

语义分割的常用方法是深度CNN,但这种方法有一个局限性,即分割过程是在输入数据的下采样版本上进行的,因此当涉及到高分辨率的分割时,它们的表现很差。这可以通过其他方法来改善,在时间和空间等模型执行要求之间进行权衡,以获得更好的分辨率。一个有效的替代解决方案是RefineNet模型。
目录
- 简介
- 传统的方法
- RefineNet模型
- 性能比较
- 优势和劣势
- 应用
简介
图像分割从根本上说是给给定图像中的像素分配标签的过程,这是数字图像处理和计算机视觉的一个重要部分。一个图像中的特定像素组通常被识别为一个选定的类别,该类别可通过一组属性明显识别,所设计的模型试图正确实现这一分配任务。有两种类型的图像分割,即。
实例分割
目标是唯一地识别属于同一标签/类别的所有单个实例/物体。
语义分割
目标是共同识别属于搜索标签/类别的所有实例/物体。
RefineNet正在对语义分割进行深入研究,因此我们的讨论将限于此。
概括性方法
从创建神经网络(NN)的方法来看,完全可以认为它在语义分割方面的效果会相当好。随着对应用各种NN技术的进一步探索,人们发现深度卷积神经网络(CNN)在物体识别问题上表现突出,尤其是残差网模型以明显的领先优势超过了其他模型。
尽管有这样的结果,这些方法的一个相关问题是,在模型训练的前向过程中,他们对数据进行了向下采样,由于这个原因,所识别的片段的分辨率降低了。现在对这个问题的直接解决方法是使用去卷积程序将数据提高到所需的分辨率,但这样做我们仍然会失去重要的低层次视觉特征。这种低层次的视觉信息对于生成分离片段的明确边界至关重要。
下图显示了卷积操作对下采样图像的影响:
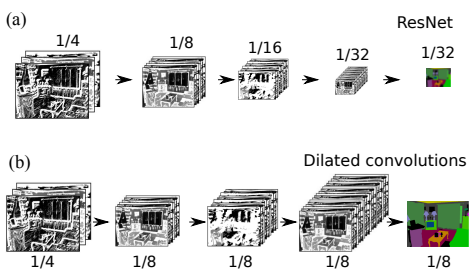
在进一步研究之前,在RefineNet模型之前,有一个模型已经显示出很高的性能,被称为ResidualNet模型(简称ResNet)。由于RefineNet是建立在ResNet之上的,因此有必要看一下它所执行的基本功能的一些基础代码。层工厂需要执行的功能是。
| 功能名称 | 描述 |
|---|---|
| batchnorm | 对二维数据进行批量归一化处理 |
| conv3x3 | 以3的内核大小执行卷积。 |
| conv1x1 | 执行内核大小为1的卷积。 |
| convbnrelu | 可选择创建一个有或没有ReLU的卷积层。 |
它还包含2个类:
| 类名 | 描述 |
|---|---|
| CRPBlock | 它的构造函数使用conv3x3来创建和初始化一个CRPBlock,同时还有一个函数forward,通过使用n_stages的maxpooling来建立跳转。 |
| RCUBlock | 它的构造函数使用conv3x3来创建和初始化一个CRPBlock,同时使用一个函数forward来对每个块中的每个阶段应用relu activation。 |
的代码是:
import torch.nn as nn
import torch.nn.functional as F
def batchnorm(in_planes):
"batch norm 2d"
return nn.BatchNorm2d(in_planes, affine=True, eps=1e-5, momentum=0.1)
def conv3x3(in_planes, out_planes, stride=1, bias=False):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=bias)
def conv1x1(in_planes, out_planes, stride=1, bias=False):
"1x1 convolution"
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride,
padding=0, bias=bias)
def convbnrelu(in_planes, out_planes, kernel_size, stride=1, groups=1, act=True):
