

在R中分析秒数
所以,这是我为需要统计帮助的人做的一个项目,处理高密度的临床数据。确切地说,是灌注数据。现在,这个项目的目标是看某些测量肺部和心脏容量的方法是否会导致相同的临床决策。这意味着在或排除用于确定该临床相关性的公式中的特定参数。你不需要了解研究领域,仍然可以理解我所做的事情,但为了简单起见,我将添加一些图表,显示某些肺部参数、能量产生和乳酸之间的关系。临床灌注师的关键任务是跟踪病人的饱和度水平(以及更多),以确定他/她保持在有氧能量生产的状态。
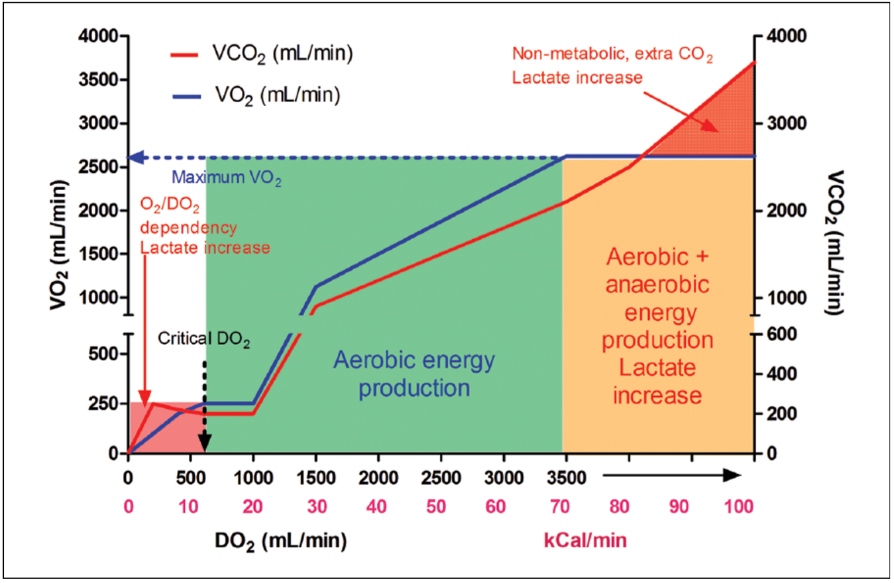
所关注的参数有
- 供氧量*(DO2*)
- 耗氧量*(VO2*)
- 二氧化碳的产生*(VCO2)*
- 氧气提取率*(VO2/DO2*)
- 呼吸系数*(VCO2/VO2*)
一起,再加上包括许多其他指标,你可以跟踪一个人的能量产生和乳酸的存在。


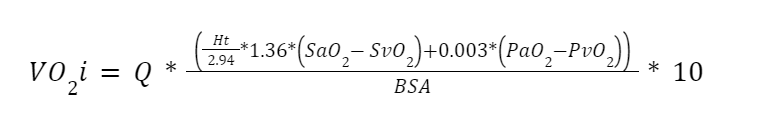
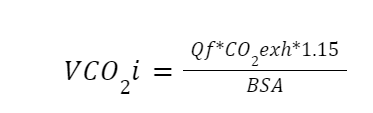

与本研究有关的公式。RQ 指的是呼吸系数,BPTS 代表体温(37℃)、环境压力和水蒸气饱和的气体。BSA 指体表面积。
因为这是实际的临床数据,我不能与你分享,但我要做的是尽可能地描述这些数据。特别是它的颗粒度,因为这正是这个数据最有趣的地方。我们在这里处理的是秒。对我来说,如何处理这种数据,是这篇博文的目的。我希望它能给你带来启发,你会喜欢它。
让我们开始吧,并从中获得一些乐趣!
然后我开始加载数据,这比平时更麻烦,所以我需要预先指定包括的类型。我还必须对数据进行转换,以便以一种更简洁的方式来看待它。
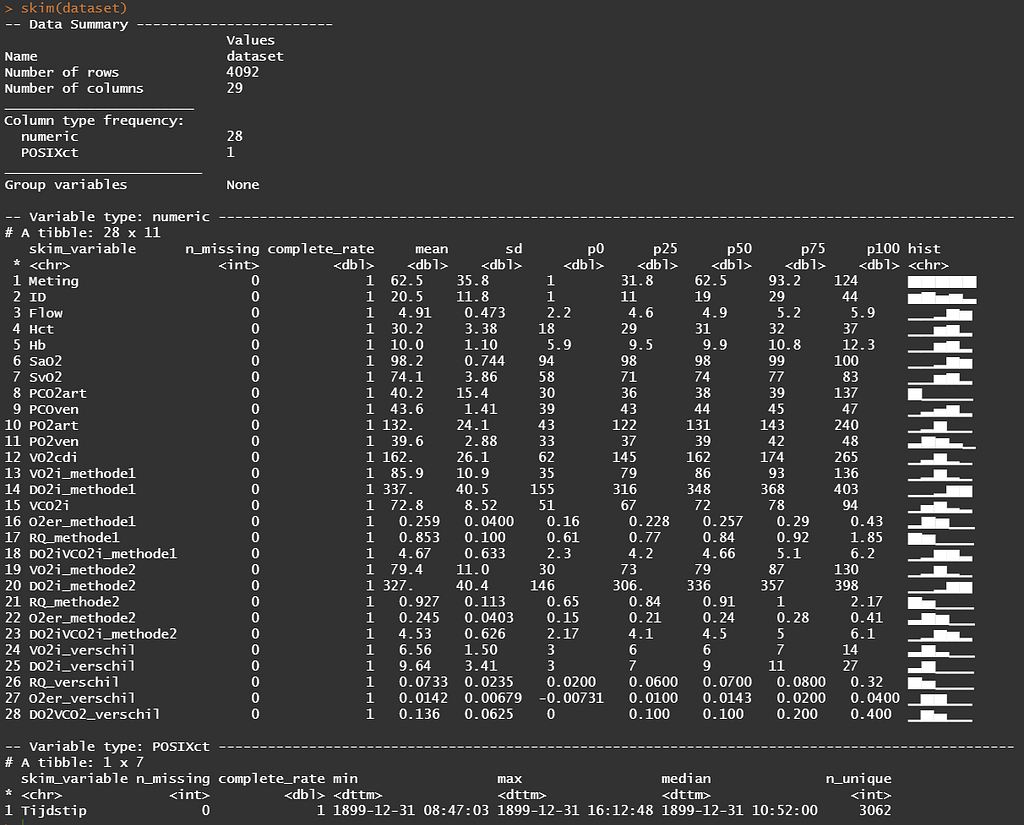
在这个概述中,你可以看到,几乎每个感兴趣的参数都有两种方法。正是这两种方法之间的区别是本研究的兴趣所在。
然而,在这篇文章中,我们感兴趣的不是区别,而是收集数据的颗粒度。我们在这里讨论的是以秒为单位的数据,而不是分钟、天、周、月或年。秒。

正如你所看到的,我们有44个病人和他们在不同时期的测量结果。当然,把它们画在一起并没有什么帮助,因为它们不是在同一时间开始的。因此,我需要对它们进行同步。

现在,它们已经同步了,但对于流量 指标来说,看起来并不太令人印象深刻。

每个病人的原始数据。

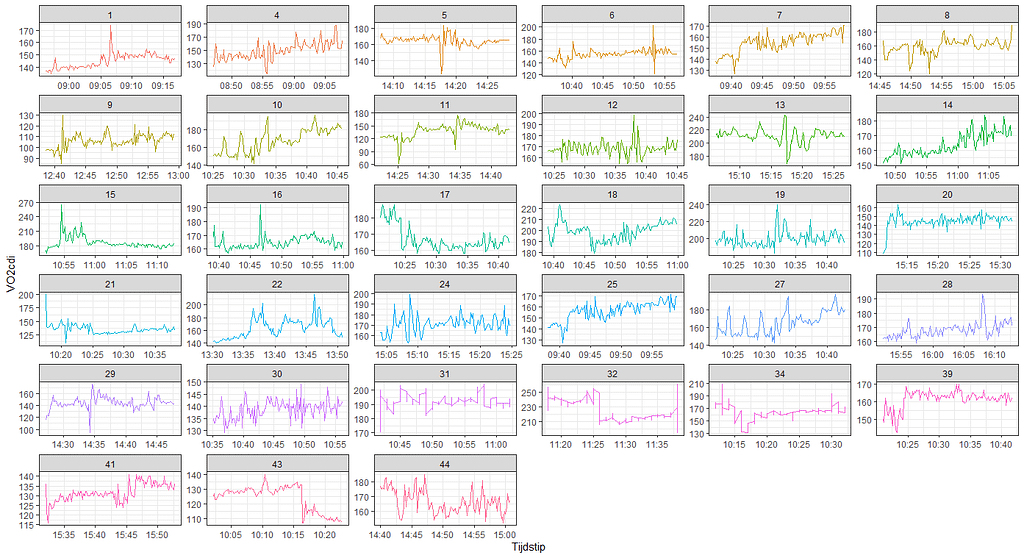
将它们分别绘制成图,可以看出数据真的很好。虽然不是对每个病人,也不是对每个指标(这个指标显示的是VO2cdi),但在这种粒度水平上看临床数据还是很有乐趣的。

