

Kafka再平衡简介
Kafka再平衡的定义是,它是一个将每个分区描述为准确的客户的过程,因为客户组是客户的集合,它可以将来自一个客户或Kafka主题中的不同客户的消息压倒在一起,当我们有一个新的客户可以被添加到客户组或从组中离开时,Kafka再平衡可以发生,其中客户也可以在一定时间内结束消息的过滤,然后从一个主题中慢慢过滤一个事件。
什么是Kafka再平衡?
我们知道Kafka集群包含一个或多个 "经纪人","生产者 "可以从Kafka经纪人那里获得数据,然后 "消费者 "可以是解释来自经纪人的消息的应用程序,要传达的数据可以存储在主题中,每个主题可以有各种 "分区",一个消费者可以在同一时间解释一个分区。
我们可以说,Kafka再平衡是以特定的方式将分区交给消费者的过程,当再平衡进行时,一个分区可以以递增的方式交给消费者,让我们在下图的帮助下理解它。
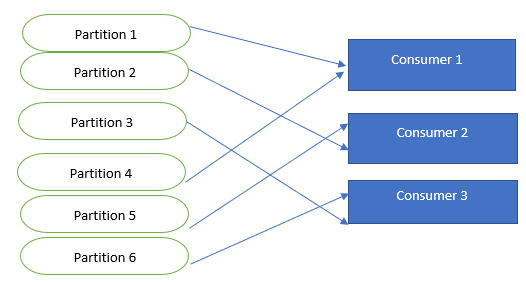
从上图中,我们可以看到分区的分配情况。
- Kafka再平衡领域:
Apache Kafka是一个著名的分散甚至流动的平台,可以利用它来进行数据管道、流动分析和数据组合,那么我们就能够发现问题,总结出容量,也是平衡的。
有一些Kafka再平衡的关键领域,在下面给出。
- 主题。一个Kafka集群,可以管理储备的类别,这就是所谓的Topic。
- 经纪人。一个可以包含多个服务器的集群就是brokers。
- 分区日志。每个主题都可以支持分区日志。
- 一个主题可以包含各种分区,所有的分区都可以作为主要的并行性来执行。
- 复制(Replicas)。它可以是可以复制每个分区的日志的经纪商列表。
Kafka重新平衡过程

第一步:创建原始文件。
它包含两个部分。
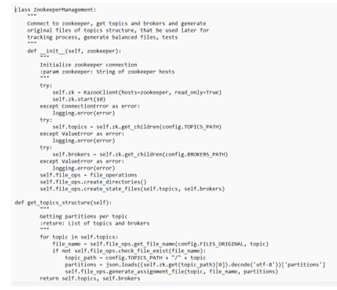
- 通过Zookeeper,它可以获得每个主题的当前经纪人、主题和分区。
- 对于每个主题,最初创建的文件已经被分配。
而原始文件可以被分配。
- 沟通集群调查的情况,如果有任何干扰,所以在这种情况下,我们不需要开始它。
- 我们可以在一段时间后有真实的分配来测试它。
第2步:收集数据以计算再平衡
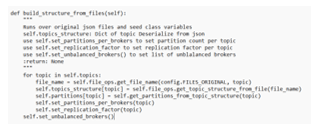
在这个步骤中。
- 可以在文件中考虑主题。
- 每个主题的分区。
- 还有每个经纪人的分区。
- 然后是每个主题的复制因子。
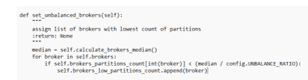
之后,我们可以把不平衡的经纪商放在一起,我们可以把它作为中位数分区的一半加起来,不平衡的相关性必须放在较低的位置,以便调节再平衡。
第三步:管理主题和分区并生成迁移文件。
在这一步中,当我们试图计算一些任务时,可以在主题上进行循环,如下图所示。
- 每个主题要改变的分区的数量。
- 经纪人能够为升级重新平衡的主题降低和总结。
- 此外,它还可以计算膨胀的和下面的经纪商。
- 为了创建一个新的平衡分配文件,在经纪人中进行最小的修改,所以让我们看看如何计算每个主题的分区。

- 我们能够实现一个特定的主题,以减少任何由替换计数产生的修改,也可以进入下一个主题。

- 搜索和替换过程可以寻找具有最高经纪人计数的分区。

第4步:流式测试
在这一步的确认中,我们可以测试一些东西,如下所示。
- Test_changes_in_assignment。它可以检查在真正的主题平衡下的分区中是否有进一步的修改。
- Test_if_topics_are_balanced:它可以检查与分区的中位数相比,是否有超过15%的任何类型的差异。
- Check_brokers_to_reduce:它可以测试经纪商是否是完整经纪商列表的子集。
Kafka rebalance消费者
Kafka rebalance中的消费者是一个可以从主题中解读信息并采取行动的过程,其中一个主题可能带有各种分区,可以被经纪人接纳,一个消费者组可能有各种消费者,他们不能吸收相同的信息,如果在一个案例中,类似的信息已经被多个消费者吸收,那么就必须在不同的消费者组中。我们可以说,消费者的数量和分区的数量之间可能存在紧凑的关系,但如果我们有较少的消费者,那么消费者可能不得不从不同的分区解释,这可能会影响输出,每个消费者可以只了解他的分配,组的领导者也可以是消费者,它可以跟随组中的其他消费者和他们的分配,这意味着新的消费者可以执行一些任务,其中每个分区也可以有平衡的保留痴迷的消息指数。
总结
在这篇文章中,我们总结了Kafka再平衡是在一定时间内过滤消息的过程,我们还讨论了Kafka再平衡领域、Kafka再平衡过程和Kafka再平衡的消费者,所以这篇文章将有助于理解Kafka再平衡的概念。