"conv-batchnorm-relu"
if act:
return nn.Sequential(nn.Conv2d(in_planes, out_planes, kernel_size, stride=stride, padding=int(kernel_size / 2.), groups=groups, bias=False),
batchnorm(out_planes),
nn.ReLU6(inplace=True))
else:
return nn.Sequential(nn.Conv2d(in_planes, out_planes, kernel_size, stride=stride, padding=int(kernel_size / 2.), groups=groups, bias=False),
batchnorm(out_planes))
class CRPBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_stages):
super(CRPBlock, self).__init__()
for i in range(n_stages):
setattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'),
conv3x3(in_planes if (i == 0) else out_planes,
out_planes, stride=1,
bias=False))
self.stride = 1
self.n_stages = n_stages
self.maxpool = nn.MaxPool2d(kernel_size=5, stride=1, padding=2)
def forward(self, x):
top = x
for i in range(self.n_stages):
top = self.maxpool(top)
top = getattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'))(top)
x = top + x
return x
stages_suffixes = {0 : '_conv',
1 : '_conv_relu_varout_dimred'}
class RCUBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_blocks, n_stages):
super(RCUBlock, self).__init__()
for i in range(n_blocks):
for j in range(n_stages):
setattr(self, '{}{}'.format(i + 1, stages_suffixes[j]),
conv3x3(in_planes if (i == 0) and (j == 0) else out_planes,
out_planes, stride=1,
bias=(j == 0)))
self.stride = 1
self.n_blocks = n_blocks
self.n_stages = n_stages
def forward(self, x):
for i in range(self.n_blocks):
residual = x
for j in range(self.n_stages):
x = F.relu(x)
x = getattr(self, '{}{}'.format(i + 1, stages_suffixes[j]))(x)
x += residual
return x
现在,ResNet模型可以使用上述实体创建不同的变体,理解其中一些变体所需的概念在《ResNet及其变体概述》中得到了明确的解释。
RefineNet模型
为了克服这个缺点,我们研究了一个新的混合模型架构,它创造性地从现有的技术中衍生出来,并将它们融合在一起,找到一个更有效的解决方案,以高分辨率进行语义分割。