还有一个在基础数据上叠加的图表。发生了很多事情,如果有信号的话,破译基础变化和找到信号将是很重要的。
时间序列转换,但并没有真正做什么,或者至少没有提供多少信息。
现在,时间变量在同一尺度上,但正在发生的事情却没有在同一维度上发生,这使得它们无法比较。换句话说,我无法比较这44个病人的曲线。因此,我所做的是建立一个变量,显示经过的时间。你可以看到我在这里开始绘制该数据*(你已经可以看到我在前面的绘图中进行了尝试,但不是每个指标都真正有趣*)。从每个病人身上,我们将获得124个测量点。


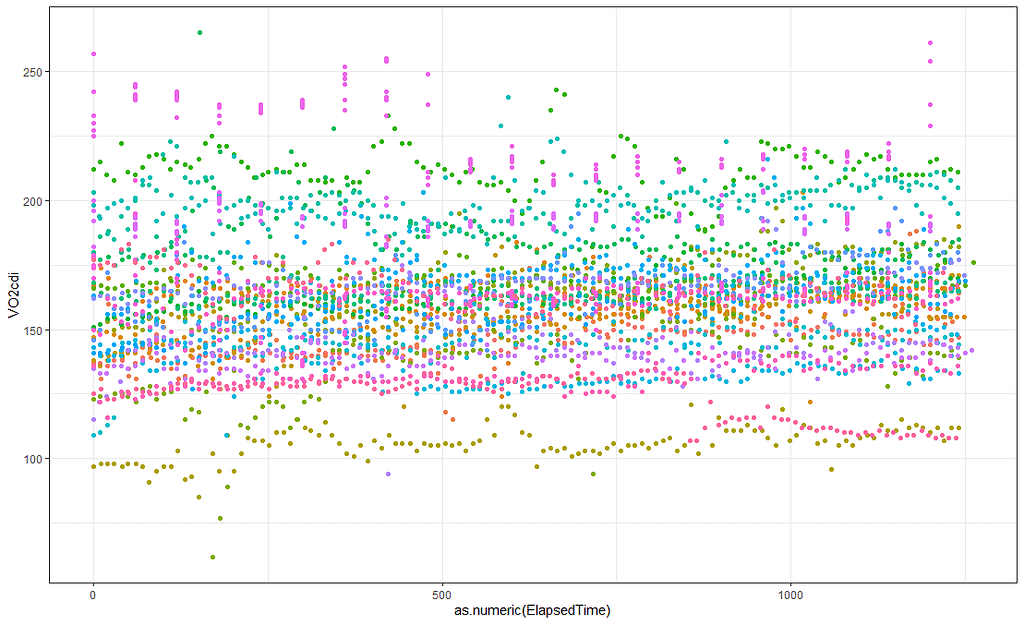
同样的数据,但是以线和点的形式,显示了VO2cdi的模式,随着时间的推移,每个病人。
记得我在开始时说过,这项研究的重要性在于评估在用于确定某种形式的临床相关性的测量中增加特定参数的重要性。因此,根据文献和本研究的目的,我建立了一些变量,以显示一个测量值何时超出其临床相关的界限。这些不是 离群值,尽管人们可以称之为异常值。然而,我们不使用一些统计学上的异常检测,而只是使用文献中确定的临床阈值来标记它们。

不要忘记,标度是自由的,我在原始数据(而不是经过的时间)上绘制了它们。红色 表示在边界内,蓝色 表示在边界外。你可以看到的是,几乎每个病人都肯定会超出其边界,这是由这个变量及其临床相关性决定的。




当然,我们也可以开始结合某些测量方法及其临床相关性的参数
现在,研究的真正内容是通过不同的测量参数来确定差异。特别是在临床相关性方面,因为如果测量的差异改变了临床决策,就会变得非常有问题。
下面,你看到两种测量VO2的方法,以多种方式描述。目的是分析如果你使用一种或另一种方法,对临床决策的影响。

Boxplot显示使用两种方法测量VO2 的数值分布。可以清楚地看到方法2**(深绿色**)提供的数值比方法1**(红色**)高很多。这里面有一个相互作用,因为每个病人的差异是不一样的。
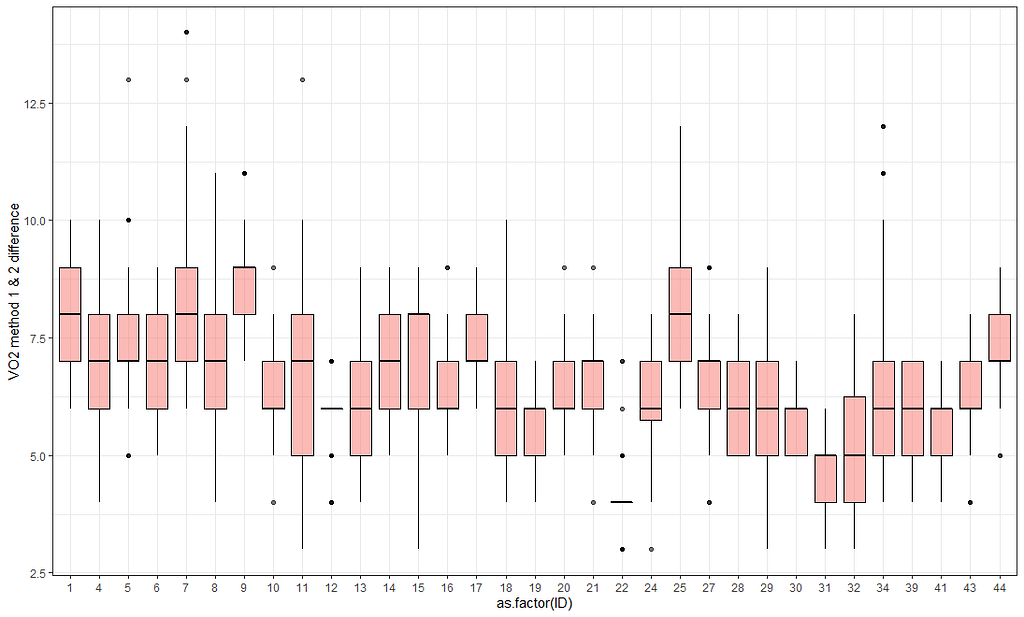
还有显示每个病人的差异分布的图。我们知道每个病人有124个观察值,而且没有缺失数据出现。因此,如果不存在交互作用,那么所有的变化都是一样的。但事实并非如此,这意味着数据的变化和数值本身影响着差异。
g1<-ggplot(dataset, aes(x=ElapsedTime,

