

数据的可重复性是任何数据平台的一个关键因素。被称为数据历史化,现在是数据版本化,这是实现它的技术。这篇文章说了关于它的一切。
为了举例说明数据版本化,我想象自己在一家电子商务公司担任数据工程师。为了简单起见,电子商务应用将其数据保存到Postgres数据库中,模型被简化为2张表:用户和订单。

为了购买产品,用户需要创建一个账户并提供个人信息:姓名、地址等。这类信息被保存在一个维度实体(用户),因为它具有描述性和易变性。当用户下订单时,这被称为一个事件,它被保存在一个事件/事实实体()中。订单),因为它具有不可改变的性质。

永远不要将整个地址存储在一个字段中 :)
根据上述数据,我们知道用户demo-user-1已经订购了2个产品,它应该在Street Unknown, no 10的地址收到这些产品。从今天起的一个月内,demo-user-1将改变其地址。我们想到的第一个想法是,我们可以覆盖现有的信息,忘记以前的地址。通过这样做,重要的信息被删除。由于法律要求(审计、合规性、法律诉讼),这种信息需要可以检索,这就是数据版本管理的主要作用。这种要求被称为可重复性,它意味着对某一时间点的查询结果不随时间而改变,即使数据在变化。
什么是变化数据采集?
我们的用户在我们的应用程序中更新了它的地址,我们的数据看起来像。
ecommerce=# select * from ecommerce_user_table;
-[ RECORD 1 ]---+---------------------------
user_id | 1
user_name | demo-user-1
user_address | Street Unknown, No 20
creation_date | 2021-10-23
insert_datetime | 2021-10-23 13:54:02.815599
update_datetime | 2021-11-23 14:24:20.560314
在我们的例子中,电子商务应用程序本身对用户的当前地址感兴趣,以便将产品发送到正确的地址。这就是为什么用户表中的记录被覆盖的原因。更新地址的事件产生了数据的变化,通过变化数据捕获,我们能够在电子商务公司的数据平台上记录这些变化。
- 要么我们在不同的表中存储所有以前的用户版本(历史方法)。
ecommerce=# select * from ecommerce_user_table_hist ;
-[ RECORD 1 ]---+---------------------------
user_id | 1
user_name | demo-user-1
user_address | Street Unknown, No 10
creation_date | 2021-10-23
insert_datetime | 2021-10-23 13:54:02.815599
update_datetime | 2021-10-23 13:54:02.815599
- 或者将事件与改变的内容一起记录下来(事件方法*)。
{
"event_timestamp": "2021-10-23 13:54:02.815599",
"event_type": "insert",
"user_id": 1,
"user_name": "demo-user-1",
"user_address": "Street Unknown, No 10",
"creation_date": "2021-10-23"
},
{
"event_timestamp": "2021-11-23 14:24:20.560314",
"event_type": "update",
"user_id": 1,
"user_name": "demo-user-1",
"user_address": "Street Unknown, No 20",
"creation_date": "2021-10-23"
}

通过CDC,我们能够记录跨时间的变化
现在我们知道了什么是变化数据采集,那么什么是数据版本管理呢?它无非是以一种可以轻松查询的方式来存储数据的版本的技术。
数据版本管理,Kimball方法
最常见的数据版本管理方法是缓慢变化的维度(SCD)方法,由Kimball在他的The DataWarehouse Toolkit中实施。SCD大约有7种类型,但我将展示SCD类型6的方法。

valid_to_date可以默认为远期的一个日期
对于每条新的不同的记录,都会根据唯一的自然键--本例中是user_id--建立一个有效间隔。每条记录都有一个user_key,它是一个由自然键和变更日期生成的代理键。