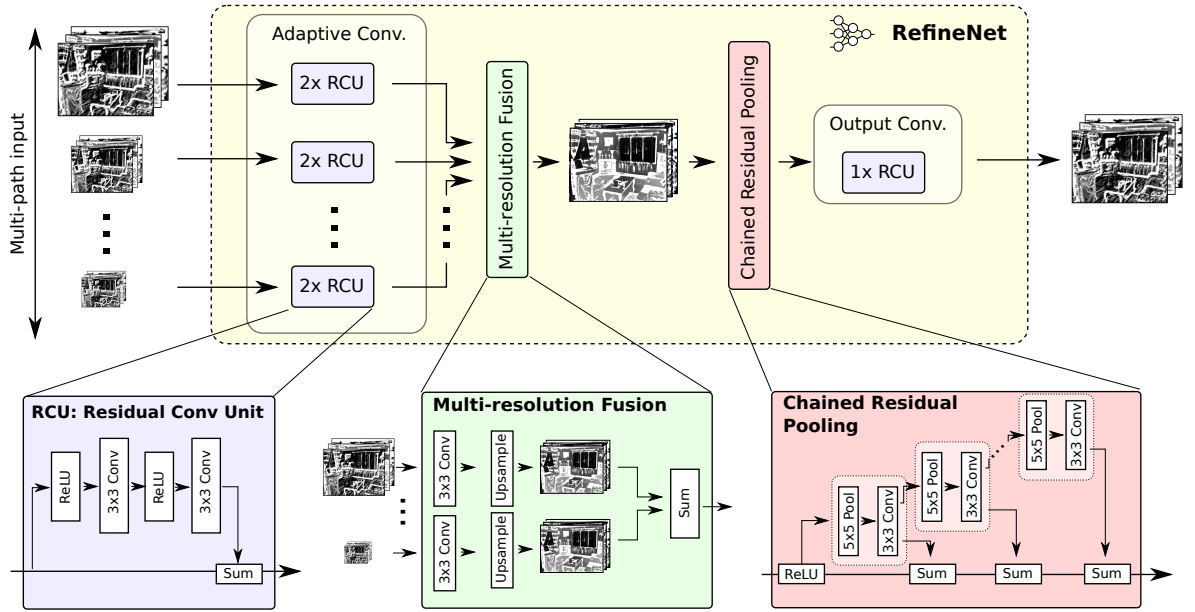
该细化模型包括2个核心部分。
RefineNet块
RefineNet块是3个阶段的处理实体,每个处理实体在模型的不同层次上处理和学习数据的特征。每个块的3个阶段包括以下部分:
- 自适应卷积--使用RCU(剩余卷积单元)在对应于下采样数据的层次上执行层学习和处理。
- 多分辨率融合--结合来自短距离和长距离处理的输入流数据。
- 链式分辨率汇集 - 递归地汇集和卷积合并的数据,并使用求和法以链式方式保持结果。
这可以形象化为:
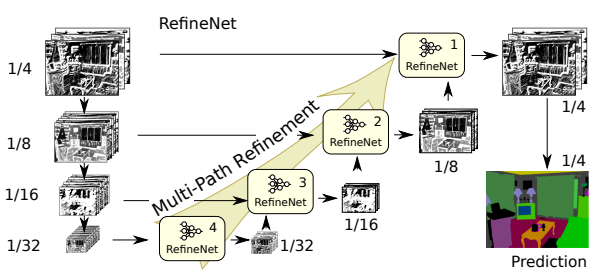
多路径细化
使用具有身份映射的残差连接使梯度通过本地残差连接在RefineNet模型内直接传播,这也通过长距离的残差连接直接传播到输入路径。从本质上讲,每个分辨率级别的信息都是通过使用RefineNet块和相互连接的架构来捕获的,以交接的方式(使用短距离和长距离连接),我们能够从中建立有效的段的理解力。
这可以可视化为:
很明显,这个架构可以根据不同的数据集进行修改,几个典型的修改包括。
- 级联--改变RefineNet块层的数量
- 缩放--改变数据缩放输入的数量。这是在模型中加入了ResNet的概念
为了清楚起见,上面描述的模型是一个4层级联的RefineNet与1比例的ResNet。同样地,下面的模型是一个4级联的RefineNet与2级联的ResNet:
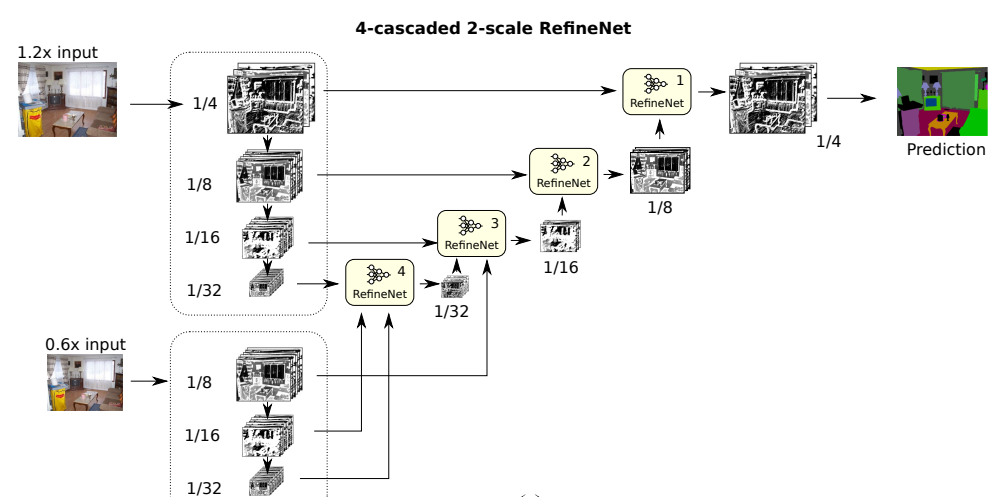
这可以在python中用一个类似于下图的类来实现:
class RefineNet(nn.Module):
def __init__(self, block, layers, num_classes=21):
self.inplanes = 64
super(RefineNet, self).__init__()
self.do = nn.Dropout(p=0.5)
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.p_ims1d2_outl1_dimred = conv3x3(2048, 512, bias=False)
self.adapt_stage1_b = self._make_rcu(512, 512, 2, 2)
self.mflow_conv_g1_pool = self._make_crp(512, 512, 4)
self.mflow_conv_g1_b = self._make_rcu(512, 512, 3, 2)
self.mflow_conv_g1_b3_joint_varout_dimred = conv3x3(512, 256, bias=False)
self.p_ims1d2_outl2_dimred = conv3x3(1024, 256, bias=False)
self.adapt_stage2_b = self._make_rcu(256, 256, 2, 2)
self.adapt_stage2_b2_joint_varout_dimred = conv3x3(256, 256, bias=False)
self.mflow_conv_g2_pool = self._make_crp(256, 256, 4)
self.mflow_conv_g2_b = self._make_rcu(256, 256, 3, 2)
self.mflow_conv_g2_b3_joint_varout_dimred = conv3x3(256, 256, bias=False)
self.p_ims1d2_outl3_dimred = conv3x3(512, 256, bias=False)
self.adapt_stage3_b = self._make_rcu(256, 256, 2, 2)
self.adapt_stage3_b2_joint_varout_dimred = conv3x3(256, 256, bias=False)
