

摘要
卷积是一种基本的数学运算,被用于当今许多领域,包括信号处理、图像处理、概率、统计等。当然,由于它的广泛使用,改进的应用已经被开发出来。因此,当务之急是深入了解它的各种应用方式。本文旨在解释卷积和它在NN方面可能的应用方式,具体来说就是CNN。
目录
- 卷积简介
- 分组卷积
- 实施
- 洗牌的分组卷积
- 实施
- 优势和劣势
- 总结
卷积简介
在数学中,卷积是对两个函数的数学运算,产生第三个函数,表达一个函数的形状如何被另一个函数改变。
在数学上这被表述为。

现在我们将在matlab中一步步地计算探索这个公式的含义。
考虑两个随机生成的函数,用数组vec1 和vec2 表示。
我们可以通过以下方式对这些函数进行卷积。
- 第1步 - 翻转第二个函数 (
flip_vec2) - 第2步 - 从
vec1和flip_vec2的1个元素开始,水平移动flip_vec2,直到没有其他元素可以被对齐。在每次移位时,将对齐的元素相乘。
得到的向量是vec1和vec2的全卷积,可以用以下方法计算:
vec1 = randi([-10, 10], 1, 5)
vec2 = randi([-10, 10], 1, 5)
l1 = length(vec1);
l2 = length(vec2);
full_len = l1 + l2 - 1;
conv_full = zeros(1, full_len);
% step 1
flip_vec2 = fliplr(vec2);
% step 2
for i = 1:full_len
if i <= l1
conv_full(i) = sum(vec1(1:i).*flip_vec2(l2 + 1 -i:l2));
else
j = l1 + l2 - i;
conv_full(i) = sum(vec1(l1 + 1 - j:l1).*flip_vec2(1:j));
end
end
conv_full
如果我们说函数vec1 和vec2 的长度是m 和n ,那么全卷的长度将是 。m + n - 1
对于一个测试案例,卷积可以用图形化的方式表示为
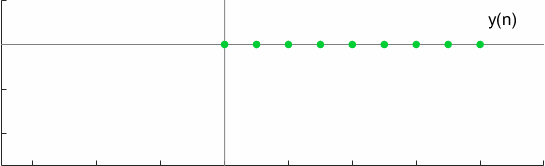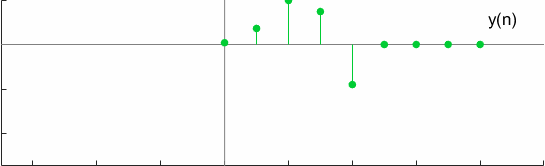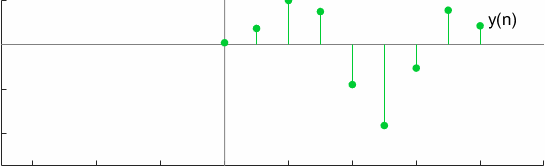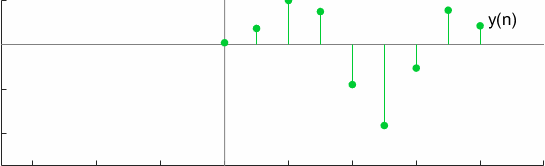
全卷积的另一个有趣的属性是换元性,这可以通过以下方式验证:
l1 = randi([1, 10]);
l2 = randi([1, 10]);
vec1 = randi([-10, 10], 1, l1);
vec2 = randi([-10, 10], 1, l2);
conv_full_12 = conv(vec1, vec2, 'full');
conv_full_21 = conv(vec2, vec1, 'full');
if conv_full_12 == conv_full_21