左边是两种方法的VO2 测量值,按每个ID 的耗时计算。右边是平滑差异的一种时髦方法。
展示任何种类的差异的另一种方法是以热图的形式绘制它们。现在,如果我使用ElapsedTime 创建一个热图*,我* 将得到一个有很多空白的热图。因此,我将削减数据,然后绘制差异。
options(scipen=999)
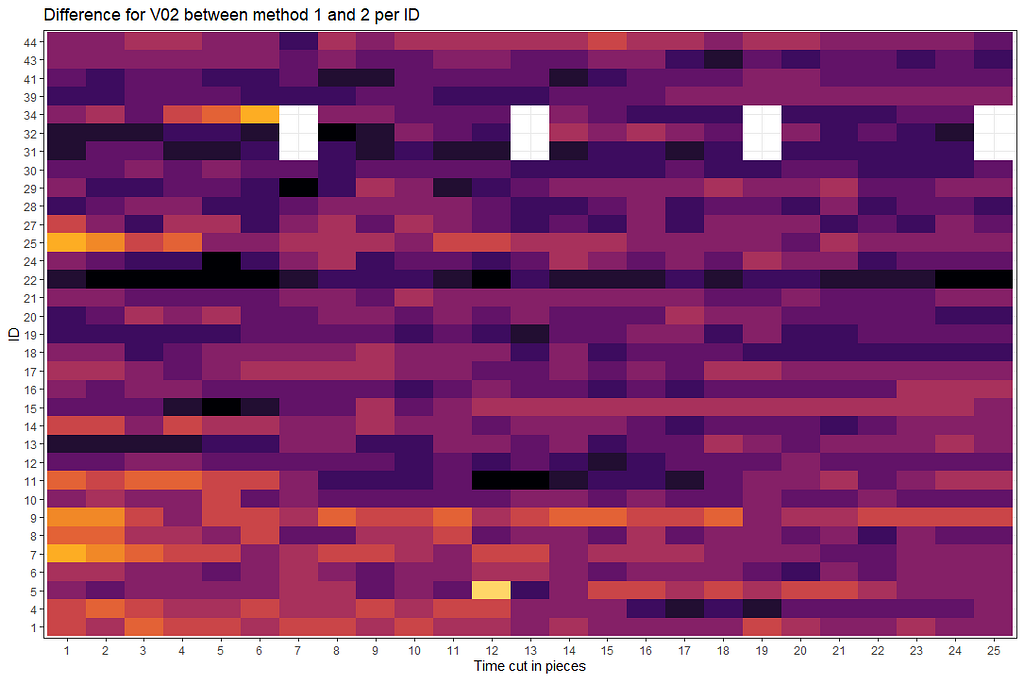
正如你所看到的,每个时间和每个ID的差异是不一样的。在某些情况下,我们似乎没有差异,但对于大多数人来说,差异是不稳定的。因此,临床决策很可能会受到影响。
GGplot有一个奇怪的方法来尝试添加两个Y轴:要么你通过网格 或做某种形式的组合。 gridExtra的方式进行某种形式的组合,或者你在 GGplot 来让第二条轴为你工作。 格子图 有一个更直接的方法,通过创建对象 xyplot 创建对象,然后将它们合并在一起。
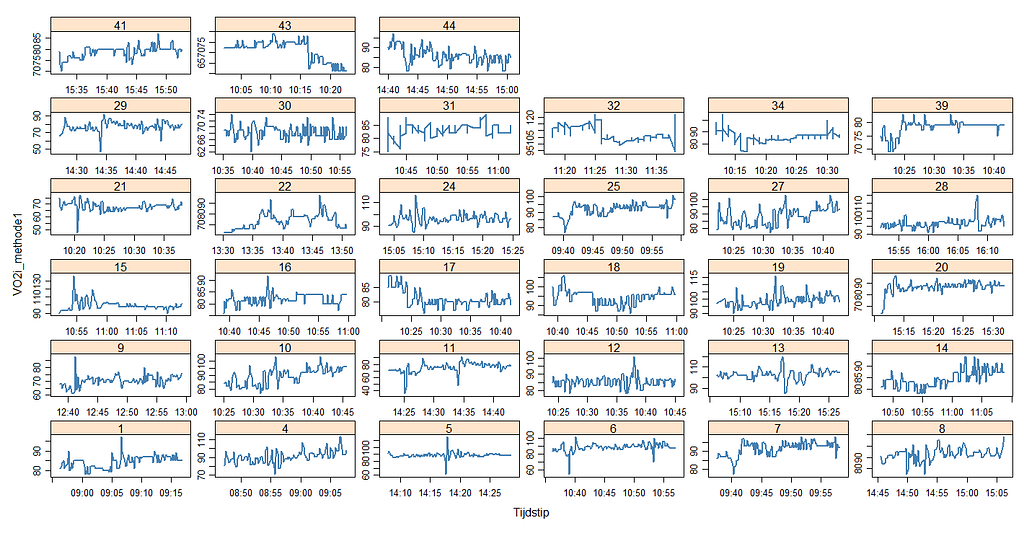


方法1,2,以及通过Lattice做的三个对象的区别。

在lattice中,这些对象可以被漂亮地合并。看看方法上的差异就知道了。这是很严重的。
现在,如果你想检查一个变量对一个指标的影响,你可以应用蒙特卡洛模拟来了解这种影响。我们要做的是拿着这两个公式,看看它们的结构,然后自己玩玩这些变量。从这个练习中,我们可以得到一个估计,即通过改变构成结果的组成部分,结果会有什么变化。所以,让我们看看这对我们现在已经使用了多次的二氧化硫 是如何工作的。
VO2 的标准公式是这样的。

VO2i = geïndexeerde耗氧量(ml-min-1-m-2);Q = 动脉血流量(L-min-1);Ht = 血细胞(%);SaO2 en SvO2 = 动脉和静脉饱和度(-);PaO2 en PvO2 = 动脉和静脉
氧张力(mmHg);BSA =身体表面Dubois formule(m2)。
方法1和方法2的区别在于包含/或排除了PaO2 和PvO2,因此分子的后半部分也是如此。让我们通过应用蒙特卡洛模拟来看看该变量的影响。
mean(dataset$Flow) # 4.9
VO2_1 <- function(Q, Ht, SaO2, SvO2, PaO2, PvO2, BSA) {
我们最终发现方法1和方法2的VO2 分别为85和79,四舍五入。方法2不包含PaO2 和PvO2。因此,这些是要模拟的函数,以看一看它们的影响。为了做到这一点,我将把其余部分保持在最低水平。我确信这也会有影响,但为了争论起见,让我们保持这种方式。现在开始模拟。
summary(dataset$PO2art) # range: 43 - 240

提取的数据集。
ggplot(df, aes(x=PaO2,

得到的图表显示了PaO2 和PvO2之间的相互影响。可以肯定的是,它们的存在确实影响了VO2的指标,因此也影响了临床决策。
从上面可以看出,这两个值的存在或不存在都会影响结果VO2。事实上,这个数据集中的大多数指标都是相互影响的。这提供了另一个机会,即对数据进行时间序列分析,寻找协整→一个时间序列对另一个时间序列的影响。我在研究Covid-19数据和锁定等措施的影响之前,已经应用了这样一种方法。
首先,让我们从小事做起,看看有哪些不同的方法可以对数据有更多的把握。
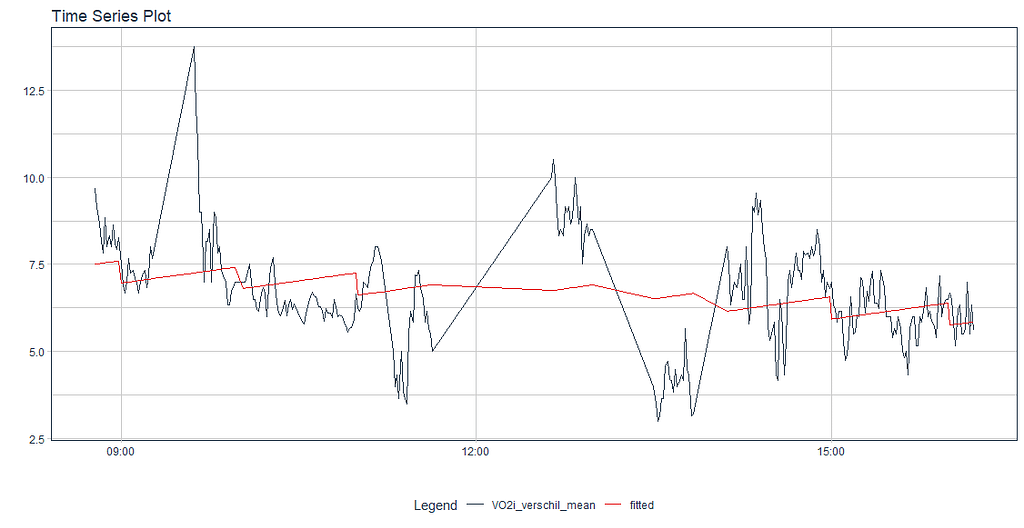
一个显示VO2 措施的平均差异的图,以及一个拟合模型。除了说明差异可能相当大,但不一定非得如此之外,并没有真正向我们展示什么。BTW,这是一个整体的时间序列。
dataset%>%dplyr::filter(ID=="1")%>%
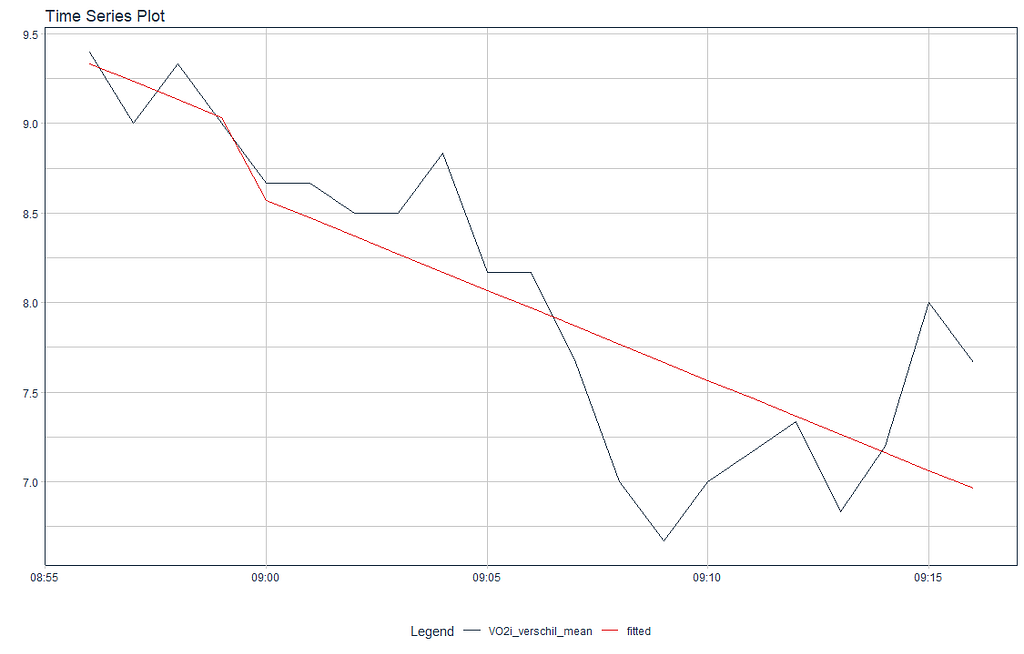
一个人的时间序列对象
让我们创建一个包含多个时间序列的时间序列对象。从这个对象中,我们可以绘制一系列非常好的东西。为了使数据更容易理解,我现在将为一个人创建这样一个对象。
mymts<-dataset%>%

