

订阅并获得免费指南--用Python进行数据可视化的终极指南
*表示需要
电子邮件地址*
强化学习 这是一个不断 增长的 领域 , ,而不仅仅是因为有 了突破性的进展。 深度学习.当然,如果我们谈及深度强化学习,它使用了 神经网络 下,但 它 还有更多的 。在我们穿越强化学习世界的旅程中,我们专注于最 受欢迎的 强化学习算法 之一 Q-Learning.这种方法被认为是时差控制的最大突破之一。在这篇文章中,我们将探讨 这个算法的 一个变种和 改进 -- 双Q学习, 或_双DQN。_

这捆电子书是专门为 初学者制作的。
,从Python基础知识到将机器学习算法部署到生产中的所有内容都在这里。
, 今天就成为机器学习的超级英雄 !
在这篇文章中,我们涵盖了以下主题。
- 了解Q-Learning和它的问题
- 双重Q-学习的直观性
- 双重Q-学习与Python的Q-学习实现
- DQN和双DQN直觉
- 用TensorFlow实现双倍Q学习(Double DQN)
- 用TF代理实现双Q学习(Double DQN)
1.了解Q-Learning及其问题
一般来说,强化学习是一种解决可以用 **马尔科夫决策过程(MDPs)**提出的问题的机制 。这种类型的学习依赖于学习代理与某种环境的互动。这个代理试图 在该环境中实现某种 目标 ,而环境有某些状态。
在它的追求中,代理人执行了许多 行动。每个行动都会改变环境的状态,并导致环境 的反馈 。反馈以奖励或惩罚的形式出现。在此基础上,代理学习哪些行动是合适的,哪些是不合适的,并建立所谓的政策。

Q-Learning 是 强化学习领域中最 知名的 算法之一 。
1.1 Q-学习的直觉
该算法估计 Q值,即在 政策 π下,在 状态 s_中采取 行动 的_价值。 这可以被认为是 行动的_质量_ a 在状态 s。在训练过程中,代理为每个状态行动组合更新 Q值 ,这意味着它形成一个 表,对于每个行动和状态我们存储 Q值。在训练过程中更新这些值的过程由公式描述。

正如我们之前提到的,对于一个特定的状态--动作对,这个_Q值_可以被观察为该特定动作在该特定状态下的质量。更高的 Q值 ,表明 ,对学习代理的奖励更大 。这是学习代理用来找出如何实现规定目标的机制。在这种情况下,政策 决定了哪些状态动作对被访问和更新。

上述公式的重要部分是 maxQ(St+1, a)。注意 _t+1_的 注释。这意味着 当前时间步骤 的Q值 是基于 未来时间步骤 的Q值 。很诡异,我知道。这意味着我们 一开始就把 状态 St 和 St+1 的 _Q值_初始化 为一些随机值。
在第一次训练迭代中,我们 根据奖励和 St_+1_ 状态下的 _Q__值_的 随机 值来更新 St 状态 下的Q值。由于整个系统是由 奖励 驱动 的,而不是由 Q值 本身 驱动 的,所以 系统 收敛 ,达到最佳结果。

为了更清楚地了解情况,我们可以将_Q-Learning_分解为几个步骤。它看起来就像这样。
- 初始化 _Q表中_的所有_Q值_为任意值,终端状态的Q值为0:
Q(s, a) = n, ∀s∈S,∀a∈A(s)
Q(终端状态, -) = 0 - 从政策π为该状态_A(s)定义的行动集合中挑选 行动_a。
- 执行 行动_a_
- 观察奖励_R_和下一个状态_s'_。
- 对于所有可能的行动,从状态_s'_中选择一个具有最高 _Q值_的行动--a'。
- 使用公式更新 该状态的值。
Q(s, a) ← Q(s, a) + α [R + γQ(s', a') - Q(s, a)] - 在每个时间步骤中重复 步骤2-5,直到达到终端状态。
- 对每个情节重复 步骤2-6
在其中的一个 以前的文章中,你可以找到这种算法的实现 。
1.2 Q-学习的问题
然而,公式 maxQ(St+1, a) 的这个 重要部分同时也是 _Q-Learning_的最大 问题 。事实上,这也是这种算法在某些随机环境中表现 不佳的原因 。由于 最大 算子 Q-学习 可以 高估 某些行动的_Q_值 。它可以 欺骗 ,认为某些行动值得细读,即使这些行动最后导致的 奖励较低 。让我们考虑这种情况。
- 环境 有4个状态--X、Y、Z、W。
- Z和W状态是 终端 状态。
- X是 开始的 状态,在这个状态下,代理人可以采取两种行动。
- 向上 - 这个动作的奖励是0,下一个状态是Y。
- Down - 这个动作的奖励是0,下一个状态是终端状态Z。
- 从Y状态开始,代理人可以采取 多个 行动,所有这些行动都会带他们到终端状态W。这些行动的奖励是随机值,遵循正态分布,其平均值为 -1,方差为 2 - N(-1,2)。这意味着在大量的迭代之后,奖励将是负的。
这个 MDP ,如下图所示。

这是一个简单的环境,有 4个状态。X是起始 状态,而Z和W是终端状态。代理人在X状态下可以采取两种 行动 - UP 和 DOWN。 采取这些行动的奖励 是0。有趣的部分是 从Y状态到W状态的一组行动 。这组行动的奖励遵循正态分布,平均值为-0.5,标准差为1。这意味着在大量的迭代之后,奖励将是 负的。

