

在这篇文章中,我们深入解释了局部响应归一化(LRN)的概念,以及与批量归一化的比较。
目录:
- 归一化简介
- 局部响应归一化(LRN)
- TensorFlow中的局部响应归一化(LRN)
- 批量归一化与局部响应归一化(LRN)的比较
前提是:
归一化简介
归一化在深度神经网络中被用来补偿像ReLU、ELU等激活函数的无界性质。这些激活函数的输出层并不局限于一个有限的范围(比如tanh的[-1,1]),而是可以在训练允许的范围内上升。为了使你的无界激活不至于抬高输出层的值,归一化只是在激活函数的前面使用。
本地响应归一化(LRN)
局部响应归一化(LRN)首次在AlexNet架构中使用,ReLU作为激活函数而不是更常见的tanh和sigmoid。除了上述原因外,LRN还被用来加强侧向抑制。
本地反应正常化是一个正常化层,它利用侧向抑制来实施这一概念。侧向抑制是一个神经生物学概念,概述了受刺激的神经元如何压制附近的神经元,强化感觉体验并产生最大形式的尖峰,在该地区形成对比。在使用LRN对卷积神经网络进行规范化时,你可以在通道内或通道间进行规范化。
LRN原语对局部响应进行前向和后向归一化。
通道间LRN
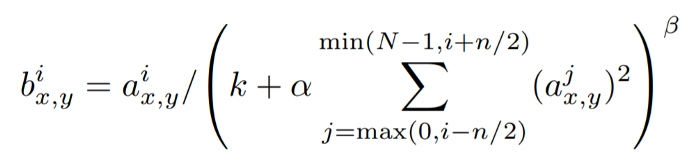
归一化前后(x,y)位置的像素值分别为i,a(x,y)和b(x,y),N是通道的总数。(k,α,β,n)是超参数,是常数。k是一个归一化常数和一个对比常数,用于避免任何奇异现象(零除法)。n常数指定邻域长度,或在归一化过程中必须考虑多少个连续的像素值。(k,α,β,n)是传统的归一化公式(0,1,1,N)。
首先,激活包含在总和运算符中;我们对它进行平方,以抵消正负效应。我们来看看和运算符的范围是什么。给定一个n,它向左迭代n/2,向右迭代n/2,同时记住边界,0和N-1。然后乘以一个系数,以减少其与分子相比的值,以保持分子中的激活值(如果太高,分子中的激活将被减少,导致梯度消失;如果太低,将导致梯度爆炸)。
最后,β被用来作为一个指数,以确定这个局部反应对问题激活的影响。β值越高,对相邻激活的惩罚越大,但β值越低对问题激活的影响越小。
通道内LRN:邻接只在通道内LRN的同一通道内扩展,其公式为:
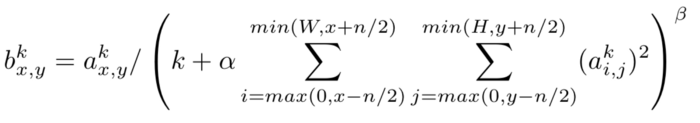
其中(W,H)是特征图的宽度和高度。
归一化的邻域是通道间和通道内LRN之间的唯一变化。在通道内LRN中,在所考虑的像素周围定义了一个二维邻域(与通道间LRN的一维邻域相反)。
TensorFlow中的局部响应归一化(LRN)。
Tensorflow的实现方式如下:
import tensorflow as tf
import numpy as np
x = np.array([i for i in range(1, 33)]).reshape([2, 2, 2, 4])
y = tf.nn.lrn(input=x, depth_radius=2, bias=1, alpha=1, beta=0.75)
print("input:\n", x)
print("output:\n", y)
input:
[[[[ 1 2 3 4]
[ 5 6 7 8]]
[[ 9 10 11 12]
[13 14 15 16]]]
[[[17 18 19 20]
[21 22 23 24]]
[[25 26 27 28]
[29 30 31 32]]]]
output:
tf.Tensor(
[[[[0.13119929 0.15223296 0.22834945 0.3120463 ]
[0.14621021 0.1247018 0.14548543 0.18664722]]
[[0.1239255 0.1028654 0.11315194 0.14340706]
[0.10845583 0.08916934 0.09553858 0.12041976]]]
[[[0.09743062 0.079716 0.08414467 0.10572015]
[0.08913988 0.07271773 0.07602308 0.09531549]]
[[0.08263378 0.06727669 0.06986426 0.08746313]
[0.07735948 0.06289289 0.06498932 0.08126954]]]], shape=(2, 2, 2, 4), dtype=float32)
批量归一化与局部响应归一化(LRN)
批量归一化是一种监督下的学习技术,用于将神经网络的中间层输出转化为通用形式。这有效地 "重置 "了前一层输出的分布,使其在下一层得到更有效的处理。这种技术加快了学习速度,因为归一化可以防止激活值过高或过低,并允许每一层独立于其他层学习。
对输入进行归一化可以减少处理层之间的 "辍学 "率或数据损失。这大大提高了整个网络的准确性。
为了提高深度学习网络的稳定性,批量归一化通过减去批量归一化暗示的方式影响前面激活层的输出,并通过批量标准偏差的方式对其进行划分。
这种用随机初始化的参数对输出进行的移动或缩放会降低下一层权重的准确性,所以如果损失函数太大,可以使用随机梯度下降来做这种归一化。
批量归一化为该层提供了另外两个可训练的参数。伽马(标准偏差)和贝塔(平均值)参数被乘以归一化结果。这使得堆栈归一化和梯度下降能够一起工作,通过简单地改变每个输出的两个权重来对数据进行 "去归一化"。通过调整所有其他相关的权重,减少了数据损失,提高了网络稳定性。
另一方面,批量归一化只能以一种方式进行,但局部响应归一化有不同的方向,可以在通道之间或内部进行归一化。
通过OpenGenus的这篇文章,你一定对局部响应正常化(LRN)有了完整的认识。