要使用的数据集。
现在让我们绘制对象中的数据。有趣的是,绘图函数会将该对象识别为一个多变量时间序列,因此如果你要求绘制数据,它将干净地完成。
plot(mymts)
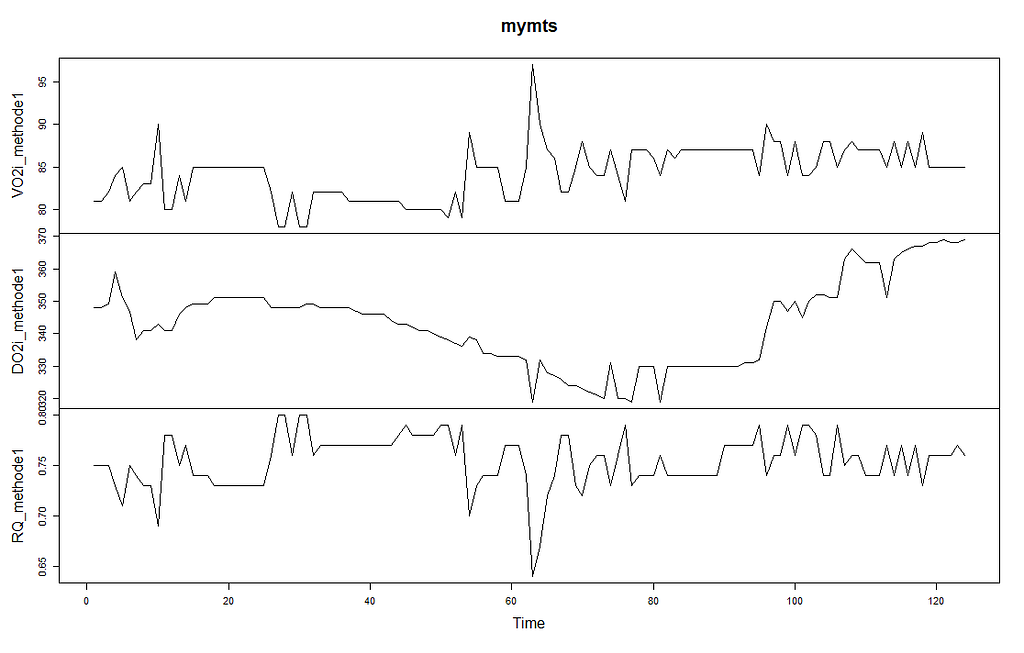
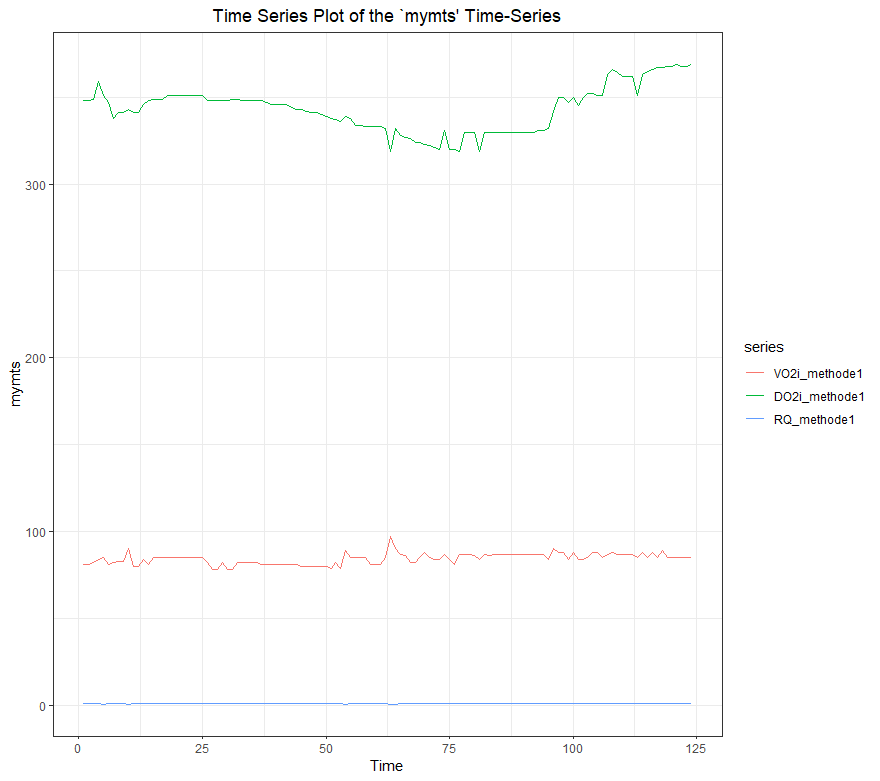
左边的绘图比右边的好得多,这很有趣,因为右边的叫做自动绘图。
时间序列数据看起来非常酷,但有很多注意事项、假设和你可以而且需要检查的想法。我已经在这里、 这里和这里的适用例子中写到了这些假设的一些内容。
从mymts 对象中,我们可以对每个时间序列分别应用Augmented Dicky Fuller测试,以确定是否需要整合数据。就个人而言,我不喜欢p值驱动的测试,但既然它被经常使用。ADF检验测试的是单位根存在于时间序列 样本中的无效假设。替代假设是不同的,取决于使用哪种版本的测试,但通常是静止性或趋势静止性。它是Dickey-Fuller检验的一个增强版本,适用于更大、更复杂的时间序列模型。检验中使用的增强的Dickey-Fuller(ADF)统计量是一个负数。负数越大,在一定的置信度下拒绝存在单位根的假设的力度就越大。因此,你想看到的是一个负值,或者一个显著的P值,显示不存在随机过程--单位根。
apply(mymts, 2, adf.test)
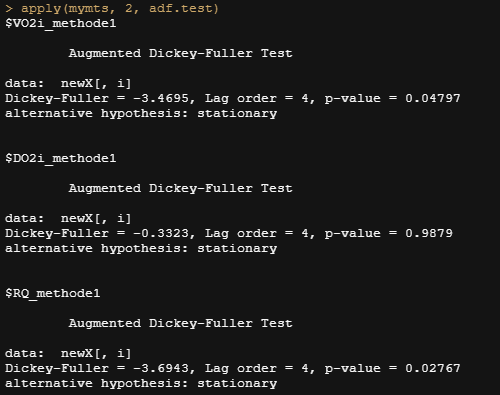
DO2i_methode1变量是唯一的变量,根据ADF检验,它有一个单位根。通常的帮助是对数据进行整合,也就是说,你将从时间序列中提取一个d阶的滞后函数。
虽然我们看到有一个变量可以从整合中受益,但我还是会让它保持原样,看看它如何发挥长处。这把我带到了下一个阶段,那就是应用矢量自回归模型。我很懒,所以我将使用一个自动选择功能,使用10个时间序列单位的最大滞后期,并使用AIC来找到手头数据的最佳滞后期值。就像我说的,这很懒,但作为开始,我想说这是一个不错的开始。
VARselect(mymts,type = "none",lag.max = 10)
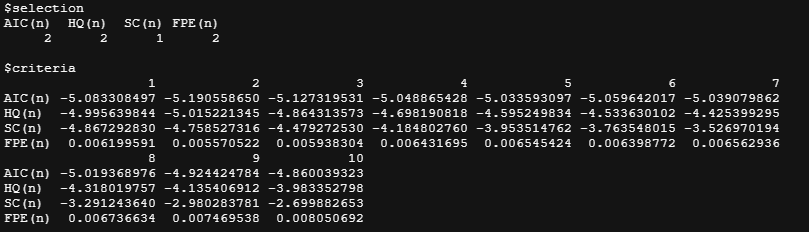
你可以看到,使用了四个选择标准。AIC、HQ、SC和FPE。由于我们用AIC来确定我们使用的滞后变量,所以选择的滞后变量将是2。
因此,使用这个值,我将建立VAR模型。由于我们将三个时间序列整合在一起,并开始进行协整,我们将提供大量的结果,这使得这类模型不容易运行。
var.a <- vars::VAR(mymts,
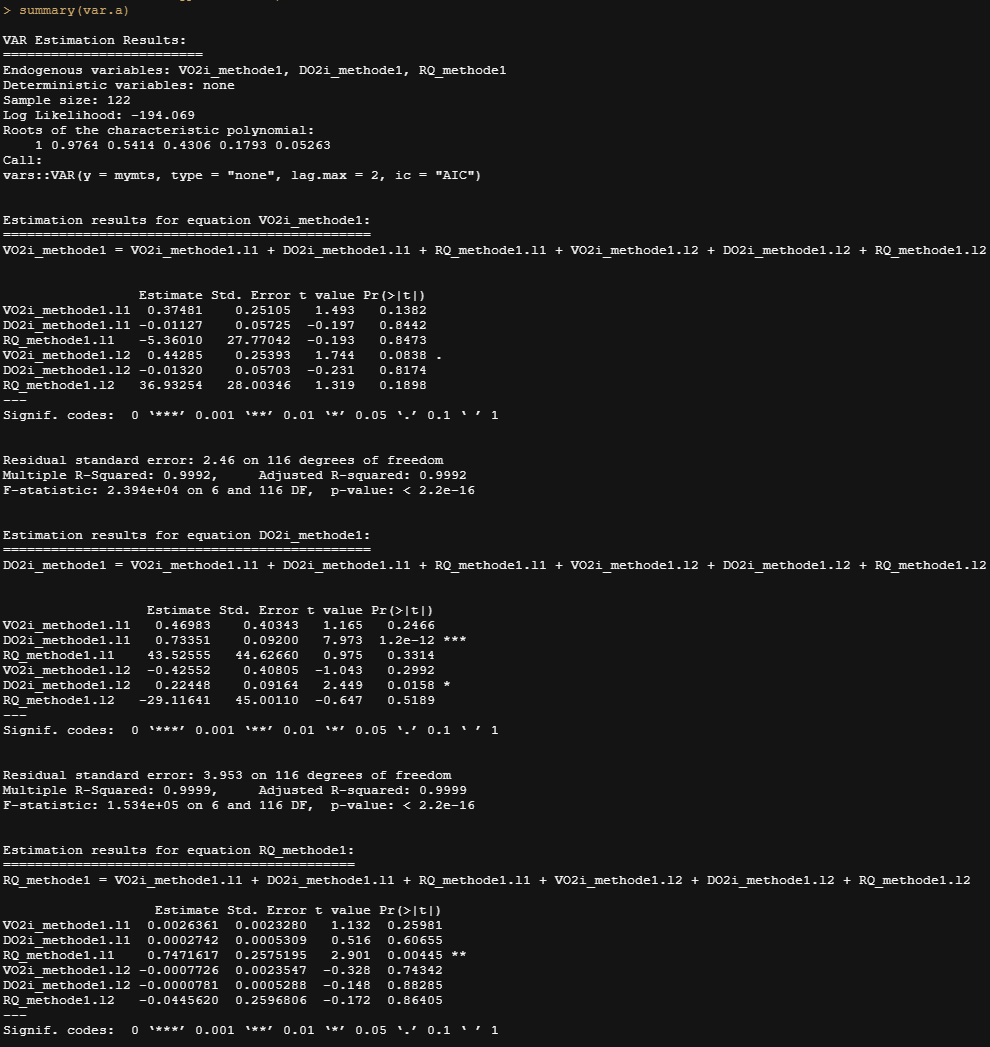
三个模型中的每一个都是自己和其他时间序列的函数,最大滞后期为2。调整后的R-square非常大,暗示着严重的过拟合。