这又意味着我们的学习代理如果想使损失最小化,首先就不应该从状态X中选择行动 UP ,也就是说,代理的目标实际上是获得奖励 0,或最小的负值。这就是 Q-Learning 的问题所在。
因为我们有特定的奖励分布,学习代理可以被 , ,认为它应该在状态X中采取行动UP。简而言之,_最大_运算符更新了 _Q_值,这个行动的_Q_值_可能_是正的 ,学习代理将这个行动作为有效的选择。 Q值 被 高估了!
2.2.双Q学习的直觉
这个问题的解决方案 是由Hado van Hasselt在他2010年的**论文中提出的 。他所提出的是,与其使用一组数据和一个估计器,不如使用 两个估计器。这实际上意味着,我们应该使用两个** ,而不是对每个状态-动作对使用一个 Q值 ,而是使用两个 ,即 QA 和 QB。从技术上讲,这种方法的重点是找到行动 a* ,该行动 ,在下一个状态 s'中使 QA ,达到最大化--(Q(s',a*)=max Q(s',a))。然后它用这个动作得到 第二个 Q值 - _QB(s', a*)_的值。最后,它使用 QB(s', a*) ,以便更新 QA(s, a)。

对于 _QB_来说,这也是反过来做的。
让我们把_双Q学习_过程分解为 。它看起来像这样。
- 初始化 所有的_QA_, QB 和起始状态 - s
- 重复
- 挑选 行动_a_ ,基于 QA(s, -) 和 QB(s, -) 得到 r 和 s'
- 更新(A) 或 更新(B) (随机挑选 )
- 如果 Update(A)
- 挑选 的行动 a* = argmax QA(s', a)
- 更新 QA
QA(s, a) ← QA(s, a) + α [R + γQB(s', a*) - QA(s, a)] 。
- 如果 更新(B)
- 选取 的行动 b* = argmax QB(s', a)
- 更新 QB
QB(s, a) ← QB(s, a) + α [R + γQA(s', b*) - QB(s, a)]
- s ← s'
- 直到结束

那么,为什么这个方法有效呢?那么,在本文中,从数学上 证明 , 行动 _a*_的_QB_的期望值 小于或等于 ,即 E(QB(s', a*)) ≤ Max QA(s', a*)。这意味着如果我们进行大量的迭代, _QB(s', a*)_的期望值 会 比 _QA(s', a*)_的最大值 要小 。反过来, QA(s, a) 永远不会被更新为 最大 ,因此永远不会 被高估。
3.双重Q-学习与Python的Q-学习实现
在我们继续实施之前,让我们导入必要的库并定义一些球状物。
import numpy as np
import random
from IPython.display import clear_output
import gym
import matplotlib.pyplot as plt
# Globals
ALPHA = 0.1
GAMMA = 0.6
EPSILON = 0.05
3.1 实现环境
作为本实验的第一步,我们实现简单的环境。
class MDP():
def __init__(self, action_tree=9):
# Actions
self.down, self.up = 0, 1
# States and posible actions
self.state_actions = {
'X': [self.down, self.up],
'Y': [i for i in range(action_tree)],
'W': [self.down],
'Z': [self.up] }
# Transitions
self.transitions = {
'X': {self.down: 'Z',
self.up: 'Y'},
'Y': {a: 'W' for a in range(action_tree)},
'W': {self.down: 'Done'},
'Z': {self.up: 'Done'}
}
self.states_space = 4
self.action_space = action_tree
self.state = 'X'
def _get_reward(self):
return np.random.normal(-0.5, 1) if self.state == 'W' else 0
def _is_terminated_state(self):
return True if self.state == 'W' or self.state == 'Z' else False
def reset(self):
self.state = 'X'
return self.state
def step(self, action):
self.state = self.transitions[self.state][action]
return self.state, self._get_reward(), self._is_terminated_state(), None
def available_actions(self, state):
return self.state_actions[state]
def random_action(self):
return np.random.choice(self.available_actions(self.state))
mdp_enviroment = MDP()
在这个类的构造函数中,我们 ,初始化 行动和表示状态和每个状态下可能行动的字典。我们还创建了定义过渡的字典,也就是说,我们定义了从某一状态可以获得哪些其他状态。最后,我们将起始状态初始化为X。我们在这个类中有几个函数。
- _get_reward - 内部函数用于返回某些行动的奖励。一般来说,只有当我们最终进入状态W时,奖励才不会为零。
- _is_terminated_state - 检查状态是否结束。
- reset - 将环境的状态重置为X。
- step - 执行一个动作。
- available_actions - 返回所提供状态的可用动作。
- random_action - 采取随机行动。
在实现这个环境的过程中,我们尽量遵循Open AI Gym的API,所以当我们决定切换到Open AI Gym时,我们应该有更少的变化。不要忘记创建这个类的实例。
3.2 实现Q-Learning功能
好了,现在让我们观察一下这个环境的Q-Learning函数。
def mdp_q_learning(enviroment, num_of_tests = 10000, num_of_episodes=300):
num_of_ups = np.zeros(num_of_episodes)
for _ in range(num_of_tests):
# Initialize Q-table
q_table = {state: np.zeros(9) for state in mdp_enviroment.state_actions.keys()}
rewards = np.zeros(num_of_episodes)
for episode in range(0, num_of_episodes):
# Reset the enviroment
state = enviroment.reset()
# Initialize variables
terminated = False
while not terminated:
# Pick action a....
if np.random.rand() < EPSILON:
action = enviroment.random_action()
else:
available_actions = enviroment.available_actions(enviroment.state)
state_actions = q_table[state][available_actions]
max_q = np.where(np.max(state_actions) == state_actions)[0]
action = np.random.choice(max_q)
# ...and get r and s'
next_state, reward, terminated, _ = enviroment.step(action)
# 'up's from state 'X'
if state == 'X' and action == 1:
num_of_ups[episode] += 1
# Update Q-Table
max_value = np.max(q_table[next_state])
q_table[state][action] += ALPHA *
(reward + GAMMA * max_value - q_table[state][action])
state = next_state
rewards[episode] += reward
return rewards, q_table, num_of_ups
函数 mdp_q_learning ,实现Q-Learning算法。
- 初始化 _Q表中_的所有_Q值_为任意值,终端状态的Q值为0:
Q(s, a) = n, ∀s∈S,∀a∈A(s)
Q(终端状态, -) = 0 - 对每一集重复进行
- 重复进行,直到达到终端状态
- 从政策π为该状态_A(s)定义的行动集合中挑选 行动_a。
- 执行 行动_a_
- 观察奖励_R_和下一个状态_s'_。
- 对于所有可能的行动,从状态_s'_中选择一个具有最高 _Q值_的行动--a'。
- 使用公式更新 该状态的值。
Q(s, a) ← Q(s, a) + α [R + γQ(s', a') - Q(s, a)] - s = s'
- 重复进行,直到达到终端状态
注意,在这个函数中,我们计算了算法从状态X中挑选动作UP的次数。我们把这个值和奖励一起返回,以便我们可以绘制它们。
q_reward, q_table, num_of_ups = mdp_q_learning(mdp_enviroment)
plt.figure(figsize=(15,8))
plt.plot(num_of_ups/10000*100, label='UPs in X', color='#FF171A')
plt.plot(q_reward, color='#6C5F66', label='Reward')
plt.legend()
plt.ylabel('Percentage of UPs in state X')
plt.xlabel('Episodes')
plt.title(r'Q-Learning')
plt.show()
我们绘制了在状态 X 中选择行动 UP 的次数,以百分数表示。

