


PyTorch参数的介绍
PyTorch参数是一个由nn或模块组成的层。在自定义模型内部被分配为属性的参数被注册为模型参数,因此会被调用者model.parameters()返回。我们可以说,参数是对形成的变量的一种包装。
什么是PyTorch参数?
当与模块一起使用时,参数是具有独特属性的张量子类:当作为模块属性被赋予时,它们会立即被放到组件的参数列表中。PyTorch的Tensor在本质上与NumPy数组相似:Tensor是一个n维数组,PyTorch包括几种处理它们的方法。
如何使用PyTorch参数?
每次我们建立一个模型时,我们都会包含一些层,作为改变我们数据的元素。因此,当我们生成模型的概述时,我们可以看到模型的设置。然而,有些情况下,我们需要张量作为模块中的参数。例如,RNN的可学习初始状态,做神经风格转移时的输入图像张量,以及现在甚至是一个层的连接权重,仅举几个例子。这是不可能用张量(因为缺乏梯度)或变量(因为它们不是模块参数)进行的。参数关键字被用来完成这个任务。
我使用下面的声明作为模块参数。
class Parameter(torch.Tensor):
参数如下: class:`~torch.张量的子类,当与张量结合时具有独特的特性 一旦它们被指定为组件属性,它们就会立即包含在模块的参数列表中。
在设计神经网络时,我们通常会考虑分层计算,其中一些层次有可学习的参数,在学习过程中会被调整。PyTorch中的nn包也做了同样的事情。nn包指定了模块的数量,这些模块与神经网络的层级相当相似。
weight = torch.nn.Parameter(torch.FloatTensor(3,3))
前面的语句演示了如何用nn.Parameter()构建一个模块参数。我们可以看到,权重是用指定的张量形成的,这意味着权重的初始化值应该与张量炬相同。FloatTensor(3,3)。
PyTorch函数中的参数
__init__和forward是创建模型时必须使用的两个主要函数。我们所有的参数层都是在__init__中实例化的。
PyTorch有几个典型的损失函数,你可以在Torch中使用。
loss_fn = nn.CrossEntropyLoss()
ls = loss_fn(out, target)
每次迭代需要修改的模型参数在这里传递。也可以指定更复杂的方法,如每层甚至每个参数的训练率。在用loss.backward()计算梯度后调用optimizer.step(),会按照优化算法的规定修改数值。
对于SGD优化器
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
对于ADAM
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001
让我们来看看apply(fn)
迭代实现fn到所有子模块(如由.children()返回)和自我。
@torch.no_grad()
def init_weights(k):
print(k)
if type(k) == nn.Linear:
k.weight.fill_(1.2)
print(k.weight)
net = nn.Sequential(nn.Linear(3, 3), nn.Linear(3, 3))
net.apply(init_weights)
Linear(in_features=3, out_features=3, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=3, out_features=3, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=3, out_features=3, bias=True)
(1): Linear(in_features=3, out_features=3, bias=True)
)
Sequential(
(0): Linear(in_features=3, out_features=3, bias=True)
(1): Linear(in_features=3, out_features=3, bias=True)
)
示例代码:
def __set_readout(self, readout_def, args):
self.r_definition = readout_def.lower()
self.r_function = {
'duvenaud': self.r_duvenaud,
'ggnn': self.r_ggnn,
'intnet': self.r_intnet,
'mpnn': self.r_mpnn
}.get(self.r_definition, None)
if self.r_function is None:
print('Alert : Read function is not done correctly\n\tIncorrect definition ' + readout_def)
quit()
init_parameters = {
'duvenaud': self.init_duvenaud,
'ggnn': self.init_ggnn,
'intnet': self.init_intnet,
'mpnn': self.init_mpnn
}.get(self.r_definition, lambda x: (nn.ParameterList([]), nn.ModuleList([]), {}))
self.learn_args, self.learn_modules, self.args = init_parameters(args)
PyTorch参数模型
模型。参数()用于迭代检索所有的参数,因此可以传递给优化器。虽然PyTorch没有确定参数的函数,但可以添加每个参数类别的项目数量。
Pytorch_total_params=sum(p.nume1) for p in model.parameters())
模型。命名的参数()提供一个迭代器,其中包括参数标签和参数。
让我们看看这里的参数的示例代码
from prettytable import PrettyTable
def count_parameters(model):
table = PrettyTable(["Mod name", "Parameters Listed"])
t_params = 0
for name, parameter in model.named_parameters():
if not parameter.requires_grad: continue
param = parameter.numel()
table.add_row([name, param])
t_params+=param
print(table)
print(f"Sum of trained paramters: {t_params}")
return t_params
count_parameters(net)
输出会是这样的。
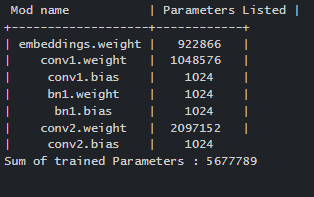
总结一下,nn.Parameter()接受提供给它的张量,不进行任何初步处理,包括统一化。这意味着如果交来的张量是空的或未初始化的,那么参数将是空的或未初始化的。
class net(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Linear(11,4)
def forward(self, y):
return self.linear(y)
myNet = net()
print(list(myNet.parameters()))
例子#2
在这幅图中,nn包被用来创建我们的两层网络。
在这里,每个线性模块都使用一个线性函数从输入中产生结果,并为连接权重保留内部因子。 由于每个模块的参数都保存在一个要求grad=True的可变因子中,这个调用将生成所有可训练模型参数的梯度。
import torch
from torch.autograd import Variable
N, D_in, H, D_out = 64, 1000, 100, 10
a = Variable(torch.randn(N, D_in))
b = Variable(torch.randn(N, D_out), requires_grad=False)
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
loss_fn = torch.nn.MSELoss(size_average=False)
learning_rate = 1e-4
for te in range(500):
b_pred = model(a)
loss = loss_fn(b_pred, b)
print(te, loss.data[0])
model.zero_grad()
loss.backward()
for param in model.parameters():
param.data -= learning_rate * param.grad.data
高级
我们可以创建几种类型的图,而不需要改变我们的模块类规范;因此,我们可以把层次的数量作为输入。我们可以制作一个模块列表,之后将其与火炬一起包起来。我们可以使用nn.ModuleList或者写一个参数列表并将其包裹在火炬中。参数列表。
下面的代码使用一个参数列表给出了两个不同的优化器。
opt1 = torch.optim.SGD([param for param in model.parameters() if param.requires_grad], lr=0.01, momentum=0.9)
optim2 = torch.optim.SGD([
{'params': model.col2.parameters(), 'lr': 0.0001, 'momentum': 0},
{'params': model.lin1.parameters()},
{'params': model.lin2.parameters()}
], lr=0.01, momentum=0.9)
结语
因此,这就结束了PyTorch参数的概念。虽然大多数用户会使用Pytorch来开发神经网络,但该框架的灵活性使其具有难以置信的适应性。