还有三个模型的相关矩阵。VO2 和RQ 有很大的相关性,这应该不奇怪。RQ 是VO2的一个函数。
接下来是序列测试,计算序列相关误差的多变量Portmanteau-和Breusch-Godfrey测试。Breusch-Godfrey检验是对回归模型中误差的自相关的检验。它利用了回归分析中所考虑的模型的残差,并从这些残差中得出一个检验统计量。无效假设是,在p以内的任何阶次都不存在序列相关 。

根据这个测试,不存在序列相关。就像我之前说的,这些测试有价值(可以有价值),但不应该真正使用p值的界限。
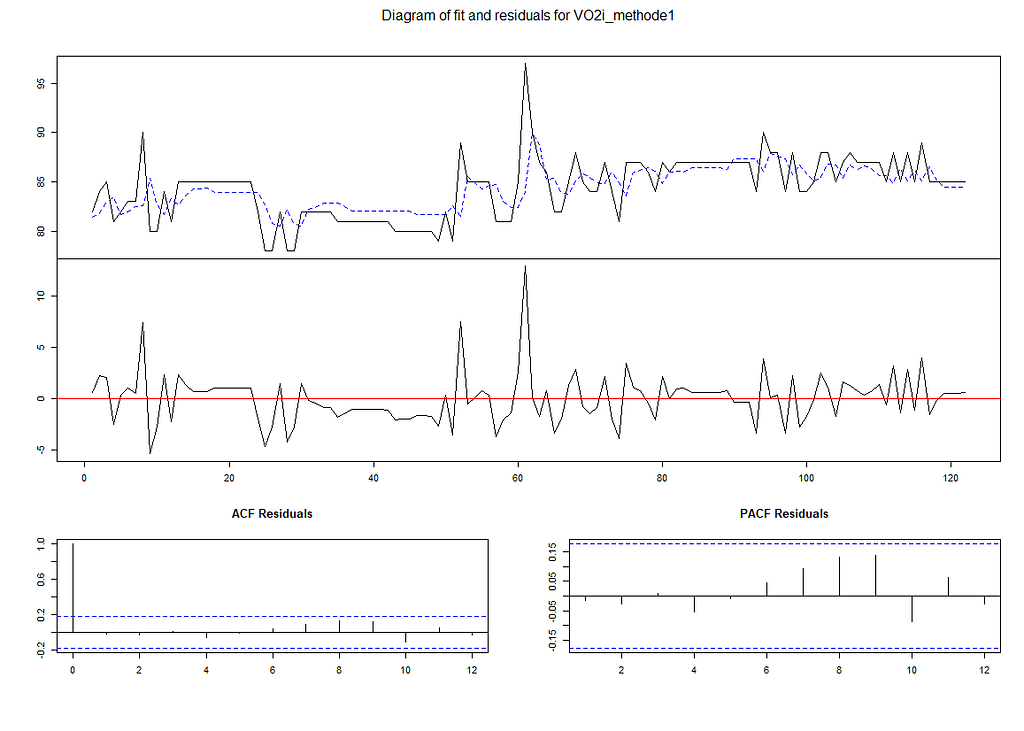


更好的办法是好好看看这些图,特别是ACF en pACF值,它显示了自动相关和部分自动相关值。所有这些都在界限之内,这是我想看到的。因为如果我不这样做,我将不得不整合数据,添加预测因子或直接建立残差模型。
从理论上讲,从VAR模型中,我可以看一下潜在的因果关系。如果你还记得布拉德福德-希尔的因果关系标准,你就知道时间(或时间性)是其中的一个标准(在许多其他的标准中)。由于我们正在研究时间序列内和跨时间序列的变化,我们可以看到一个时间序列的变化是否与另一个时间序列有足够大的交叉关系。我们可以测试这种关系是否只是单向的,我们可以减去时间序列本身的自动相关。
具体测试使用的是格兰杰因果关系测试,在这个测试中,你必须指定哪些变量被假设为以因果关系的方式相互影响。我在Covid-19数据上做了两次--一次在这里,另一次在这里,尽管后者使用的是不同的方法。除了我们永远无法确定完全的因果关系之外,这项工作还有一些优点,至少可以表明关系可能会走向哪一个方向。
如果可以证明,通常通过对X的滞后值(也包括Y的滞后值)进行一系列的t检验和F检验,这些X的值为Y的未来值提供了统计上的重要信息,那么就可以说一个时间序列X是格兰杰导致了Y 。
我将做的是指定时间序列DO2 和RQ 的 "原因 "是VO2。然后,模型将通过滞后值查看是否能建立预测性因果关系,也就是说,你想找到VO2 的值是否对DO2 和RQ有足够的预测能力,但反过来就不是了。
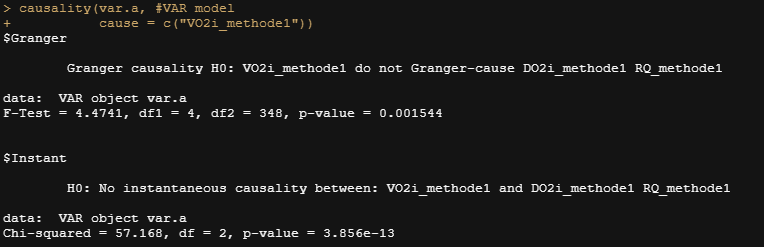
在这两种情况下,无效假设被拒绝,这意味着VO2 确实对DO2 和RQ有影响。再一次,考虑到这些公式是如何组成的,这应该是不奇怪的。这确实意味着预测RQ 的模型很可能会做得相当好,包括其本身的滞后期,但也非常可能包括VO2的滞后期。

对每个时间序列的预测。预测窗口不大,但预测区间很宽。这些预测完全没有帮助。
过去几年都是深度学习,深度学习和深度学习在有数据的地方应用神经网络。除了神经元需要大量的数据来工作外,它们绝对不会自动击败旧模型。这不是终结者--旧模型并没有被淘汰。此外,通过非常简单的功能来挥舞和产生这样复杂的模型变得越来越容易,这些功能已经将引擎盖下的一切自动化。让我给你举个例子说明它有多容易。
从多个时间序列对象中,我们可以使用预测包中的nnetar函数,在第一个时间序列上拟合一个神经网。该时间序列将预测自己,这也是时间序列的部分设计目的。
fit = nnetar(mymts[,1]);fit