我们可以看到,在开始的时候, Q-learning,因为它的性质,在 X 的状态下,经常选择行动 UP 。在这一时期,奖励甚至在几个情节中是积极的。然而,当这个高峰期过去后,我们可以看到奖励 , 稳定在0(大部分)。这个错误决策的初始时间可以通过 _双重Q-学习_来改善吗?
3.3 实现双倍Q-学习功能
为我们创建的环境实现Double Q-Learning Python 看起来是这样的。
def mdp_double_q_learning(enviroment, num_of_tests = 10000, num_of_episodes=300):
num_of_ups = np.zeros(num_of_episodes)
for _ in range(num_of_tests):
# Initialize Q-table
q_a_table = {state: np.zeros(9) for state in mdp_enviroment.state_actions.keys()}
q_b_table = {state: np.zeros(9) for state in mdp_enviroment.state_actions.keys()}
rewards = np.zeros(num_of_episodes)
for episode in range(0, num_of_episodes):
# Reset the enviroment
state = enviroment.reset()
# Initialize variables
terminated = False
while not terminated:
# Pick action a....
if np.random.rand() < EPSILON:
action = enviroment.random_action()
else:
q_table = q_a_table[state][enviroment.available_actions(enviroment.state)] + \
q_b_table[state][enviroment.available_actions(enviroment.state)]
max_q = np.where(np.max(q_table) == q_table)[0]
action = np.random.choice(max_q)
# ...and get r and s'
next_state, reward, terminated, _ = enviroment.step(action)
# 'up's from state 'X'
if state == 'X' and action == 1:
num_of_ups[episode] += 1
# Update(A) or Update (B)
if np.random.rand() < 0.5:
# If Update(A)
q_a_table[state][action] += ALPHA * (reward + GAMMA * q_b_table[next_state][np.argmax(q_a_table[next_state])] - q_a_table[state][action])
else:
# If Update(B)
q_b_table[state][action] = ALPHA * (reward + GAMMA * q_a_table[next_state][np.argmax(q_b_table[next_state])] - q_b_table[state][action])
state = next_state
rewards[episode] += reward
return rewards, q_a_table, q_b_table, num_of_ups
我们像这样在环境的实例上运行它。
dq_reward, _, _, dq_num_of_ups = mdp_double_q_learning(mdp_enviroment)
我们再次计算算法 从状态X中 选取 行动UP 的次数 。双Q学习 算法找出陷阱的速度更快。
plt.figure(figsize=(15,8))
plt.plot(dq_num_of_ups/10000*100, label='UPs in X', color='#FF171A')
plt.plot(dq_reward, color='#6C5F66', label='Reward')
plt.legend()
plt.ylabel('Percentage of UPs in state X')
plt.xlabel('Episodes')
plt.title(r'Double Q-Learning')
plt.show()
观察一下图。

3.4 比较Q-Learning和双Q-Learning的结果
当我们把两种算法的结果放在同一张图上时,请看一下它是什么样子。
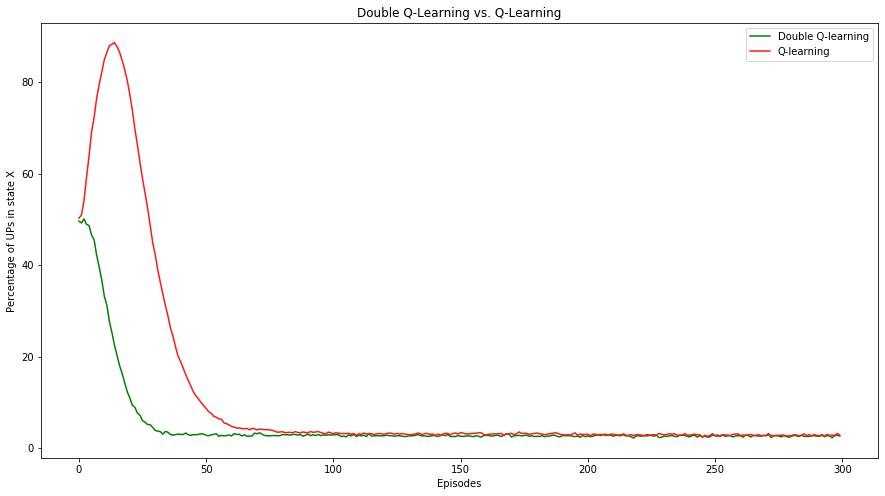
我们可以说, Double Q-Learning 在一半的训练时间内学到了最优策略。最后,如果我们打印出 累积奖励 ,这样我们就可以看到谁的表现更好。