disp('Full convolution is commutative')
end
在卷积的应用角度,找到对应于较少对齐的移位的卷积元素的信息量较小。当我们过滤全卷积结果,只考虑那些小函数的所有元素与大函数完全对齐的元素,我们称之为有效卷积。
如果我们说函数vec1 和vec2 的长度是m 和n ,那么有效卷积的长度将是。m - n + 1
此外,由于我们知道大函数永远不可能与小函数完全对齐,有效卷积不是共轭的:
conv_valid_12 = conv(vec1, vec2, 'valid')
conv_valid_21 = conv(vec2, vec1, 'valid')
if conv_full_12 ~= conv_full_21
disp('Valid convolution is NOT commutative')
end
相应的维度属性可以扩展到更高的维度。
对于随机生成的矩阵(2d),也可以用matlab来完成:
A_rand = 10*rand(3, 3);
A = round(A_rand, 0);
% creating a symmetric matrix from an unsymmetric one
k_2d = A.*A'
B_rand = 10*rand(8, 8);
M = round(B_rand, 0)
conv_res_valid = conv2(M, k_2d, 'valid')
这里需要注意的是,所有用于图像特征提取的核都是对称的。在线性代数中,对称矩阵是一个等于其转置的方形矩阵。
使用对称核是为了跳过翻转操作,2d中的翻转操作只不过是转置。
在这一点上,最好是玩玩不同的内核设置,并观察样本图像文件的结果:
I = imread('lenna_grey.png');
imshow(I)
img_dim = size(I)
M_img = im2double(I)
A_rand = randi([-5,5],3, 3);
A = round(A_rand, 0);
k_2d = A.*A'
conv_res_valid_M = conv2(M_img, k_2d, 'valid');
norm_img = normalize(conv_res_valid_M);
imshow(norm_img)
原始图像文件'lenna_grey.png'

在一个测试案例中可以看到所产生的内核的独特特征识别。

有了对卷积的透彻理解,我们就可以继续进行CNN中卷积的精彩组合应用了。
分组卷积
分组卷积是一种技术,它将许多卷积结合到一个单层中,导致每层有许多通道输出。
有时也被称为过滤器组,使用组卷积的概念是在2012年的AlexNet论文中提出的。这项技术的驱动力是需要在GPU RAM限制下训练一个网络。其核心概念是创造并行性,以减少单点负荷,从而减少对HPC的需求。
从本质上讲,在相同的输入图像上应用不同的内核,并引导它通过同等数量的路径(大于1),这些路径并行地训练和反向传播。
为了说明这一点,请看下面这个在AlexNet中使用的2条路径的模型
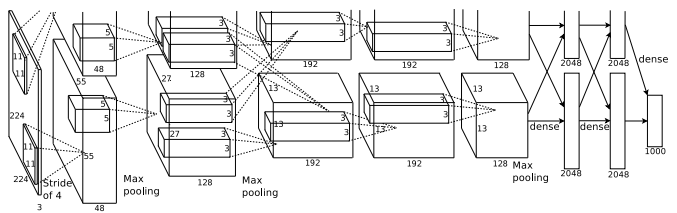