拟合在时间序列上的神经网络模型。没有调整,只有标准函数,以获得一个网络的集合。
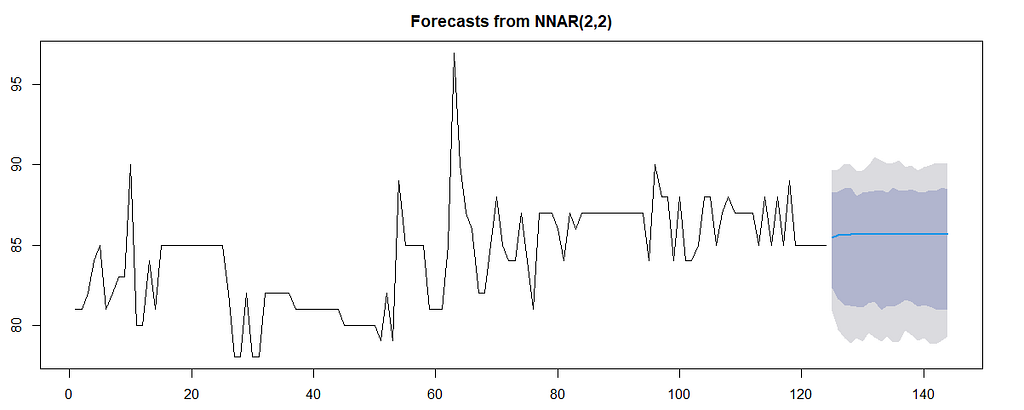
预测也是一样可怕的。
神经网络可以通过添加预测因子而得到增强。因此,让我们说,为了使模型不至于自我窒息,我们让DO2 预测VO2。
mymts[,1:2]
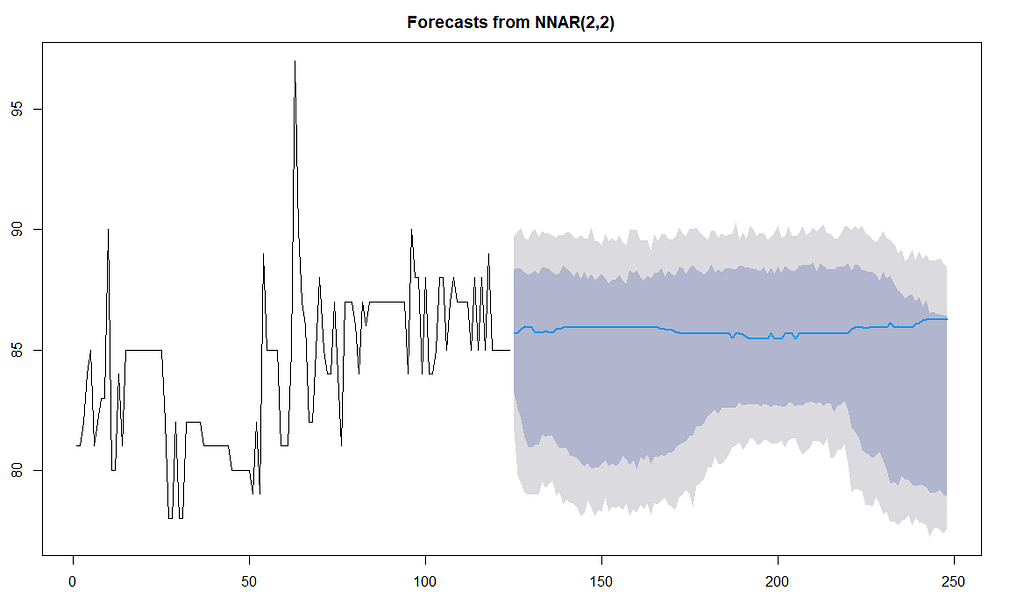
看起来已经很不一样了。预测线仍然是最后一个值的结转,而且相当大,但仍然有更多的变化。好吧,即使这只是它的工作方式。
到现在为止,我们一直在处理一个单一的时间序列。一个单一的ID。但是我们有更多的数据,这些数据应该被使用,同时包含数据的时间序列性质。突出我们的一个好方法是通过特定的GGplot函数。例如,在下面的例子中,我想突出VO2cdi的四个最高时间序列,这是数据集中的一个不同指标。
ggplot(dataset, aes(ElapsedTime, VO2cdi, color=ID)) +

由于我们有44个受试者的数据,每个受试者有124个观察值(这些观察值都是等距的),让我们看看是否可以添加聚类技术来获得数据的最大价值。在一个特定的结果中,我们能否通过观察整个病人来找到模式?虽然我们已经完成了主要的问题,即参数对VO2的影响,但我想把这个数据集再进一步,在上面做实验。当然,太多的实验可能弊大于利,尤其是在事后进行的时候,但无论如何,让我们看看吧。
下面是对VO2cdi进行聚类的代码
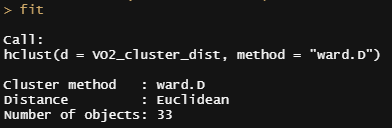
聚类模型,查看VO2cdi的时间序列数据的聚类情况
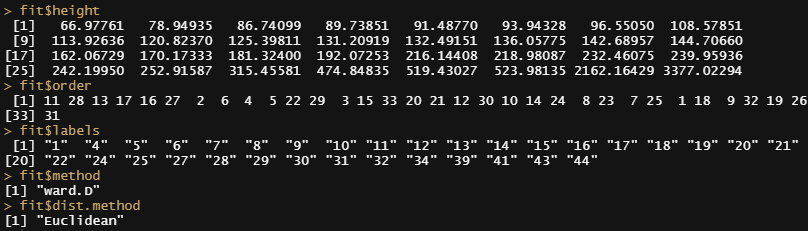
你可以看一下模型的部分内容。记住,这个数据已经完全在ID层面上进行了处理,你可以在fit$labels看到。
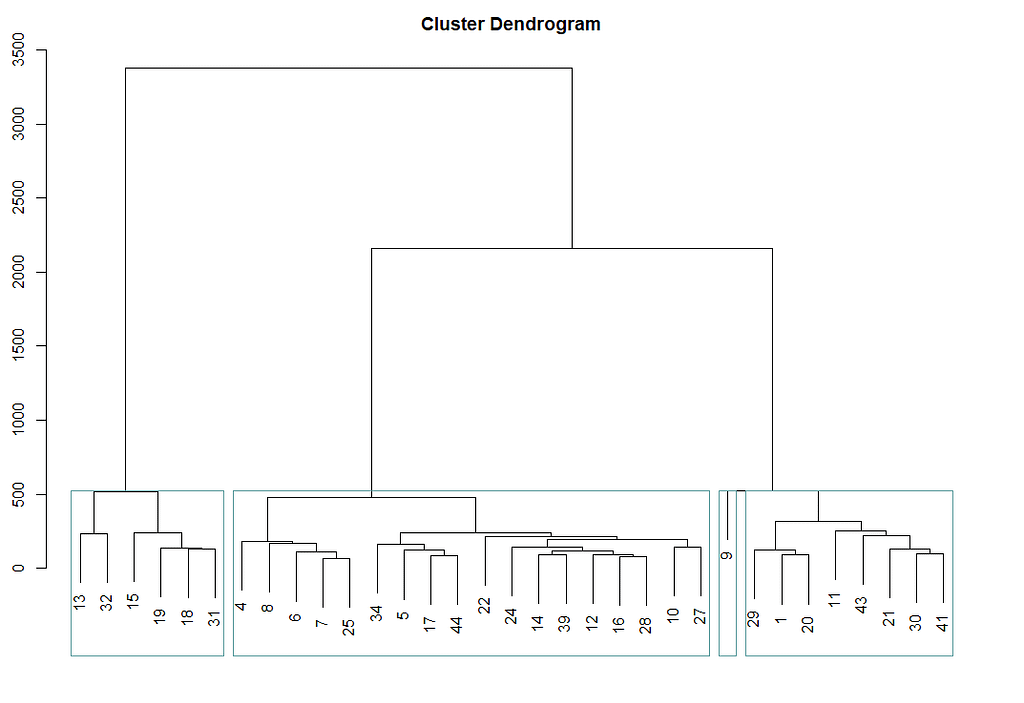

同样的图,但是旋转了。显示哪些ID聚在一起。不知道这个结果有多有效。虽然使用了欧几里得距离,但我们仍然在谈论时间序列,虽然测量是同步的,所以每个ID有124个测量值(无论时间如何),序列本身的自动相关没有被考虑在内。
我有四个组,所以我可以做的是将这些标签与原始数据合并起来,并绘制属于某个组的每个ID的样子。下面,你可以看到群组=2的时间序列。

时间序列和样条叠加在群组2中每个ID的上面。
当然,我们可以显示所有群组的所有数据,并看到聚类算法(欧几里得距离)是如何进行分割的。
ggplot(joined_clusters,