我们可以看到, Double Q-Learning 的结果比vanilla Q-Learning好2.5倍 。
3.5 与开放式人工智能体育馆合作
好了,我们看到了当我们在随机环境中使用两种算法时会发生什么。让我们检查一下当我们在 Open AI Gym 环境中使用这些算法时会发生什么。对于这个实验,我们使用环境 Taxi-V2 。这是个相对简单的 环境。该环境有 4个地点 (状态),代理人的目标是在一个地点接乘客,在另一个地点送他。代理人可以执行6个动作(南、北、西、东、接、送)。关于环境的更多信息可以找到 这里.

首先,我们需要 ,加载 环境。
enviroment = gym.make("Taxi-v2").env
enviroment.render()
print('Number of states: {}'.format(enviroment.observation_space.n))
print('Number of actions: {}'.format(enviroment.action_space.n))
+---------+
|R: | : :G|
| : : : : |
| : : : : |
| | : | : |
|Y| : |B: |
+---------+
Number of states: 500
Number of actions: 6
然后我们需要修改 Q-Learning 和 Double Q-Learning 函数,使它们现在适用于这个API。变化 很小,但很关键。
def q_learning(enviroment, num_states, num_actions, num_of_episodes=1000):
# Initialize Q-table
q_table = np.zeros((enviroment.observation_space.n, enviroment.action_space.n))
rewards = np.zeros(num_of_episodes)
for episode in range(0, num_of_episodes):
# Reset the enviroment
state = enviroment.reset()
# Initialize variables
terminated = False
while not terminated:
# Pick action a....
if np.random.rand() < EPSILON:
action = enviroment.action_space.sample()
else:
max_q = np.where(np.max(q_table[state]) == q_table[state])[0]
action = np.random.choice(max_q)
# ...and get r and s'
next_state, reward, terminated, _ = enviroment.step(action)
# Update Q-Table
q_table[state, action] += ALPHA * (reward + GAMMA * np.max(q_table[next_state]) - q_table[state, action])
state = next_state
rewards[episode] += reward
return rewards, q_table
def double_q_learning(enviroment, num_of_episodes=1000):
q_a_table = np.zeros([enviroment.observation_space.n, enviroment.action_space.n])
q_b_table = np.zeros([enviroment.observation_space.n, enviroment.action_space.n])
rewards = np.zeros(num_of_episodes)
for episode in range(0, num_of_episodes):
# Reset the enviroment
state = enviroment.reset()
# Initialize variables
terminated = False
while not terminated:
# Pick action a....
if np.random.rand() < EPSILON:
action = enviroment.action_space.sample()
else:
q_table = q_a_table[state] + q_b_table[state]
max_q = np.where(np.max(q_table) == q_table)[0]
action = np.random.choice(max_q)
# ...and get r and s'
next_state, reward, terminated, _ = enviroment.step(action)
# Update(A) or Update (B)
if np.random.rand() < 0.5:
# If Update(A)
q_a_table[state, action] += ALPHA * (reward + GAMMA * q_b_table[next_state, np.argmax(q_a_table[next_state])] - q_a_table[state, action])
else:
# If Update(B)
q_b_table[state, action] = ALPHA * (reward + GAMMA * q_a_table[next_state, np.argmax(q_b_table[next_state])] - q_b_table[state, action])
state = next_state
rewards[episode] += reward
return rewards, q_a_table, q_b_table
最后,我们可以运行这两个函数。
q_reward, q_table = q_learning(enviroment, observation_space, action_space)
dq_reward, q_a_table, q_b_table = double_q_learning(enviroment)
一旦它们完成了,我们可以绘制出每种算法的 奖励 。

在这种情况下,我们可以注意到的是,总体而言, Q-Learning 的表现 ,比 Double Q-Learning好 。尽管这看起来很奇怪,但它实际上是预期会发生的。香草的 Q-Learning 只学习一个 Q-Table ,而 Double Q-learning 必须学习_两个_ Q-Table。实质上, 双重Q-学习 的样本效率较低 ,但它提供了一个更好的 策略。
4.DQN和双DQN直觉
随着 深度学习的缄默进展,研究人员提出了一个想法:Q-Learning可以与神经网络混合。这就是深度强化学习,或者说是 _深度Q-Learning_准确地说, ,就这样诞生了。 深度Q-Learning 或 DQN ,而不是使用 Q-Tables,而是使用两个神经网络。
在这个架构中,网络是前馈神经网络,用于预测最佳 _Q_值。由于事先没有提供输入数据,代理人必须将以前的经验存储在一个叫做 experience reply的本地存储器中。这些信息随后被用作输入数据。
需要注意的是, DQNs 并不像大多数神经网络那样使用 监督 学习。其原因是缺乏标签(或预期输出)。这些标签并没有事先提供给学习代理,也就是说,学习代理必须自己找出这些标签。
因为每个 Q值 ,取决于政策, 目标 (预期输出)随着每次迭代不断变化。这就是为什么这种类型的学习代理不只有一个神经网络,而是 两个 的主要原因。第一个网络,被称为 Q网络 ,在状态St下计算 Q值 。第二个网络,被称为 目标网络 ,在状态St+1下计算 _Q_值 。

