了学习、工作还是娱乐而阅读这篇文章,我们认为从这些初级算法开始,可能是开启你新的机器学习激情的好方法。
如果你有兴趣并想了解更多关于机器学习的世界,我们建议你多了解此类算法的工作原理,以及如何调整此类模型以进一步提高其性能。不要忘记,还有大量的其他监督算法供你学习。
