

在这一系列的统计监督分类技术中,我们将从学习K-Nearest Neighbours分类(也称为KNN)开始。
让我们了解一下这种分类技术的基本原理。首先,我们必须熟悉输入的特征空间,然后再跳到算法的基础知识。
让我们举一个简单的例子,以了解特征空间、距离和算法本身。我们将以一个一维特征向量为例,我们将尝试找到一种方法来对其进行正确分类。
假设我们要对两种不同类型的水果进行分类--假设我们有一台机器对水果的外观视而不见,它只有测量这些水果的重量的能力。假设我们的机器必须区分苹果和猕猴桃--现在基本的逻辑告诉我们,苹果平均比猕猴桃重,所以让我们假设我们已经有一些关于苹果和猕猴桃重量的数据,这将被视为我们的训练数据
猕猴桃的重量(克)= [90, 80, 85, 75, 82, 71, 88, 91, 85, 81
]苹果的重量(克)= [140, 145, 143, 160, 135, 142, 150, 173, 150, 155]
所以我们有10个苹果样本和10个猕猴桃样本作为我们的训练集。
现在,我们将在一个维度上绘图--即,重量

猕猴桃和苹果的权重的一维表示法
正如我们所看到的,左边集群上的点(绿色)代表猕猴桃的权重,右边集群上的点(红色)代表苹果的权重。
现在,假设机器要对一个重量为130克的水果进行分类,那么就会像下图这样表示(测试水果用蓝色标记)。

测试分类的未知水果(蓝色)。
从上图可以看出,我们可以直观地说,这个水果的重量更接近于苹果,因此它应该被归类为苹果。
在这个例子中,我们使用的距离是 - |x -xₜ|其中x是一个新的输入,xₜ是我们要计算其距离的一个点。通常,在实现KNN时,我们使用欧氏距离或马哈拉诺比斯距离,因为它们更通用,可用于不同大小的输入特征向量。[注意 - 欧氏距离 = SQRT( (x -xₜ)² )] 。
KNN算法的简要解释 -
- 加载训练数据(把这些点放在我们的向量空间上)。
- 加载测试向量(把它放在地图上),然后计算每个训练点与测试特征向量点的距离(可以是不同的类型--欧几里得,马哈拉诺比斯,等等)。
- 将距离按升序排列。
- 决定多少个邻居应该决定测试点的类别。KNN中的 "K "代表邻居的数量,所以我们说如果K=3,那么我们将根据与测试向量最接近的前三个点来决定测试向量的类别。这个决定可以是简单的投票(例如--如果2个最近的点属于 "A "类,1个属于 "B "类,那么我们就把它归为A类),也可以是基于加权投票的决定(越接近的点,它的投票权重就越大)。
- 基于K-最接近的邻居,我们对测试向量进行分类,即我们预测它属于某个类别。
现在,回到我们上面的例子,让我们通过KNN算法来对重达130克的水果进行分类。
第1步)已经完成,因为我们已经表示了这些点(不需要计算)。
第2步--我们计算130点与所有其他训练数据点的欧几里得距离。
- 假设我们使用(k=3)作为我们的KNN(3-最近的邻居),我们选择3个最近的邻居,它们是--135g、140g和142g--所有3个最近的邻居都属于 "苹果 "类。
4)因此,我们预测重量为130克的未知水果应该是苹果。
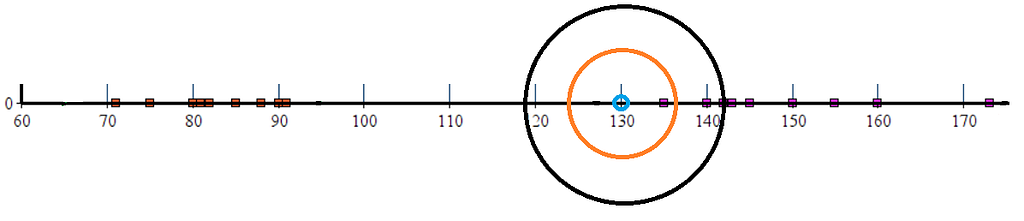
对我们的测试向量的最近邻表示法
现在,我们将加大游戏的力度,为模型增加更多的复杂性。我们将尝试使用二维特征向量和一个标签有点难以区分的数据集。
假设我们的数据是基于两种不同类型的叶子(大叶子和小叶子)的分类,为了更好地区分叶子,我们把它们的长度和重量记录为一个二维向量--(x单位,y单位),其中x单位指叶子的重量,y单位指它的长度。

蓝色=小叶片 "A",红色=大叶片 "B"
增加记录输入数据的维度可以提高我们的分类精度(如下图所示),如果我们只根据重量或高度来记录和做分类,那么我们的模型就不健全,因为如果我们把一些点在x轴和y轴上的投影,可能会出现错误类的点更接近测试向量。

如果只使用一维,有问题的点的投影
所以现在,我们假设我们要测试一片长度和重量为(10个单位,6个单位)的叶子--所以我们表示测试向量为--(10,6)。
然后我们计算测试向量与所有训练点的欧几里得距离,找出与测试向量最接近的邻居。
从下图中,我们看到测试向量(绿色)与红色点(大叶子的特征向量)最接近,而且3个最近的邻居都是 "大叶子",因此我们将测试向量归类/预测为属于 "大叶子 "家族。

测试向量(绿色)更接近于大叶子的特征向量
现在让我们通过使用scikit-learn进行简单的基于python的KNN分类实现。
- 我们得到输入数据,并将训练数据集与测试数据集分开,以检查我们的模型是否能在之前没有训练过的数据中工作--在下面的例子中,我们使用测试数据作为总数据的20%,这意味着总数据的80%将被用作训练数据。
from sklearn.model_selection import train_test_split
# input_data = [<<data : Extracted Feature Vectors>>]
training_data, test_data, training_labels, test_labels = train_test_split(input_data,input_labels,test_size=0.2)
2.2.在得到训练和测试数据后,我们训练我们的分类器(KNN没有训练过程,它只是在特征向量空间中映射输入的训练向量),然后我们使用我们的分类器预测测试数据,如下图所示
from sklearn.neighbors import KNeighborsClassifier
knn_classifier = KNeighborsClassifier(n_neighbors=3)
3.现在,在测试预测完成后,我们将计算出准确率分数和混淆矩阵,如下图所示-- 3.
from sklearn import metrics
accuracy_percentage = 100*metrics.accuracy_score(test_labels, predictions)
# Print out the results
print(" Accuracy percentage is - {}".format(accuracy_percentage))
瞧!我们有了结果
在这篇文章中,我们已经了解了KNN的基本概念,以及如何对这一技术进行基本实现。祝你在学习和实验这些机器学习技术的过程中获得乐趣!
如果你喜欢这篇文章,请留下 "拍手"!
K-近邻分类》最初发表在《Dev Genius》杂志上,人们通过强调和回应这个故事来继续对话。