更正式地讲,给定当前状态 St, Q-网络 检索行动值 Q(St,a)。同时, 目标网络 使用下一个状态 St+1 来计算 Q(St+1, a) 为 Temporal Difference 目标。为了 稳定 两个网络的训练,在每个N次迭代 , Q网络 的 参数被复制到 目标网络。
在数学上,深度Q网络_(DQN_)被表示为一个神经网络,对于一个给定的状态 s ,输出一个行动值的向量 Q(s, - ; θ),其中 θ 是网络的参数。 目标网络,参数为 θ -,与 _Q网络_相同,但其参数每 τ 步从在线网络中复制,因此,此时 θ - t = θt。然后, DQN 所用的目标本身是这样定义的。

前段时间,我们用Python和Tensorflow 2实现了这个过程。你可以**在这里查看那个实现 。另外,我们也用 TF-Agents 来实现,你可以在这里**找到 。
DQN 的问题与vanilla _Q-Learning_基本相同,它高估了 Q值。因此,这个概念用来自 Double Q-Learning 和 Double DQN 的知识来扩展。它代表了对 _DQN_的最小可能改变。 我个人认为,作者能够在保持 DQN 算法不变的情况下,获得_双Q学习_的大部分好处,这是相当优雅的 。
双Q-learning 的核心是通过将 最大 算子拼接到行动 选择 和行动 评估中来减少 Q值 的高估。这就是 DQN 算法中的目标网络所发挥的主要作用。意思是,没有额外的网络被添加到系统中,但对 _Q-_网络 的策略的评估是通过使用 目标网络 来估计其价值。所以,只有目标是在双DQN中变化的。

总而言之, 第二个网络的权重 被替换为目标网络的权重,用于 政策的评估 。 目标网络 仍然定期更新,通过 从 Q网络复制 参数。
5.双DQN TensorFlow实现
这篇文章包含 两个Double DQN的 实现。两者都是用Python 3.7并使用Open AI Gym完成的。第一个实现使用TensorFlow 2,第二个使用TF-Agents。请确保你的环境中安装了这些东西。
- Python 3.7
- TensorFlow 2
- TF-Agents
- 开放式人工智能体育馆
如果你需要了解更多关于TensorFlow 2的信息,请查看 这个指南 ,如果你需要熟悉 TF-Agents,我们推荐 这个指南。
在本节教程中,我们使用著名的 _CartPole-v0_环境。

