


大家好!在这篇文章中,我们将了解Kafka Connect的旅程。我们将尝试了解它的架构和内部情况。
我们已经看到,Kafka Connect是一个可插拔的组件,它可以帮助将数据送入或送出Kafka,从而提供灵活的集成管道。它本身具有容错性和神圣性。要使用任何软件组件并获得最大的收益,我们应该了解它的基础架构和组件。

Kafka连接的概念
在讨论Kafka Connect的内部运作之前,了解几个主要的概念是很重要的。
连接器。顾名思义,他们负责Kafka Connect和外部系统之间的互动,并与之集成。它可以被定义为高层抽象,通过管理任务来协调数据流。连接器实例是一个逻辑工作,负责管理Kafka和另一个系统之间的数据复制。所有实现或被连接器使用的类都被定义在一个连接器插件中。
连接器的作用是有限的,它作为与Kafka Connect的接口,通过传递或接收数据到Kafka Connect的下一个组件。他们有不同的配置属性,具体到与之集成的技术。下面是连接Elastic Search的水槽连接器配置
CREATE SINK CONNECTOR sink-elastic-01 WITH (
'connector.class' = 'io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
'topics' = 'orders',
'connection.url' = 'http://elasticsearch:9200',
'type.name' = '_doc',
'key.ignore' = 'false',
'schema.ignore' = 'true'
);
这就是我们需要做的与Kafka Connect的连接,其余的将由连接器来处理。
任务。在Connect的数据模型中,任务是主要的组成部分。每个连接器实例负责协调一系列复制数据的任务。Kafka Connect通过允许连接器将单个任务划分为若干个任务,为并行和可扩展的数据复制提供了内置支持,只需很少的配置。这些任务中没有存储状态。相关的连接器管理着任务的状态,这些状态存储在Kafka的特殊主题config.storage.topic和status.storage.topic中。因此,任务可以在任何时候启动、暂停或重新启动,从而形成一个可扩展的、有弹性的数据管道。
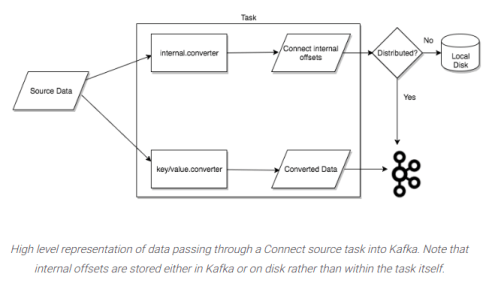
图片提供。Confluent
工人。连接器和任务是逻辑工作单元,必须安排执行一个进程。这些进程在Kafka Connect中被称为工作者,有两种工作者:独立式和分布式。
单机模式是最简单的模式,一个单一的进程负责执行所有的连接器和任务。由于它是一个单一的进程,它需要最小的配置。它在开始时、在开发过程中以及在某些只有一个进程有意义的情况下很方便,例如从主机上收集日志。然而,由于只有一个进程,它的功能也比较有限:可扩展性仅限于单个进程,除了你添加到单个进程的任何监控之外,没有容错功能。
分布式模式为Kafka Connect提供了可扩展性和自动容错。在分布式模式下,你使用相同的group.id ,启动许多工作者进程,他们会自动协调,在所有可用的工作者中安排连接器和任务的执行。如果你增加了一个工作者,关闭了一个工作者,或者一个工作者意外地失败了,其余的工作者会检测到这一点,并自动协调,在更新的可用工作者集合中重新分配连接器和任务。与消费者组的再平衡类似。掩耳盗铃,connect工作者正在使用消费者组来协调和重新平衡。

