

使用Dagster, Python
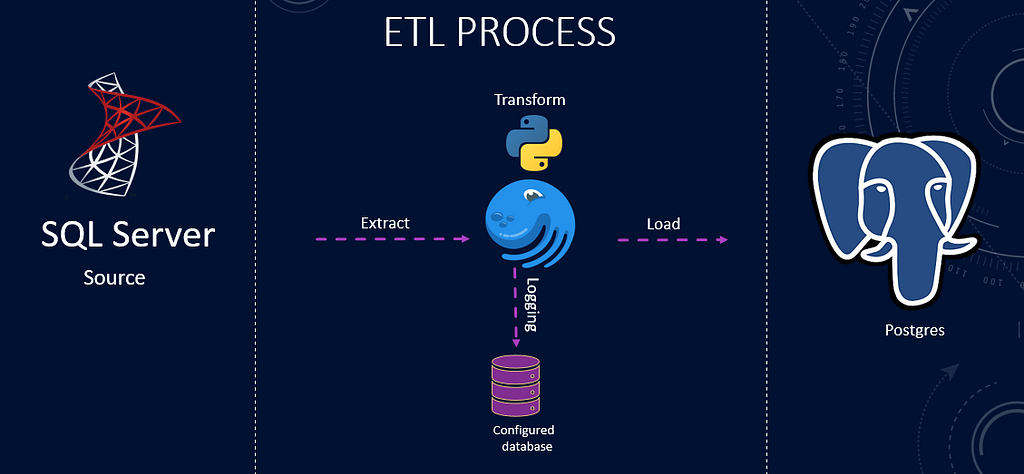
使用Dagster的ETL管道
今天我们将介绍一个令人兴奋的新应用程序,名为Dagster。它用于协调数据管道。在之前的一篇文章中,我们介绍了如何用Airflow自动化你的python脚本。Dagster改进了用户体验,并为我们提供了一个更好的选择,即对我们使用它运行的作业进行记录和记录。开始使用Dagster非常容易。它是一个python库。我们将介绍Dagster的提取、转换和加载(ETL)协调。ETL协调是建立ETL管道的一个常见过程。我们可以将协调定义为组织ETL管道工作流的执行和监控的过程。今天我们将使用Dagster来自动化我们之前使用Airflow开发的Python ETL管道。Dasgter是一个相对较新但直观和强大的工作流协调工具。关于如何用Dagster与Python编码你自己的数据管道的好材料很缺乏。因此,我决定将我们基于Python的数据管道移植到Dagster上,让大家了解一下设置和开发过程。
完整的代码可以在GitHub上找到。代码演练可在YouTube上找到。
Dagster简要介绍
ETL管道具有相互依赖性,它们需要一个系统来管理这些依赖性,按照特定的顺序执行任务,检测和记录错误并产生警报。Dagster通过有向无环图(DAG)为我们提供了ETL管道的概况。它捕获了任务之间的关系和依赖性。每个任务在DAG中按顺序列出,Dagster按照这个顺序执行各自的任务,同时对日志、调试和处理失败和重试进行控制。我们将遵循以DAG表示的ETL管道。
Dagster使我们能够。
- 构建结构良好、可测试的ETL管线
- 按计划运行ETL管线
- 以Python代码的形式创建和管理脚本化的数据管线
- 追踪、监控、管理你的ETL管线
一个DAG代表一组任务。它是用依赖和关系来组织的,说明它们应该如何运行。Dag被定义为一个Python脚本,它将DAG的结构(任务和它们的依赖关系)表现为代码。我们可以按计划运行一个DAG,也可以手动触发它。此外,我们可以从失败中运行一个特定的任务,以节省我们重新运行整个管道的时间。
设置
我们将在一个目录中建立一个虚拟环境,并在这个环境中安装Dagster。
# create a virtual environment
python -m venv env
# activate virtual environment
env\Scripts\activate
# install dagster and dagit
pip install dagster dagit
# install additional libraries
pip install psycopg2
pip install pandas
# create a new project
dagster new-project etl
Dagster是数据协调平台,Dagit是Dagster的基于网络的界面。通过Dagit用户界面,我们可以查看并与Dagster对象进行交互。Dagit默认运行在3000端口,我们可以导航到localhost:3000 来访问Dagit UI*。* Dagster需要一个存储库来存储运行时的细节和日志。默认情况下,它将检查 "DAGSTER_HOME " 环境变量。请确保设置一个系统环境变量。
用Dagster构建ETL管道
我们将重构我们的Python ETL管道脚本,使其与Dagster兼容。除了常规的编程库外,我们将导入Dagster特有的库(out、output、job和op)。然后,我们有一个日志库来记录信息或错误,以运行作业的细节。