在这个环境中,一个杆子被连接到一个小车上,小车沿着轨道移动。整个结构是通过对小车施加+1或-1的 力,并使其向左或向右移动来控制的。杆子在开始时是直立的,目标是防止它倒下。每一个时间戳,如果杆子没有倒下,就会得到+1的奖励 。当杆子离开垂直方向超过15度,或者小车离开中心超过2.4个单位时,整个剧情就结束了。
5.1 导入、全局和环境
让我们用我们需要 导入的模块来启动这个实现 。
import gym
import tensorflow as tf
from collections import deque
import random
import numpy as np
import math
from tensorflow.keras import Model, Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Input
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import Huber
from tensorflow.keras.initializers import he_normal
from tensorflow.keras.callbacks import History
除此之外,以下是 我们需要定义的一些全局 常量 。
MAX_EPSILON = 1
MIN_EPSILON = 0.01
GAMMA = 0.95
LAMBDA = 0.0005
TAU = 0.08
BATCH_SIZE = 32
REWARD_STD = 1.0
MAX_EPSILON 和 MIN_EPSILON 是用来控制探索与被探索的比例。而其他的则是在训练过程中使用。 REWARD_STD 有特殊的意义,我们将在后面查看。现在,我们需要 加载 环境。
enviroment = gym.make("CartPole-v0")
NUM_STATES = 4
NUM_ACTIONS = enviroment.action_space.n
我们还定义了这个环境中可用的状态和动作的数量。
5.2 经验重放
下一件我们需要处理的事情是 经验重放。这是一个 缓冲区 ,用来保存训练过程中使用的信息。实现起来是这样的。
class ExpirienceReplay:
def __init__(self, maxlen = 2000):
self._buffer = deque(maxlen=maxlen)
def store(self, state, action, reward, next_state, terminated):
self._buffer.append((state, action, reward, next_state, terminated))
def get_batch(self, batch_size):
if no_samples > len(self._samples):
return random.sample(self._buffer, len(self._samples))
else:
return random.sample(self._buffer, batch_size)
def get_arrays_from_batch(self, batch):
states = np.array([x[0] for x in batch])
actions = np.array([x[1] for x in batch])
rewards = np.array([x[2] for x in batch])
next_states = np.array([(np.zeros(NUM_STATES) if x[3] is None else x[3])
for x in batch])
return states, actions, rewards, next_states
@property
def buffer_size(self):
return len(self._buffer)
请注意,这个类也会做一些小的 预处理 。这发生在函数 _get_arrays_from_batch_中。这个方法返回 从批次中 解构的状态、行动、奖励和下一个状态的数组 。
5.3 双重DQN代理
好了,到了有趣的部分。下面是 Double DQN代理的植入 。
class DDQNAgent:
def __init__(self, expirience_replay, state_size, actions_size, optimizer):
# Initialize atributes
self._state_size = state_size
self._action_size = actions_size
self._optimizer = optimizer
self.expirience_replay = expirience_replay
# Initialize discount and exploration rate
self.epsilon = MAX_EPSILON
# Build networks
self.primary_network = self._build_network()
self.primary_network.compile(loss='mse', optimizer=self._optimizer)
self.target_network = self._build_network()
def _build_network(self):
network = Sequential()
network.add(Dense(30, activation='relu', kernel_initializer=he_normal()))
network.add(Dense(30, activation='relu', kernel_initializer=he_normal()))
network.add(Dense(self._action_size))
return network
def align_epsilon(self, step):
self.epsilon = MIN_EPSILON + (MAX_EPSILON - MIN_EPSILON) * math.exp(-LAMBDA * step)
def align_target_network(self):
for t, e in zip(self.target_network.trainable_variables,
self.primary_network.trainable_variables): t.assign(t * (1 - TAU) + e * TAU)
def act(self, state):
if np.random.rand() < self.epsilon:
return np.random.randint(0, self._action_size - 1)
else:
q_values = self.primary_network(state.reshape(1, -1))
return np.argmax(q_values)
def store(self, state, action, reward, next_state, terminated):
self.expirience_replay.store(state, action, reward, next_state, terminated)
def train(self, batch_size):
if self.expirience_replay.buffer_size < BATCH_SIZE * 3:
return 0
batch = self.expirience_replay.get_batch(batch_size)
states, actions, rewards, next_states = expirience_replay.get_arrays_from_batch(batch)
# Predict Q(s,a) and Q(s',a') given the batch of states
q_values_state = self.primary_network(states).numpy()
q_values_next_state = self.primary_network(next_states).numpy()
# Copy the q_values_state into the target
target = q_values_state
updates = np.zeros(rewards.shape)
valid_indexes = np.array(next_states).sum(axis=1) != 0
batch_indexes = np.arange(BATCH_SIZE)
action = np.argmax(q_values_next_state, axis=1)
q_next_state_target = self.target_network(next_states)
updates[valid_indexes] = rewards[valid_indexes] + GAMMA *
q_next_state_target.numpy()[batch_indexes[valid_indexes], action[valid_indexes]]
target[batch_indexes, actions] = updates
loss = self.primary_network.train_on_batch(states, target)
# update target network parameters slowly from primary network
self.align_target_network()
return loss
在 DDQNAgent 类的构造函数中,除了初始化字段外,我们使用内部 _build_network 方法来 建立 两个网络。注意,我们 ,只 编译 Q-Network 或主网络。另外,注意这个类所暴露的丰富的API。
- align_epsilon - 该方法用于更新 epsilon 值。这个值代表探索与被探索的比率。我们的目标是在训练开始时探索更多的动作,但在后来慢慢转向利用所学的动作。
- align_target_network - 我们用这个方法将参数从 Q-Network 慢慢复制到 Target Network。
- act - 这个重要的函数返回在定义状态下应该采取的行动,同时考虑到 epsilon 。
- store - 将数值存储到经验回放中。
- train - 执行单一的训练迭代。
让我们 ,更仔细地观察 train 方法。
def train(self, batch_size):
if self.expirience_replay.buffer_size < BATCH_SIZE * 3:
return 0
batch = self.expirience_replay.get_batch(batch_size)
states, actions, rewards, next_states = expirience_replay.get_arrays_from_batch(batch)
# Predict Q(s,a) and Q(s',a') given the batch of states
q_values_state = self.primary_network(states).numpy()
q_values_next_state = self.primary_network(next_states).numpy()
# Initialize target
target = q_values_state
updates = np.zeros(rewards.shape)
valid_indexes = np.array(next_states).sum(axis=1) != 0
batch_indexes = np.arange(BATCH_SIZE)
action = np.argmax(q_values_next_state, axis=1)
