


Nutch Apache简介
Nutch Apache是一个流行的网络爬虫软件,用于从网络上分离信息。它与其他Apache工具如Hadoop结合使用,以进行更好的数据分析。它是一个开源的产品,拥有Apache软件的许可证。因此,开发者社区拥有Apache中各种工具的许可证,以对数据进行分类和分析。与其他工具一起,Apache Hadoop也有同样的功能,通过使用网络爬行的算法来存储、分析、收集网络上的文件。本文对Apache Nutch的简单安装、操作系统和功能进行了解释。
什么是Nutch Apache?
Nutch Apache用于通过使用网络爬行算法从网络中分离出数据。它是一个开源工具,在Apache Solr框架上工作,该框架作为Apache Nutch中收集的信息的存储库。Nutch最适合对较高维度的数据进行批量处理,它可以被整合到较小的工作中。Nutch还提供了强大的插件,可以解析到Apache Tika、Elasticsearch和Apache Solr。Apache Nutch提供了一个直观的、可扩展的、稳定的界面,用于盛行的功能,如评分、索引、HTML过滤和解析,以进行一些定制的实现。用户可以通过在Apache Nutch中运行简单的命令来获取URL下的数据而获得优势。
如何安装Nutch apache?
最初的步骤是建立和下载插件软件和Nutch Apache:
- 使用GitHub,克隆索引插件的仓库。
- 从索引插件中选择首选版本
- 使用$ mvn包构建索引插件
- 然后在下载索引插件后,它执行了多个测试。所以跳过测试,选择mvn包-Dskip测试。
安装Apache Nutch 1.15版本,按照Apache Nutch手册中给出的安装步骤。
然后提取目标文件到复制插件的文件夹中
然后对插件的索引进行处理
- 首先,要配置索引插件,建立一个名为plugin的文件。Config.properties
- 配置文件应该显示在谷歌云搜索的数据源上工作所必须的参数。
- 配置文件可以包括其他参数,以管理索引插件,使该插件知道将信息推送到云搜索。用户也可以通过使用API、批处理*和默认ACL*来配置索引插件,以填充元数据和结构化数据。
Apache Nutch配置
在conf/nutch.xml文件中添加参数。该插件应包括文本文件,其中应包含index-basic、index-google cloud search和index-more。但conf/nutch.xml为这个属性提供了标准值,但要由用户手动将index- google - cloud search加入其中。元标签名称也可以以文本的形式给出。用逗号将列表分开,其属性被映射到数据源,数据源有相应的模式。
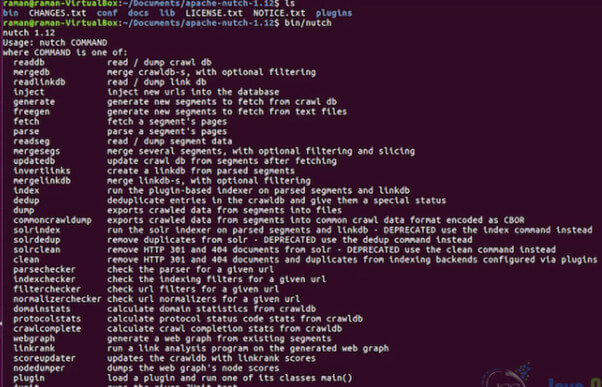
然后要配置网络抓取,将以下属性添加到XML文件conf\index-writers.XML中。
在启动网络抓取配置之前,应该持有企业希望显示可用标准的数据,作为搜索窗口的结果。
启动一个Apache Nutch开始抓取内容的URL。这个URL被定义为启动URL,网络抓取过程在这里到达所有需要包含在抓取链接中的内容。开始URL对于目录安装是强制性的。
- 要从工作目录中改变Nutch的安装目录,给$cd ~/Nutch/apache-Nutch-x/
- 然后建立一个目录到URL。$mkdir URL
- 建立一个种子文件并列出URL。然后继续用URL的规则来管理抓取,在谷歌云搜索的索引中进行反馈。只有这里提到的URL会遵循规则来抓取和索引。如果URL不遵循抓取模式,那么网络爬虫就会停止运作。
- 然后从当前工作目录改到nutch目录。
- 然后编辑配置文件,把文件改成遵循网络爬行的规则。
- $nano.conf/urlfilter
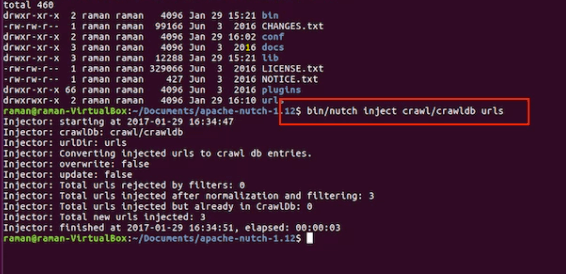
提供带"-"或 "+"的正则表达式,以遵循URL的抓取模式,有时通过编辑抓取脚本启用开放式表达式。如果GCS.upload参数设置为raw,则会添加二进制内容以传递nutch索引的命令。该参数应传递Nutch索引,以便在调用插件时包含二进制内容。抓取的.bin脚本没有任何默认参数。
Nutch apache操作系统
Nutch Apache有一个灵活有效的操作系统,具有多功能性。所以在安装完插件后,可以将索引从脚本中执行到本地模式,在个别nutch命令中运行抓取作业。所需的组件被放置在本地目录下执行Nutch,它的执行目录是apache-Nutch-1.15。冗长的日志文件和输出日志被保存在edit/log4j中。属性。它具有高度的可扩展性,并且有丰富的爬行选项。它遵从配置XML文件中提供的robots.txt规则。被执行的Nutch在集群中持有100台机器,具有可扩展性和稳健性。偏向选项被设置为首先在重要内容上抓取。
Nutch Apache的例子
爬行信息知道从爬行数据库中获取数据的URL。
在链接数据库中,已知链接的URL是由源链接和锚链接组成的,以便在网络抓取内容上工作。
它在一个段的阵列中工作。段由一个有限的URL组成,它被作为一个单元计算。这些段可以用子目录来定义。
- 需要抓取的URL集在crawl_generate中给出。
- 抓取的状态在crawl_fetch中给出。
- 从每个URL中获取的原始内容被放置在内容文件夹中。
- 带有解析文本的URL位于parse_text中。
- 经过解析的元数据和外部链接位于parse_data中。
总结
因此,我们了解了Nutch Apache的工作、安装和属性,用户可以根据自己的内容要求和业务偏好来配置网络抓取属性。