转换者:连接器实际上并不从Kafka主题中写入或读取数据。这个责任是由转换者承担的。他们负责Kafka Connect和Kafka本身之间流动的数据的序列化或反序列化。转换器与连接器断开连接,这样它们就可以在连接器之间自然地重复使用。例如,JDBC源连接器可以将Avro数据发布到Kafka,HDFS水槽连接器可以使用相同的Avro转换器从Kafka检索Avro数据。这意味着,即使JDBC源提供的ResultSet最后被保存到HDFS的parquet文件,也可以利用相同的转换器。
通常转换器使用Avro、ProtoBuf或JSON模式作为Serde方法,但Kafka真的不关心如何进行序列化/反序列化,因为对Kafka来说,它最终是字节!但是,很高兴有一个Avro转换器。但是,有一个使用模式的序列化方法是很好的,可以确保我们的系统中有结构化的数据。为了让Kafka Connect部署在写入或读出Kafka时支持特定的数据格式,转换器是必要的。任务使用转换器来改变数据的格式,从字节到Connect的内部数据格式,反之亦然。
单一消息转换:Kafka Connect中的第三个但也是可选的组件是单消息转换。转换可以在连接器中指定,以便对单个消息进行简单和轻量级的改变。多个转换可以在连接配置中链接在一起,这对小的数据修改和事件路由很有用。
一个转换是一个基本的函数,它将一条记录作为输入,并返回一个改变后的版本。Kafka Connect的转换都是进行简单但经常需要的修改。值得注意的是,你可以利用转换接口来创建自己的自定义逻辑,将其打包成Kafka Connect插件,并将其用于任何连接。
当Kafka Connect使用源连接器的转换时,连接器创建的每个源记录都会被传递到第一个转换中,该转换会修改它并输出一个新的源记录。链中的下一个转换会接收这个更新的源记录并创建一个新的修改过的源记录。这个过程在其余的转换中重复进行。最终修改后的源记录的二进制版本被转换并写入Kafka。
水槽连接器也可以与转换一起使用。Kafka Connect接收Kafka消息,并将它们的二进制表示法翻译成sink记录。如果存在转换,Kafka Connect会将记录发送给第一个转换,该转换会对其进行修改并返回一个新的、更新的sink记录。新的汇入点记录是通过将更新的汇入点记录传递给链中的下一个转换来创建的。这个过程在其余的转换中重复进行,之后,最终修改的汇入点记录被发送到汇入点连接器进行处理。
死信队列:异常和错误是任何处理数据的软件的一部分。可能发生的情况是,我们从外部系统收到一个无效的记录。DLQ的引入是为了优雅地处理这种情况。它们只适用于sink连接器,因为在源连接器的情况下,无效的消息永远不会被允许进入Kafka系统,因为连接器会立即失败。
有一个错误处理功能,它将把所有无效的记录发送到一个特殊的主题并报告错误。这个主题包含了一个无法被水槽连接器处理的记录的死信队列,错误的处理基于连接器的配置属性 errors.tolerance.
errors.tolerance = all
errors.deadletterqueue.topic.name = <dead-letter-topic-name>
当errors.tolerance 被设置为none ,错误或无效的记录会导致连接器任务立即失败,连接器进入失败状态。而当errors.tolerance 被设置为all ,所有的错误或无效记录都会被忽略并继续处理。没有错误被写入Connect Worker的日志。
当我们使用启用了安全功能的Confluent Platform时,Confluent PlatformAdmin Client会创建死信队列主题。无效的记录首先被传递给一个内部构建的生产者来发送这些记录。然后,管理员客户端创建死信队列主题。为了使死信队列在安全的Confluent Platform环境中工作,必须在Connect Worker配置中添加额外的Admin Client配置属性(前缀为.admin )。
admin.ssl.endpoint.identification.algorithm=https
admin.sasl.mechanism=PLAIN
admin.security.protocol=SASL_SSL
admin.request.timeout.ms=20000
admin.retry.backoff.ms=500
admin.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="<user>" \
password="<secret>";
总结
Kafka Connect提供了容错性和可扩展性等出众的功能。我们已经看到了多个组件如何协同工作以提供一个强大的系统,帮助将外部系统与Kafka集成。