q_next_state_target = self.target_network(next_states)
updates[valid_indexes] = rewards[valid_indexes] + GAMMA *
q_next_state_target.numpy()[batch_indexes[valid_indexes], action[valid_indexes]]
target[batch_indexes, actions] = updates
loss = self.primary_network.train_on_batch(states, target)
# Slowly update target network parameters from primary network
self.align_target_network()
return loss
首先,我们确保在经验回放缓冲区有足够的 数据 。如果我们有足够的数据,我们拿起 批次 的数据并把它分成数组。然后我们使用 Q-Network 或 _primary network_得到 Q(s,a) 和 Q(s',a') 。 之后,我们挑选动作并使用 Train Network 来预测 Q(s',a') 。我们为 目标 ,并使用它来训练 Q-网络。 最后,我们把 Q-网络 的值复制到 目标网络。
然而,这个 train 功能只是整个 训练 过程的一部分,所以我们在上面定义了一个结合了代理和环境的类, 驱动 整个过程 - AgentTrainer。 这是它的样子。
class AgentTrainer():
def __init__(self, agent, enviroment):
self.agent = agent
self.enviroment = enviroment
def _take_action(self, action):
next_state, reward, terminated, _ = self.enviroment.step(action)
next_state = next_state if not terminated else None
reward = np.random.normal(1.0, REWARD_STD)
return next_state, reward, terminated
def _print_epoch_values(self, episode, total_epoch_reward, average_loss):
print("**********************************")
print(f"Episode: {episode} - Reward: {total_epoch_reward} - Average Loss: {average_loss:.3f}")
def train(self, num_of_episodes = 1000):
total_timesteps = 0
for episode in range(0, num_of_episodes):
# Reset the enviroment
state = self.enviroment.reset()
# Initialize variables
average_loss_per_episode = []
average_loss = 0
total_epoch_reward = 0
terminated = False
while not terminated:
# Run Action
action = agent.act(state)
# Take action
next_state, reward, terminated = self._take_action(action)
agent.store(state, action, reward, next_state, terminated)
loss = agent.train(BATCH_SIZE)
average_loss += loss
state = next_state
agent.align_epsilon(total_timesteps)
total_timesteps += 1
if terminated:
average_loss /= total_epoch_reward
average_loss_per_episode.append(average_loss)
self._print_epoch_values(episode, total_epoch_reward, average_loss)
# Real Reward is always 1 for Cart-Pole enviroment
total_epoch_reward +=1
这个类有几个方法。第一个内部方法_take_action 是相当 有趣的。在这个方法中,我们使用构造函数中传递的环境来执行 定义的 行动。现在,有趣的部分是,我们通过改变它返回的奖励来改变Cart-Pole环境的性质。
更准确地说,这个环境是 确定性的,但我们希望它是 随机性的 ,因为 双DQN 在这种环境中表现得更好。由于奖励总是+1,我们用正态分布的样本来代替它。这就是我们使用之前提到的REWARD_STD 我们之前提到过。
在 train AgentTrainer 的方法中,我们为定义的epochs数量执行训练过程。该过程遵循双DQN算法的步骤。在每个历时中,我们选择一个动作,并在环境中执行 , 。
这给我们提供了必要的信息, 训练 代理和它的神经网络,之后我们得到 损失。最后,我们计算每个纪元的平均损失。好吧,当我们把它放在一起时,它看起来像这样。
optimizer = Adam()
expirience_replay = ExpirienceReplay(50000)
agent = DDQNAgent(expirience_replay, NUM_STATES, NUM_ACTIONS, optimizer)
agent_trainer = AgentTrainer(agent, enviroment)
agent_trainer.train()
这里是输出。
*******************************
Episode: 0 - Reward: 13 - Average Loss: 2.153
*******************************
Episode: 1 - Reward: 9 - Average Loss: 1.088
*******************************
Episode: 2 - Reward: 12 - Average Loss: 1.575
*******************************
Episode: 3 - Reward: 14 - Average Loss: 0.973
*******************************
Episode: 4 - Reward: 23 - Average Loss: 1.451
*******************************
Episode: 5 - Reward: 29 - Average Loss: 1.463
*******************************
Episode: 6 - Reward: 28 - Average Loss: 1.265
*******************************
Episode: 7 - Reward: 20 - Average Loss: 1.520
*******************************
Episode: 8 - Reward: 10 - Average Loss: 1.201
*******************************
Episode: 9 - Reward: 25 - Average Loss: 0.976
*******************************
Episode: 10 - Reward: 33 - Average Loss: 1.408
...
6.双DQN TF代理的实现
这个过程的TensorFlow实现并不复杂,但如果有一些可以使用的预制类,总是更容易。对于强化学习,我们可以使用 TF-Agent。在 **之前的一篇文章**中 ,我们看到如何使用这个工具来构建DQN系统。让我们看看我们如何做同样的事情,用TF-Agents建立Double DQN。
6.1 导入、全局和环境
同样,首先我们导入模块并定义常量。
import base64
import imageio
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
from tf_agents.agents.dqn.dqn_agent import DqnAgent, DdqnAgent
from tf_agents.networks.q_network import QNetwork
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.policies.random_tf_policy import RandomTFPolicy
from tf_agents.replay_buffers.tf_uniform_replay_buffer import TFUniformReplayBuffer
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Globals
NUMBER_EPOSODES = 20000
COLLECTION_STEPS = 1
BATCH_SIZE = 64
EVAL_EPISODES = 10
EVAL_INTERVAL = 1000
TF-Agents的一个很酷的地方是,它为我们提供了简单的方法来加载环境,而不需要安装 额外的 模块。这样,我们只需使用这个 生态系统 ,而不必担心丢失模块。下面是我们加载环境的方法。
train_env = suite_gym.load('CartPole-v0')
evaluation_env = suite_gym.load('CartPole-v0')
print('Observation Spec:')
print(train_env.time_step_spec().observation)
print('Reward Spec:')
print(train_env.time_step_spec().reward)
print('Action Spec:')
print(train_env.action_spec())
train_env = tf_py_environment.TFPyEnvironment(train_env)
evaluation_env = tf_py_environment.TFPyEnvironment(evaluation_env)
6.2 DQN和双DQN网络
因为我们想把DQN和Double DQN一起运行进行比较,所以我们创建了两个 Q-Networks。 下,这就创建了 目标网络 ,并 负责两个网络的维护 。
hidden_layers = (100,)
dqn_network = QNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=hidden_layers)
ddqn_network = QNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=hidden_layers)
6.3 DQN和Double DQN代理
一旦完成这些,我们就可以创建两个代理。第一个是用于 DQN ,另一个是用于 Double DQN。 TF-Agents 也为这个提供了 类。
counter = tf.Variable(0)
dqn_agent = DqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
q_network = dqn_network,
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=1e-3),