相当明显的是,我们不想对模型的性能进行补偿,同样,我们看到这种技术也带来了准确性的提高。
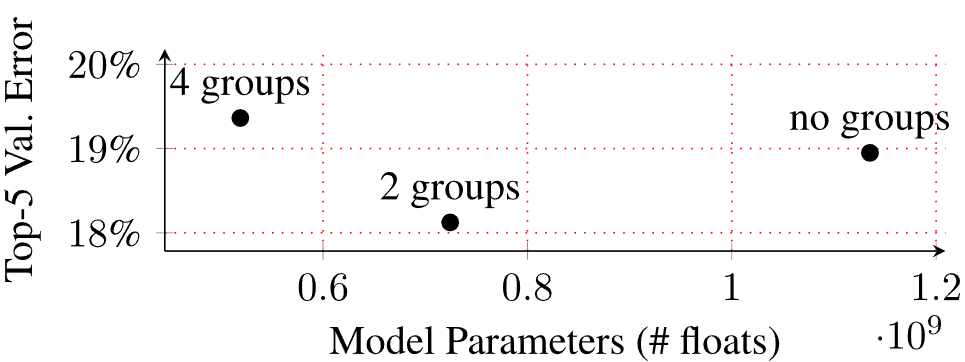
观察上面的图片,有2个组的模型与没有组的模型相比,误差值明显要低。
除了简单的模型评估指标外,组卷积的学习表现也更好。非主观性被以下发现所证明。

上图显示了2个独立组中的48个内核的学习信息,相应地在不同的GPU上训练(比如说像AlexNet中的GPU 1和GPU 2)。不同的GPU在黑白和彩色信息方面都有明显的区别。
组卷积的使用将各个数据流凝聚成一个,这可以通过以下方式理解。
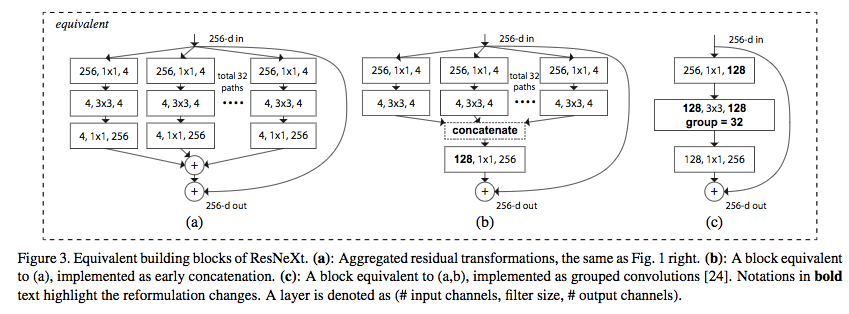
最后,我们还可以注意到,并行化以两种方式发生。
-
数据并行化。当数据集被分成几部分,并对每个块进行训练。每个块可以被认为是迷你批次梯度下降算法中的一个小批次。更多的数据平行性可以从更小的比特中挤出来。
-
模型并行化。模型并行是一种分布式训练策略,它将深度学习模型划分在众多设备上,在实例内部或实例之间。
博客中强调的另一个有趣的特征是,在CIFAR-10上训练的网中网模型中,相邻层的过滤器之间的关联性趋于一致。
实施
逻辑
首先,必须随机或基于EDA决定基本的NN架构参数。当试图实现分组卷积时,这也将包括决定模型将学习的组/信息通道的数量。然后采取以下行动来创建分组卷积过程。
- 每个组都被分配了不同的内核,它将用于卷积输入。
- 确保这组核被应用于同一层,以便从每个抽象层次上进行不同的学习。
- 现在,CNN的这一特定层可以通过使用相同的输入并将输出分成各自的通道而在逻辑上组合起来。
现在将讨论实现同样的代码。
代码
为了方便创建NN模型,我们从使用matlab过渡到使用python。下面的类构成了创建分组卷积ResNeXt模型的核心部分:
class ResNeXtBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, stride, cardinality, base_width, widen_factor):
""" Constructor
Args:
in_channels: input channel dimensionality
out_channels: output channel dimensionality
stride: conv stride. Replaces pooling layer.
cardinality: num of convolution groups.
base_width: base number of channels in each group.
widen_factor: factor to reduce the input dimensionality before convolution.
"""
super(ResNeXtBottleneck, self).__init__()
width_ratio = out_channels / (widen_factor * 64.)