另一种对时间序列数据进行聚类的方法是使用kml 包。这个包是专门为聚类时间序列数据和寻找聚类而设计的。让我们在一个不同的结果(Hb)上应用klm包,然后再看看它在VO2cdi 结果上会得出什么结果。

为了让kml工作,数据需要在一个特定的结构中,其中你指定时间数据和ID 数据。

然后,你可以让算法做它的工作。你可以让它选择指定多少个聚类,或者你事先说明你想要多少个聚类。

在这里,我们得到了结果,考虑到我们要求模型运行无数次的聚类程序,在这个可能是非常乏味的过程中,我们得到了六个聚类。
让我们重复同样的方法,但对VO2cdi 来说,看看聚类技术是否显示出同样的结果。
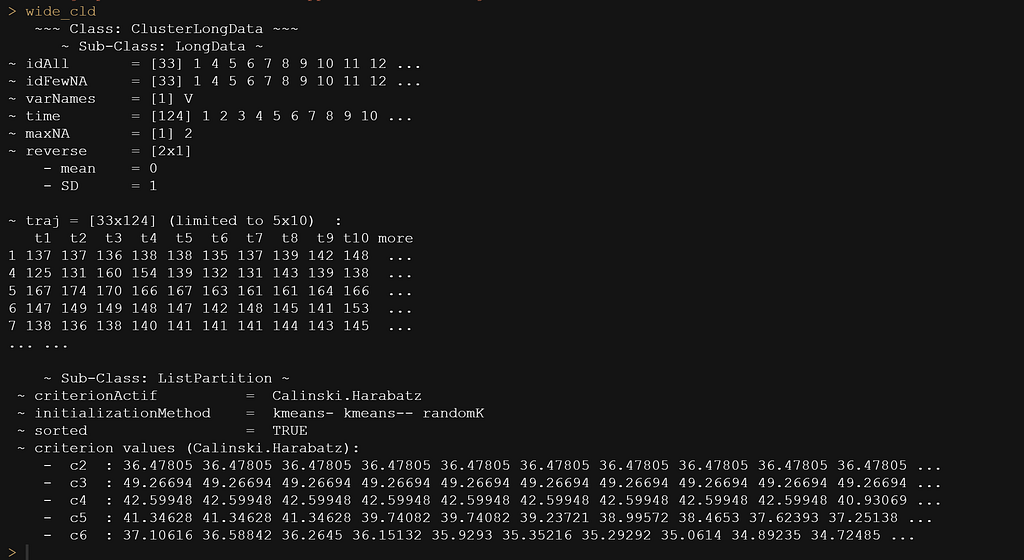

现在我得到了三个聚类,而不是之前练习中看VO2cdi时的四个。然而,如果你比较一下图表,你已经可以看出,四个聚类也许有点多了。所以,我可以接受三个。
最后但并非最不重要的是,让我们看看我们是否可以对一个多变量的时间序列对象进行聚类。现在,我从一开始就可以做的一件事,就是看看哪些变量有很大的相关性,然后把它们加在对象中。
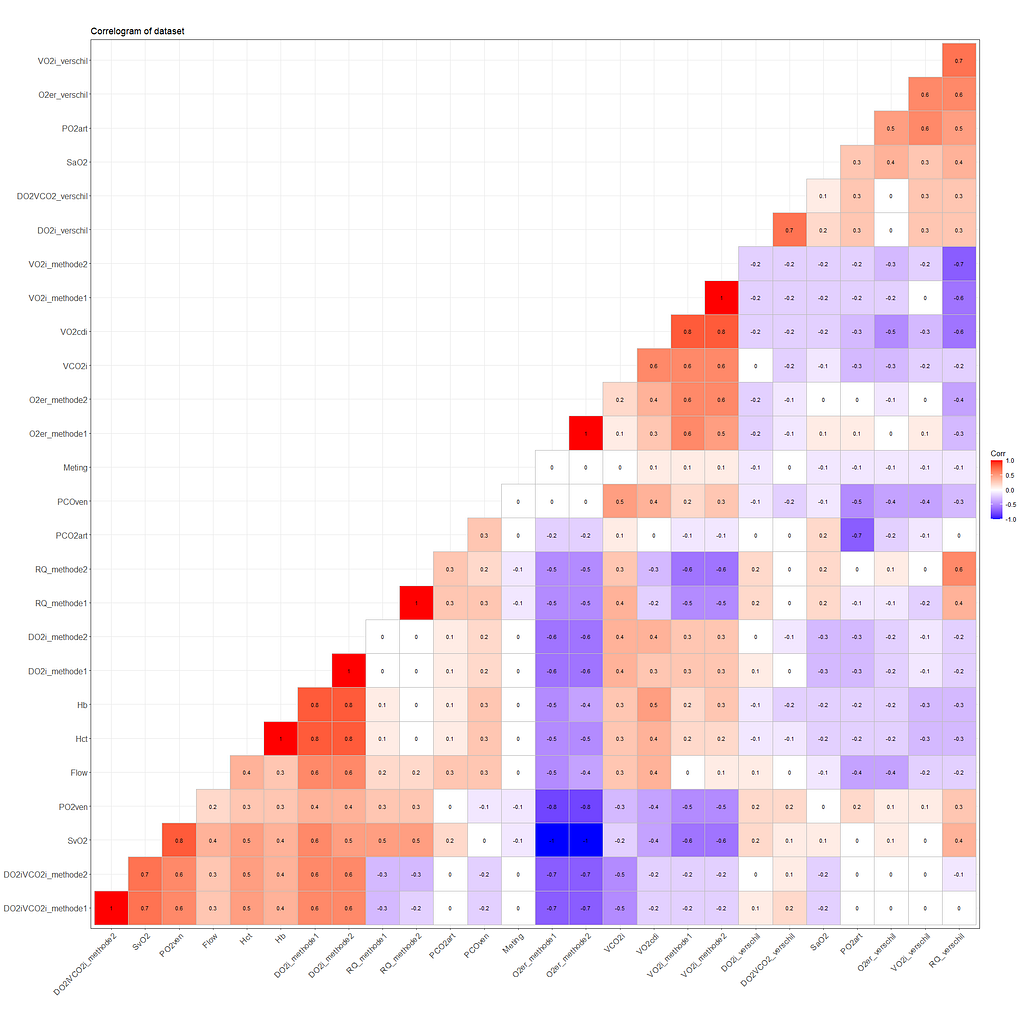
显示数据集中每个变量组合的相关图的代码。你可以选择,但要注意--对时间序列对象的相关分析应该比这里做得更好一些。在这里,相关度量不会考虑到集群内的差异。然后,它是一个筛选工具,可以做进一步的图来检查。