td_errors_loss_fn = common.element_wise_squared_loss,
train_step_counter = counter)
ddqn_agent = DdqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
q_network = ddqn_network,
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=1e-3),
td_errors_loss_fn = common.element_wise_squared_loss,
train_step_counter = counter)
dqn_agent.initialize()
ddqn_agent.initialize()
这些对象被初始化为有关训练 环境、 _QNetwork_对象 和 优化器的信息 。最后,我们 必须 对它们 调用 初始化 方法。我们在此基础上再实现一个函数-- get_average_return。这个方法计算出代理 平均获得了 多少重词 。
def get_average_reward(environment, policy, episodes=10):
total_reward = 0.0
for _ in range(episodes):
time_step = environment.reset()
episode_reward = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_reward += time_step.reward
total_reward += episode_reward
avg_reward = total_reward / episodes
return avg_reward.numpy()[0]
6.4 经验回放
到目前为止,一切都很好。现在,我们建立系统的最后部分-- 经验回放。
class ExperienceReplay(object):
def __init__(self, agent, enviroment):
self._replay_buffer = TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=enviroment.batch_size,
max_length=50000)
self._random_policy = RandomTFPolicy(train_env.time_step_spec(),
enviroment.action_spec())
self._fill_buffer(train_env, self._random_policy, steps=100)
self.dataset = self._replay_buffer.as_dataset(
num_parallel_calls=3,
sample_batch_size=BATCH_SIZE,
num_steps=2).prefetch(3)
self.iterator = iter(self.dataset)
def _fill_buffer(self, enviroment, policy, steps):
for _ in range(steps):
self.timestamp_data(enviroment, policy)
def timestamp_data(self, environment, policy):
time_step = environment.current_time_step()
action_step = policy.action(time_step)
next_time_step = environment.step(action_step.action)
timestamp_trajectory = trajectory.from_transition(time_step, action_step, next_time_step)
self._replay_buffer.add_batch(timestamp_trajectory)
首先,我们在类的构造函数中初始化重放缓冲区 。这是类_TFUniformReplayBuffer_的一个对象。如果你的代理表现不佳,你可以改变缓冲区的 批量大小和长度 的值。除此之外,我们创建一个_RandomTFPolicy_的实例。这个对象 ,用初始值填充 缓冲区。这个过程是由__fill_buffer_方法发起的。
这个方法为环境的每个状态调用_timestamp_data_方法,这又从当前状态和策略定义的行动中形成轨迹 。这个轨迹是状态、行动和下一个时间戳的元组,它被 ,并 存储在缓冲区中。构造器的最后一步是创建一个可迭代的tf.data.Dataset 管道,将数据输送 给代理。
最后,我们可以在 训练 函数中结合所有这些元素。
def train(agent):
experience_replay = ExperienceReplay(agent, train_env)
agent.train_step_counter.assign(0)
avg_reward = get_average_reward(evaluation_env, agent.policy, EVAL_EPISODES)
rewards = [avg_reward]
for _ in range(NUMBER_EPOSODES):
for _ in range(COLLECTION_STEPS):
experience_replay.timestamp_data(train_env, agent.collect_policy)
experience, info = next(experience_replay.iterator)
train_loss = agent.train(experience).loss
if agent.train_step_counter.numpy() % EVAL_INTERVAL == 0:
avg_reward = get_average_reward(evaluation_env, agent.policy, EVAL_EPISODES)
print('Episode {0} - Average reward = {1}, Loss = {2}.'.format(
agent.train_step_counter.numpy(), avg_reward, train_loss))
rewards.append(avg_reward)
return rewards
print("**********************************")
print("Training DQN")
print("**********************************")
dqn_reward = train(dqn_agent)
print("**********************************")
print("Training DDQN")
print("**********************************")
ddqn_reward = train(ddqn_agent)
当我们运行该函数时,输出看起来像这样。
**********************************
Training DQN
**********************************
Episode 1000 - Average reward = 2.700000047683716, Loss = 95.45304870605469.
Episode 2000 - Average reward = 2.299999952316284, Loss = 41.39720916748047.
Episode 3000 - Average reward = 3.799999952316284, Loss = 34.7718620300293.
Episode 4000 - Average reward = 5.599999904632568, Loss = 123.10957336425781.
Episode 5000 - Average reward = 8.100000381469727, Loss = 171.66470336914062.
Episode 6000 - Average reward = 15.899999618530273, Loss = 209.91107177734375.
Episode 7000 - Average reward = 20.0, Loss = 130.32858276367188.
Episode 8000 - Average reward = 20.0, Loss = 14.633146286010742.
Episode 9000 - Average reward = 20.0, Loss = 188.2078857421875.
Episode 10000 - Average reward = 20.0, Loss = 31.698490142822266.
Episode 11000 - Average reward = 20.0, Loss = 306.1351013183594.
...
**********************************
Training DDQN
**********************************
Episode 1000 - Average reward = 1.0, Loss = 0.6193162202835083.
Episode 2000 - Average reward = 5.699999809265137, Loss = 6.596433639526367.
Episode 3000 - Average reward = 7.699999809265137, Loss = 16.949800491333008.
Episode 4000 - Average reward = 6.699999809265137, Loss = 19.932825088500977.
Episode 5000 - Average reward = 20.0, Loss = 4.6859331130981445.
Episode 6000 - Average reward = 20.0, Loss = 5.8436055183410645.
Episode 7000 - Average reward = 20.0, Loss = 44.722599029541016.
Episode 8000 - Average reward = 20.0, Loss = 98.11009979248047.
Episode 9000 - Average reward = 20.0, Loss = 11.548649787902832.
Episode 10000 - Average reward = 20.0, Loss = 147.0045623779297.
Episode 11000 - Average reward = 14.5, Loss = 321.64013671875.
...
最后,我们可以 绘制 两个代理的平均奖励。

我们可以看到,Double DQN更快地创建了更好的策略,并达到了稳定状态。
总结
在这篇文章中,我们有机会看到我们如何使用Double Q-Learning的概念来丰富DQN算法并创建Double DQN。除此之外,我们还有机会使用TensorFlow和TF-Agents来实现这个算法。
谢谢您的阅读!
这套电子书是专门为 初学者设计的。
,从Python基础知识到机器学习算法在生产中的部署,一切都在这里。
,今天就成为机器学习的超级英雄 !

Nikola M. Zivkovic
Nikola M. Zivkovic是 书籍的作者。 机器学习终极指南 和 面向程序员的深度学习.他热爱知识分享,是一位经验丰富的演讲者。你可以看到他在 聚会、会议上发言 ,并在诺维萨德大学担任客座讲师。