D = cardinality * int(base_width * width_ratio)
self.conv_reduce = nn.Conv2d(in_channels, D, kernel_size=1, stride=1, padding=0, bias=False)
self.bn_reduce = nn.BatchNorm2d(D)
self.conv_conv = nn.Conv2d(D, D, kernel_size=3, stride=stride, padding=1, groups=cardinality, bias=False)
self.bn = nn.BatchNorm2d(D)
self.conv_expand = nn.Conv2d(D, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.bn_expand = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if in_channels != out_channels:
self.shortcut.add_module('shortcut_conv',
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0,
bias=False))
self.shortcut.add_module('shortcut_bn', nn.BatchNorm2d(out_channels))
def forward(self, x):
bottleneck = self.conv_reduce.forward(x)
bottleneck = F.relu(self.bn_reduce.forward(bottleneck), inplace=True)
bottleneck = self.conv_conv.forward(bottleneck)
bottleneck = F.relu(self.bn.forward(bottleneck), inplace=True)
bottleneck = self.conv_expand.forward(bottleneck)
bottleneck = self.bn_expand.forward(bottleneck)
residual = self.shortcut.forward(x)
return F.relu(residual + bottleneck, inplace=True)
洗牌的分组卷积
在卷积神经网络中,通道洗牌是一个有助于组合决定特征通道之间信息流的操作,当信息来自于应用分组卷积时,这个过程被称为洗牌分组卷积。
分组卷积的使用带来了不同的学习片段。每一个单独的片段都有基于内核的独特的学习信息,可以与连续的层互换结合。这个概念是在2017年发表的ShuffleNet中首次设想的。
这个概念可以形象化为:
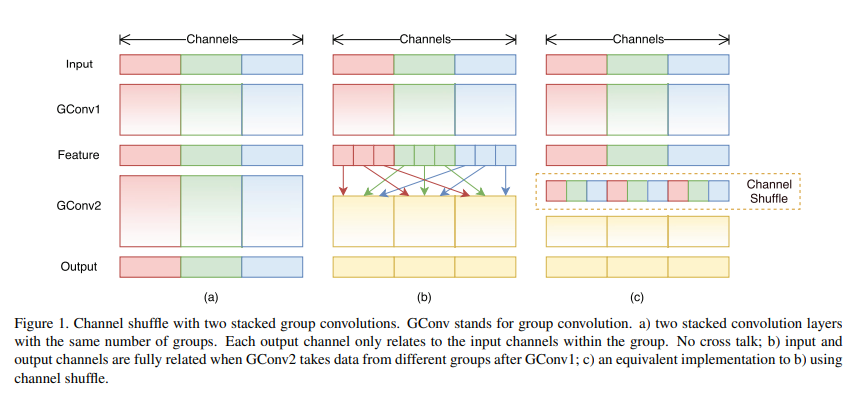
这种类型的组合模型往往能提供更好的准确性,这一点在ShuffleNet的以下结果中得到了验证。
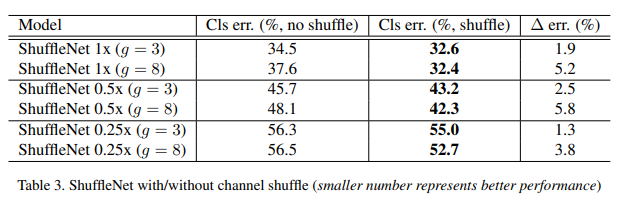
此外,本文将ShuffleNet模型与其他极具竞争力的模型进行了比较,其结果为。

实施
逻辑
当然,在进入洗牌通道信息之前,需要实现分组卷积,这是由。
- 选择要交换的信息段的组合,通常是统一的,即连续层的每个通道从上一层的每个通道获得一个相等的信息段。
- 这样一来,后续层的输入就按照决定的组合适当地创建了。
现在我们将讨论实现同样的代码。
代码
一个基线的Shuffle网块功能可以在python中实现:
class ShuffleInitBlock(nn.Module):
"""
ShuffleNet specific initial block.
Parameters:
----------
in_channels : int
Number of input channels.
out_channels : int
Number of output channels.
"""
def __init__(self,
in_channels,
out_channels):
super(ShuffleInitBlock, self).__init__()
self.conv = conv3x3(
in_channels=in_channels,
out_channels=out_channels,
stride=2)
self.bn = nn.BatchNorm2d(num_features=out_channels)
self.activ = nn.ReLU(inplace=True)
self.pool = nn.MaxPool2d(
kernel_size=3,
stride=2,
padding=1)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activ(x)
x = self.pool(x)
return x
class ShuffleNet(nn.Module):
"""
ShuffleNet model from 'ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,'
https://arxiv.org/abs/1707.01083.
Parameters:
----------
channels : list of list of int
Number of output channels for each unit.
init_block_channels : int
Number of output channels for the initial unit.
groups : int
Number of groups in convolution layers.
in_channels : int, default 3
Number of input channels.
in_size : tuple of two ints, default (224, 224)
Spatial size of the expected input image.
num_classes : int, default 1000
Number of classification classes.
