

潘达斯量化指标简介
Pandas quantile()的工作是在给定的四分位数上返回 esteems,即 numpy.percentile。在每一个变量的估计安排中,都会将一个递归的拨款隔离成相等的群组,每个群组都包含所有人口的类似部分。
Python是一种用于进行信息调查的不可思议的语言,主要是由于信息驱动的Python捆绑程序的惊人的生物系统。Pandas就是其中之一,它使信息的引入和分解变得更加简单。
语法和参数。
Pandas.dataframe.quantile(axis=0,q=0.5, interpolation=’linear’,numeric_only=True)
其中
axis代表行和列。如果axis=0,它代表行,如果axis=1,那么它代表列。
q代表四分位数。它总是0.5,也就是50%。所以,如果四分位值大于0,小于1,那么四分位值将被实现。
numeric_only代表所有必须分配的数字值,以获得数据的实现。如果是False,日期时间和时间Δ信息的四分位数也将被注册。
默认情况下,插值总是被分配为线性。
它返回q是一个数组,将返回一个DataFrame,其中文件是q,各部分是简单的分段,质量是量值。如果q是浮动的,将返回一个系列,其中的记录是简单的分段,质量是量值。
Quantile()函数是如何在Pandas中工作的?
现在我们来看看quantile()函数在Pandas中如何工作的各种例子。
例子#1
使用quantile()函数来实现轴的结果
import pandas as pd
df = pd.DataFrame({"S":[2, 4, 6, 8, 10],
"P":[1, 3, 5, 7, 9],
"A":[4, 5, 6, 7, 8],
"N":[9, 8, 7, 6, 5]})
df.quantile(0.3, axis = 0)
print(df.quantile(0.3, axis = 0) )
输出:
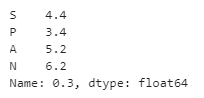
在上面的程序中,我们首先将熊猫的库导入为pd,然后定义数据框架。创建数据框架后,我们使用quantile()函数沿行轴分配和创建数值,如上面的程序所示。程序最终实现,结果如上面的快照所示。
例子#2
使用quantile()函数来实现轴上的多个量化值的结果。
import pandas as pd
df = pd.DataFrame({"S":[2, 4, 6, 8, 10],
"P":[1, 3, 5, 7, 9],
"A":[4, 5, 6, 7, 8],
"N":[9, 8, 7, 6, 5]})
df.quantile([0.2, 0.23, .25, .3], axis = 0)
print(df.quantile([0.2, 0.23, .25, .3], axis = 0) )
输出:
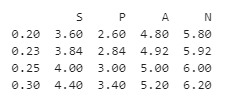
在上面的程序中,我们首先导入pandas作为pd,然后定义数据框架。定义完数据框架后,我们使用quantile()函数沿行轴分配多个quantile值,因此轴值被分配为0,如上述程序所示。这样,程序就实现了,输出结果如上面的快照所示。
我们将通过一个玩具信息集合来逐步实现量化标准化计算。在这一点上,我们将把它包装成一种能力,以应用一个再现的数据集。最后,我们将用几个实例来感知量化标准化时信息的样子。标准化是通过强制要求所看的拨款是相等的来完成的。正常的传播,是通过对每个四分位数的正常测试得到的,被用来作为参考。
执行量化标准化的最初阶段是对每个部分,即每个例子进行自主分类。为了对所有部分进行自由排序,我们使用NumPy sort()对数据框架中的质量进行处理。由于我们失去了Numpy的部分和列表名称,我们利用记录和分段名称的排列结果来制作另一个排列的数据框架。这些平均质量将取代每个部分的原始信息,其最终目的是我们在Samples/Columns中保存对每个感知或特征的要求。这基本上使所有的例子都有类似的分散性。请注意,在上升的请求中的平均素质,主要的价值是最小的位置,而后者是最值得注意的位置。让我们改变记录,以反映出我们注册的平均数是由低到高的定位。要做到这一点,我们使用列表工作降级位置从1开始排列。注意我们的列表从1开始,反映出它是一个位置。这就是潘达斯中量化标准化的工作方式。
结论
因此,我的结论是,量化标准化是这样一种可衡量的技术,在调查高维数据集时可以起到帮助作用。执行标准化(如量化标准化)的基本目标之一是改变粗略的信息,最终目的是驱逐任何因专门的古董而产生的不良品种,并保护我们热衷于研究的真正品种。量子标准化通常被用于基因组学等领域,但它很可能在任何高维环境中都有帮助。
