

数据仓库和数据湖中最常用的数据处理工具是SQL语言。无论是数据加载、数据转换还是数据清洗,都会用到SQL查询语言,更不用说数据查询分析。在数据仓库和数据湖中,数据线在提高企业数据质量方面起着非常重要的作用。你可以参考 这篇文章关于数据世系在企业数据治理中的重要作用。在这篇文章中,我们重点讨论如何在5分钟内用SQL语言发现数据世系。

也就是说,我们将重点讨论如何发现SQL语句中的数据世系,以及哪些SQL语句隐藏了数据世系。如果你想知道公司的数据仓库和数据湖中存在哪些数据脉络,本文将教你在5分钟内通过分析企业中已经存在的SQL语句快速获得数据脉络信息。通过这种方式,你可以进行数据溯源分析,分析如果某个表的字段被修改,哪些系统会受到影响。
本文的分析方法适用于各种数据库的SQL语句,如主流关系型数据库DB2、MySQL、Oracle、PostgreSQL、SQL Server,以及数据仓库系统如Greenplum、HP Hana、Teradata、Vertica等。同时,这些分析方法也适用于基于云的数据湖,如Azure Synapse Analytics, AWS Redshift, Google BigQuery, Snowflake。
在深入了解我们的文章之前,让我们先弄清楚什么是数据线。
1.什么是数据世系?
首先,我们需要知道什么是数据世系,维基百科对它的定义是 这里.如果你想了解数据世系的基本知识,请看以下内容 这里.这里我们只讨论数据库中各个表或视图之间的数据脉络,也就是说,各个表和视图之间的数据是如何关联和流动的。
我们以一个网上商店的数据仓库为例,来解释数据行距是如何产生的。该数据库包含8张表,显示了原始数据的导入、清洗和转换过程。
1.1 外部数据导入表
数据从外部系统进入系统,并在以下三个表中登陆。

1.2 中间表
从上面的落地表到这里的中间表,可以进行数据清洗和其他工作。

1.3 数据仓库模型表
将中间表的数据进行逻辑转换,按照业务需要的格式存储在下面的模型表中,供业务人员查询和分析。

2.数据脉络是如何产生的?
利用不同的SQL语句,可以在数据仓库的不同表中进行数据加载、清洗、转换等工作。随着数据在不同的表和视图之间的移动和转换,数据脉络就这样产生了。
2.1 插入语句
插入语句是用来将数据插入到一个表中。但是普通的插入语句不能产生数据线。

因为数据源都是恒定的,不是来自另一个表。而下面的插入SQL语句将生成数据线段/关联。

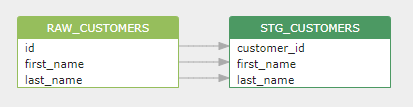
下图是生成的表级数据脉络,表明stg_customers表的数据来自raw_customers表。熟悉SQL语言的人可以一目了然。

下图显示了生成的字段级数据线,表明stg_customers表中的customer_id字段的数据来自于raw_customers表中的id字段。

2.2 创建视图语句
创建视图语句表示创建一个视图,其数据来源于创建视图时指定的底层表。很明显,在底层表和这个视图之间有一个数据线。

由此产生的字段级数据脉络如下。我们可以从创建视图的SQL语句中找到raw_customers表和stg_customers视图之间的数据关联。
同样,数据仓库中常用的CTAS语句(Create Table As Select)也会在源数据表和目标表之间建立数据线关系。
2.3 合并语句
合并语句基于源数据表中的数据,在目标表中插入、更新或删除数据。因此,在源数据表和目标表之间建立了一个数据线关系。

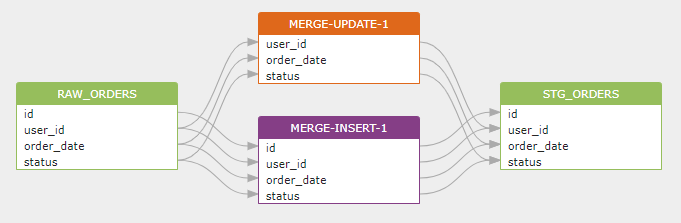
上面的合并语句意味着。如果在stg_orders表中发现与raw_orders表中的id相同的数据记录,那么用raw_orders表中的数据更新stg_orders表中的相应数据。如果没有找到,就在stg_orders表中插入一条新的数据记录,从raw_orders表中找到。
由此产生的数据脉络如下。
2.4 其他SQL语句
上面介绍了SQL语言中一些最常用的产生数据脉络的SQL语句。它们允许数据在不同的表或视图之间流动,从而产生数据线。这些SQL语句一般是DML(数据操作语言),DDL(数据定义语言)。其他SQL语句包括更新、创建外部表、存储过程等。
3.为什么你需要一个能自动发现数据脉络的工具?
通过上面的学习,你已经可以通过阅读SQL语句找到数据脉络,并依靠发现的数据脉络对数据仓库系统做影响分析。但是,在实际业务系统中,通过手动读取SQL语句来发现数据脉络是不现实的,会遇到以下典型问题。
3.1 SQL语句的复杂性
在实际业务系统中应用的SQL语句会非常复杂和冗长,包括多级子查询嵌套,使用CASE表达式进行数据过滤,以及使用存储过程进行复杂的逻辑运算,一般会使用游标和动态语句。仅以2.2中使用的创建视图语句为例。为了在实际业务系统中转换字段名,可以使用以下SQL语句。你能很容易地整理出数据的世系吗?

试着用一个 数据世系分析工具来分析上述SQL语句的数据脉络,你可以在一秒钟之内得到结果。
3.2 需要处理大量的SQL语句
在一个真实的仓库环境中,通常有数百个表和视图,有数千个字段,有数千行甚至更多的SQL代码来加载、清理、转换和分析数据。
而且这些SQL代码会随着商业应用的发展而不断地更新和改变。此时,需要一个能够自动扫描和分析SQL语句的工具来处理企业环境中这些复杂而庞大的SQL代码,准确发现数据脉络。
3.3 需要快速发现数据脉络
以提高竞争力为目的,现代企业普遍采用商业智能、机器学习等系统,充分挖掘和利用企业数据的价值。为了快速响应业务部门的分析需求,数据仓库或数据湖中的数据和结构必须能够快速调整和重构,增加新的数据源,删除不用的旧数据。
在数据仓库数据快速调整和迭代的过程中,需要可靠的元数据管理工具和数据脉络分析工具为数据质量和数据安全保驾护航,并对数据仓库中大量的SQL代码进行分析。快速获取数据世系,无疑具有重要的价值。
3.4 SQL代码中的数据脉络仍然可以在5分钟内搞清楚
尽管存在上述挑战,如果我们有一个工具能够自动扫描和分析SQL代码,并快速准确地输出数据世系,那么我们仍然可以在5分钟内得到企业数据仓库中的SQL代码中包含的数据世系。
Gudu SQLFlow是一个数据脉络分析工具,可以分析多达20种主流数据库SQL语言,并支持复杂的SQL嵌套、存储过程和动态SQL语句。 古都SQLFlow云版本支持开箱即用,不需要安装软件。古都SQLFlow私有部署版(企业内部版本)可以部署在企业内部,直接连接到数据库,自动分析并获取数据库中的数据世系关系,无需担心数据安全问题。
如何在5分钟内发现SQL语言中的数据脉络?原文发表于Dev Geniuson Medium,人们在这里通过强调和回应这个故事来继续对话。