self.mflow_conv_g3_pool = self._make_crp(256, 256, 4)
self.mflow_conv_g3_b = self._make_rcu(256, 256, 3, 2)
self.mflow_conv_g3_b3_joint_varout_dimred = conv3x3(256, 256, bias=False)
self.p_ims1d2_outl4_dimred = conv3x3(256, 256, bias=False)
self.adapt_stage4_b = self._make_rcu(256, 256, 2, 2)
self.adapt_stage4_b2_joint_varout_dimred = conv3x3(256, 256, bias=False)
self.mflow_conv_g4_pool = self._make_crp(256, 256, 4)
self.mflow_conv_g4_b = self._make_rcu(256, 256, 3, 2)
self.clf_conv = nn.Conv2d(256, num_classes, kernel_size=3, stride=1,
padding=1, bias=True)
def _make_crp(self, in_planes, out_planes, stages):
layers = [CRPBlock(in_planes, out_planes,stages)]
return nn.Sequential(*layers)
def _make_rcu(self, in_planes, out_planes, blocks, stages):
layers = [RCUBlock(in_planes, out_planes, blocks, stages)]
return nn.Sequential(*layers)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers
除此之外,包含正向函数和从另一个定义模型瓶颈的类中导出模型的函数,将构成RefineNet变体的基本部分。
特定层次的信息交换和处理的概念是为一个使用4层代码的4级模型构建的。通过分析ResNet和RefineNet代码中使用的功能的相似性,可以看出RefineNet是基于ResNet创建的。
性能比较
这个模型已经在多个数据集上进行了广泛的测试,我们要看看不同模型在实际可实现的数据集如城市景观上的结果。
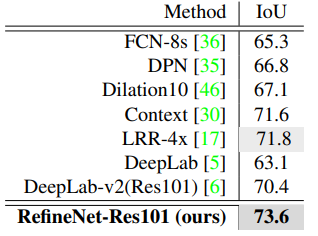
城市景观数据集包括2975张训练图像和500张验证图像,属于19个类别。这个数据集为50个不同的欧洲城市的街道场景图像上的主题物体提供了精细的像素级注释。在Cityscapes数据集上应用RefineNet模型的结果是:
实际的和预测的片段之间的比较显示在几个样本实例中:

优势和劣势
RefineNet模型的优点是:
- 创建容易,可以进行端到端的训练。
- 灵活,可以以各种方式进行级联和修改
- 性能,在高分辨率的图像上产生更好的结果
RefineNet模型的劣势是:
- 模型的复杂性
- 处理能力强,由于模型是端到端的训练,它需要大量的资源来实现。
应用
由于语义分割的重要性,它的应用非常广泛。在一些领域,人们可以找到它的用途:
- 计算机/机器视觉
- 保健和医疗
- 体育
- 汽车
- 安全和防御
参考文献
本文的大部分内容是受RefineNet的专业介绍和性能提升的启发。高分辨率语义分割的多路径细化网络[1]
[1] Lin, G., Milan, A., Shen, C. and Reid, I., 2017.Refinenet:用于高分辨率语义分割的多路径细化网络。在IEEE计算机视觉和模式识别会议论文集(第1925-1934页)。
完整的RefineNet模型的代码可以在这里找到(作者:Guosheng Lin)。