让我们定义我们的源和目的数据库连接。我决定把连接移到一个单独的文件 db_con.py中。这有两个功能:第一个返回到SQL Server的连接。而第二个则提供一个与PostgreSQL的连接。我们在顶部导入这个。
源表和提取
我们使用op装饰器来定义我们在Dagster中的任务。这个任务将返回两个输出;df和tbl。我们在装饰器之后用关键字out来定义这个任务。我们定义了输出的名称以及它们是否是必需的。在此之下,我们定义了一个执行提取操作的函数。我们将上下文传递给它。在上下文的帮助下,我们可以在Dagster用户界面中记录信息和错误。首先,我们从日志库中定义一个日志器 的实例。我们将用这个日志器记录错误。然后我们用db_con.py中的 "get_sql_conn() "获取SQL服务器的连接细节。
我们从SQL Server的系统模式中抓取我们想要提取的数据的表。简单地循环浏览这些表并查询它们。通过几行代码,我们查询了源,并获得了作为Pandas数据框架的数据。我们记录信息和错误(如果有的话)。然后,我们用Output返回两个输出。
加载
在 "load_dim_product_category"函数中,我们记录信息和错误。然后我们用 "get_postgres_creds"连接到Postgres。使用这个连接,我们把数据帧写到一个表中。我们将这些数据持久化到Postgres表中。我们调用 "to_sql"函数,并在表名前加上 "stg",以表明这是一个暂存表。我们就完成了加载过程。
工作
我们在一个作业中导入我们上面定义的操作。我们创建一个作业文件 "run_etl.py",并在其中导入etl.py操作。让我们把这个作业称为 "run_etl_job"。在作业 我们设置任务之间的依赖关系,并定义它们的运行顺序。我们运行提取函数并保存返回的输出。我们把这些输出传递给load函数。我们将在用户界面中看到可视化的表示。这就是我们如何用Dagster实现ETL管道的自动化。我们在资源库中导入作业文件,并在repository.py下调用该作业。我们还可以为这个作业导入时间表,并在时间表中排队。
计划表
我们将时间表定义为python代码。这个etl工作时间表在每天早上10点运行该工作。这是一个基于cron的时间表,它接受标准的cron表达式。它也接受@hourly, @daily, @weekly和@monthly表达式。
执行情况
我们可以在Dagit用户界面上查看etl作业。我们可以选择该作业,并显示该作业的DAG。我们在这个作业下有两个运算符。我们可以点击单个运算符或操作,在右边看到它的细节。它告诉我们,它有两个输出和它的平均执行时间。同样地,我们可以看到第二个操作的细节。在launchpad 下,我们可以手动触发作业。所以,我们将触发这个作业并查看其执行情况。

带有作业预览的Dagit用户界面
我们可以在Dagit用户界面上查看etl作业。我们可以选择作业,它显示了作业的DAG。我们在这个作业下有两个操作者。我们可以点击一个单独的操作者或操作,在右边看到它的细节。它告诉我们,它有两个输出和它的平均执行时间。同样地,我们可以看到第二个操作的细节。在launchpad 下,我们可以手动触发作业。因此,我们将触发这个作业并查看其执行情况。

Dagster作业的执行情况
总结
- 我们简要介绍了什么是Dagster以及我们如何利用Dagster实现数据管道的自动化。
- 我们展示了如何创建操作员和作业,并定义每个操作员任务的运行顺序。
- 我们使用Dagster、Python、Pandas和SQLAlchemy实现了一个ETL(提取、转换和加载)管道。
- 完整的代码可以在这里找到