用user_key检索订单日期的版本,用user_id检索任何版本。
数据版本管理,功能性方法
存储是很便宜的,自从Hive元存储被引入数据领域后,围绕着数据工程的功能范式被创造出来。考虑到这一点,我们不需要投资创建复杂的ETL就能重现某个版本。我们可以简单地创建一个用户的日常版本。
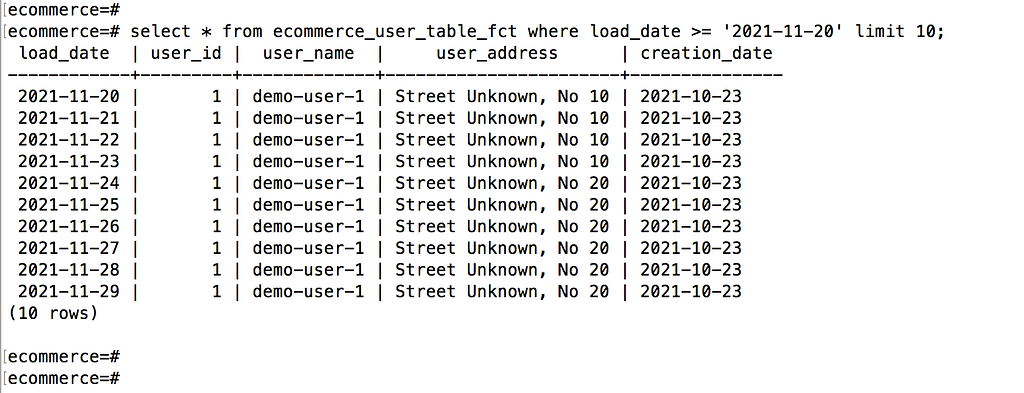
只是一个例子。
我确实认为这种方法不够有效,如果我想到。
- 需要回答是否有什么变化(需要复杂的查询)。
- 非每日频率的加载:更高的频率会使数据重复得更多,更低的频率会产生人为的数据
- 增量加载:如果数据在输入时是增量的,则需要创建人工数据,以便为某一时刻创建快照。
数据版本化,事件方法
从CDC章节中,我们知道我们可以用事件来做CDC。这些事件可以存储在数据库中,也可以存储在文件中,并通过窗口函数进行查询。

通过窗口函数,我们可以检索出某一时刻的某个版本。
如果我们仔细观察数据,就会发现用窗口函数我们可以生成SCD的时间间隔。

事实表将只包含user_id,额外的过滤器将被应用在有效期间隔上。
虽然事件方法减少了实现SCD复杂ETL的需要,但有2个相关点需要考虑。
- 如果事件是在不感兴趣的属性上产生的,可能会产生一个与之前类似的版本。
- 窗口函数的计算量很大,仍然建议在ETL作业中处理它们。
在这篇文章中,我总结了什么是数据版本管理,变化数据捕获在其中的作用以及如何实现它。根据数据量和数据平台的底层技术,3种方式中的任何一种都可能是最佳选择。
笔记。
- CDC,事件方式。Kafka使之成为可能。你可以在列级流变化事件,并创建你独特的数据视图。
{
"event_timestamp": "2021-10-23 13:54:02.815599",
"table": "ecommerce_user_table",
"column": "user_address",
"table_record_id": "{'user_id': 1}",
"before": "Street Unknown, No 10",
"after": "Street Unknown, No 20"
}
- 虽然在某些情况下,变化行为可能是分析产品的一个关键因素,但我还没有遇到过这样的项目,它比你的系统产生和整合这种事件的压力(和成本)更重要。
- 现在,你可能知道,我是docker的超级粉丝。这就是你如何用docker-compose运行postgres。
version: '3'
services:
postgres_db:
image: postgres:14.0
environment:
POSTGRES_PASSWORD: ???
POSTGRES_DB: ecommerce
POSTGRES_USER: ecommerce_user
privileged: true
ports:
- 5433:5432
networks:
- app-tier
volumes:
- ./postgres:/docker-entrypoint-initdb.d
networks:
app-tier:
driver: bridge
petra1$ docker-compose up
demo-postgres-python_postgres_db_1 is up-to-date
Attaching to demo-postgres-python_postgres_db_1
postgres_db_1 | The files belonging to this database system will be owned by user "postgres".
postgres_db_1 | This user must also own the server process.
postgres_db_1 |
postgres_db_1 | The database cluster will be initialized with locale "en_US.utf8".
postgres_db_1 | The default database encoding has accordingly been set to "UTF8".
petra1$ docker ps
CONTAINER ID IMAGE COMMAND
....
10009cb5e923 postgres:14.0 "docker-entrypoint.s…"
petra1$ docker exec -it 10009cb5e923 psql ecommerce -U ecommerce_user
psql (14.0 (Debian 14.0-1.pgdg110+1))
Type "help" for help.
ecommerce=#