"""
def __init__(self,
channels,
init_block_channels,
groups,
in_channels=3,
in_size=(224, 224),
num_classes=1000):
super(ShuffleNet, self).__init__()
self.in_size = in_size
self.num_classes = num_classes
self.features = nn.Sequential()
self.features.add_module("init_block", ShuffleInitBlock(
in_channels=in_channels,
out_channels=init_block_channels))
in_channels = init_block_channels
for i, channels_per_stage in enumerate(channels):
stage = nn.Sequential()
for j, out_channels in enumerate(channels_per_stage):
downsample = (j == 0)
ignore_group = (i == 0) and (j == 0)
stage.add_module("unit{}".format(j + 1), ShuffleUnit(
in_channels=in_channels,
out_channels=out_channels,
groups=groups,
downsample=downsample,
ignore_group=ignore_group))
in_channels = out_channels
self.features.add_module("stage{}".format(i + 1), stage)
self.features.add_module("final_pool", nn.AvgPool2d(
kernel_size=7,
stride=1))
self.output = nn.Linear(
in_features=in_channels,
out_features=num_classes)
self._init_params()
def _init_params(self):
for name, module in self.named_modules():
if isinstance(module, nn.Conv2d):
init.kaiming_uniform_(module.weight)
if module.bias is not None:
init.constant_(module.bias, 0)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.output(x)
return x
def get_shufflenet(groups,
width_scale,
model_name=None,
pretrained=False,
root=os.path.join("~", ".torch", "models"),
**kwargs):
"""
Create ShuffleNet model with specific parameters.
Parameters:
----------
groups : int
Number of groups in convolution layers.
width_scale : float
Scale factor for width of layers.
model_name : str or None, default None
Model name for loading pretrained model.
pretrained : bool, default False
Whether to load the pretrained weights for model.
root : str, default '~/.torch/models'
Location for keeping the model parameters.
"""
init_block_channels = 24
layers = [4, 8, 4]
if groups == 1:
channels_per_layers = [144, 288, 576]
elif groups == 2:
channels_per_layers = [200, 400, 800]
elif groups == 3:
channels_per_layers = [240, 480, 960]
elif groups == 4:
channels_per_layers = [272, 544, 1088]
elif groups == 8:
channels_per_layers = [384, 768, 1536]
else:
raise ValueError("The {} of groups is not supported".format(groups))
channels = [[ci] * li for (ci, li) in zip(channels_per_layers, layers)]
if width_scale != 1.0:
channels = [[int(cij * width_scale) for cij in ci] for ci in channels]
init_block_channels = int(init_block_channels * width_scale)
net = ShuffleNet(
channels=channels,
init_block_channels=init_block_channels,
groups=groups,
**kwargs)
if pretrained:
if (model_name is None) or (not model_name):
raise ValueError("Parameter `model_name` should be properly initialized for loading pretrained model.")
from .model_store import download_model
download_model(
net=net,
model_name=model_name,
local_model_store_dir_path=root)
return net
优点和缺点
优点
分组卷积
- NN模型的宽度限制被移除
- 即时的多角度特征提取允许更高水平的信息捕获
- 平行性允许使用更少的计算资源
- 提高了整体精度和分段学习的区分度
洗牌组卷积
利用组合训练来提高:
- 模型训练
- 模型资源的使用
- 模型性能
缺点
- 整合这些方面需要很好的概念和计算的掌握
- 模型的先决条件将需要仔细的EDA和中间测试
- 由于其复杂性,调试模型的不完善将是困难的
总结
通过对卷积、分组卷积和洗牌分组卷积的完整理解,人们将能够极大地理解
现代CNN研究的细微差别和复杂性。这种复杂但逻辑上优雅的方法的应用所带来的抽象程度可以被打破,并且可以体验到基本数学运算的真正美感及其相关影响。
除了理论上的装饰,认知能力的提高也是通过努力尝试成功实现所讨论的概念而带来的。
参考文献
- 对二维和三维卷积程序和可视化的全面理解可以在卷积神经网络(CNN)中找到。
- CIFAR-10和CIFAR-100的完整代码可以在ResNeXt找到。
- 大量的模型可以从imgclsmob中找到,洗牌组卷积代码就是从那里得到的。