例如,Hb 和VO2cdi之间的相关关系。该图显示了每个ID的明显差异,也显示了变量如何趋于集群。我还不确定具体的关系是什么,但这里似乎储存了一些信息。
让我们回到老的mymts 对象,它包含三个纠缠在一起的度量。我将做的是建立一个更符合时间序列分析性质的聚类模型。为了做到这一点,我将部署 预测成分分析 包和foreca 函数。Foreca 代表的是 可预测成分分析(ForeCA),是一种针对时间相关信号的新型降维技术。基于一个新的可预测性措施,ForeCA找到一个最佳的转换,将一个多变量时间序列分离成一个可预测的和一个正交的白噪声空间。这篇论文的统计资料相当多,在某些方面肯定超过了我的水平,但我确实想让你了解一下现有的情况。记住,我们开始的问题不需要这种分析。我们可以在几段之前就开始。但是在处理多变量时间序列方面,它确实显示了一个可用的不错的补充。
让我们大干一场,建立一个包含七个序列的多变量时间序列。
mymts<-dataset%>%
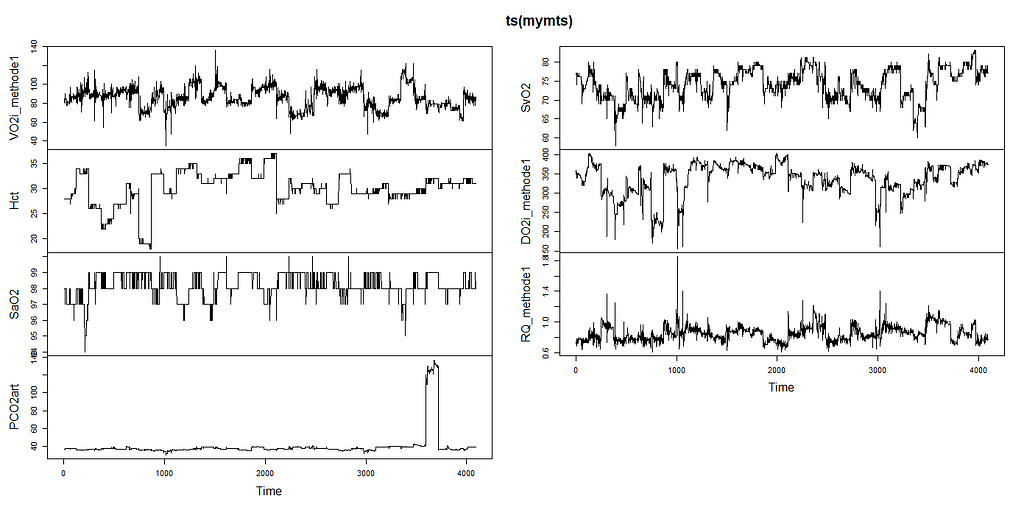
请记住,这些时间序列是所有的病人,彼此相邻,构成了七个极长的时间序列!
现在来看看时间序列的成分分析。当然,这个函数本身非常简单,因此,我认为它有点太容易揭示基础数学了。例如,在一句话中,我做的多变量时间序列对象被缩小为两个成分。这就是我想要的。哦,还有欧米茄值?那是可预见性的衡量标准。你希望那个值越大越好。
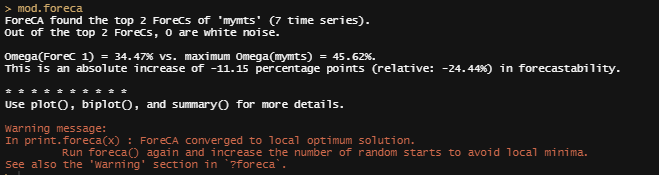
这就是我得到的结果,看起来不妙。第一部分的欧米茄分值比最大的欧米茄分值要小很多。
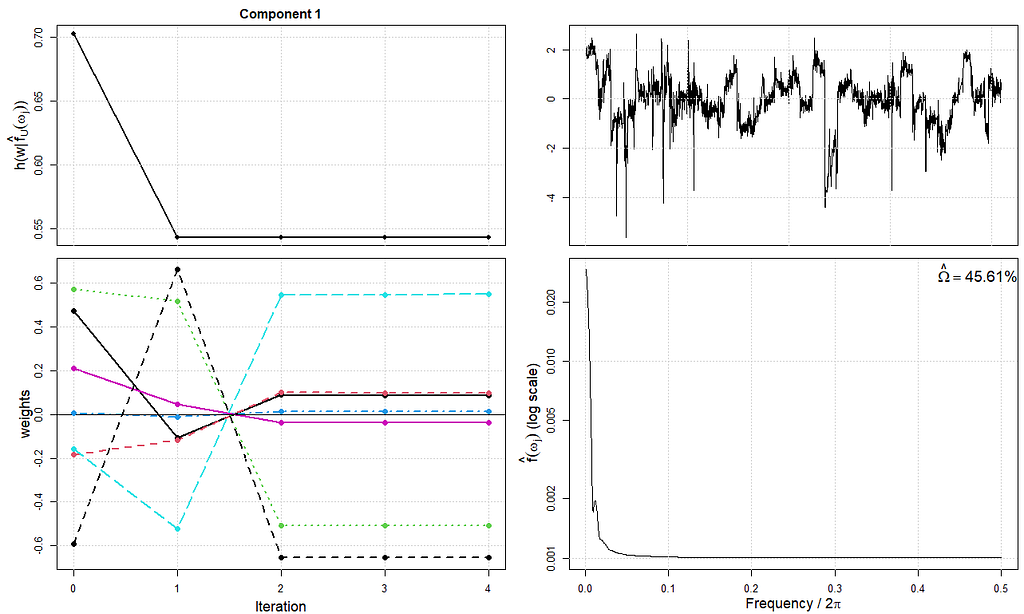

在这个图中,你可以看到算法的频谱密度部分,试图通过观察时间序列中的振荡来寻找集群。你可以看到每个成分的欧米茄值。
让我们去找三个类别。在你滚动之前我会警告你--它不是一个成功的例子。
mod.foreca <- foreca(mymts,

正如你所看到的,数据的聚类并没有真正的帮助。

每个组件的可预见性。

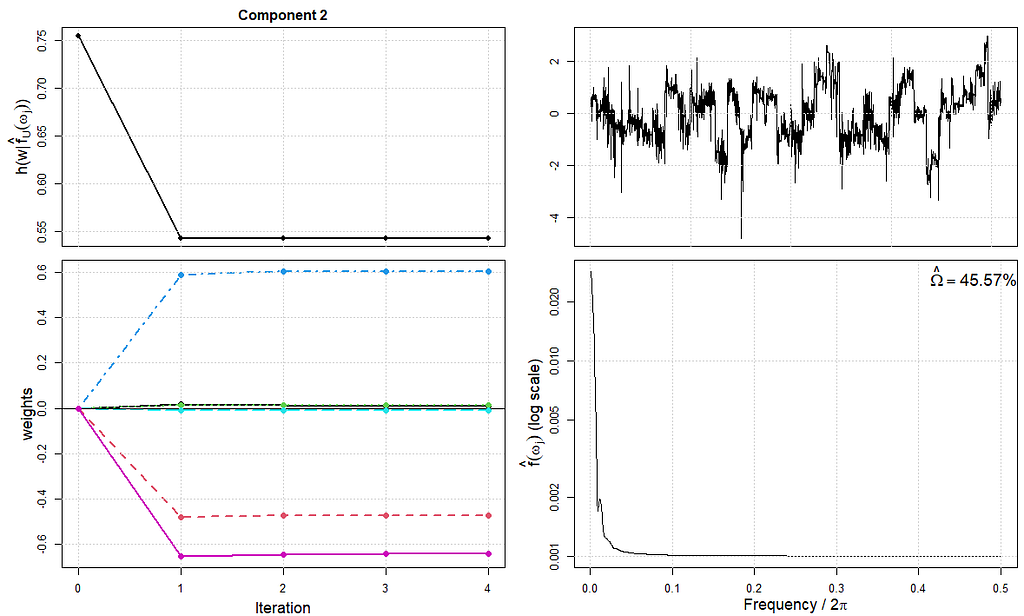
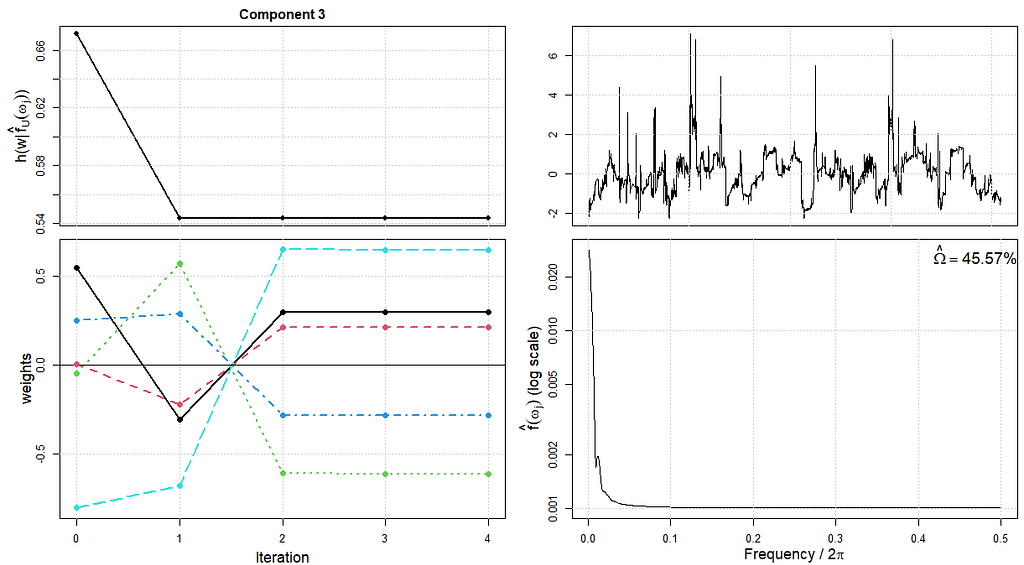
而包括更多的迭代也没有什么作用。似乎真的没有那么多的信号,尽管模型说没有一个成分是由白噪声组成的(这是纯随机的)。
下面是汇总统计和双曲线图。说实话,我喜欢数字,但我更喜欢图表,下面的图表比旁边的数字更能让我看到。也就是说,有多小的聚类,如果你看到了最初的时间序列的情况,这也许不是那么奇怪。
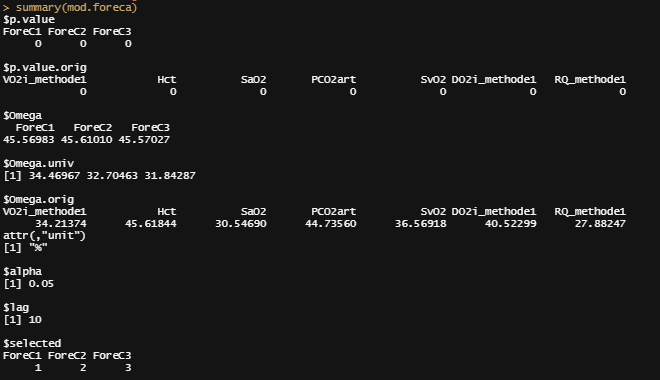
正如你所看到的,这里的文字和右边的图形是,没有任何聚类。
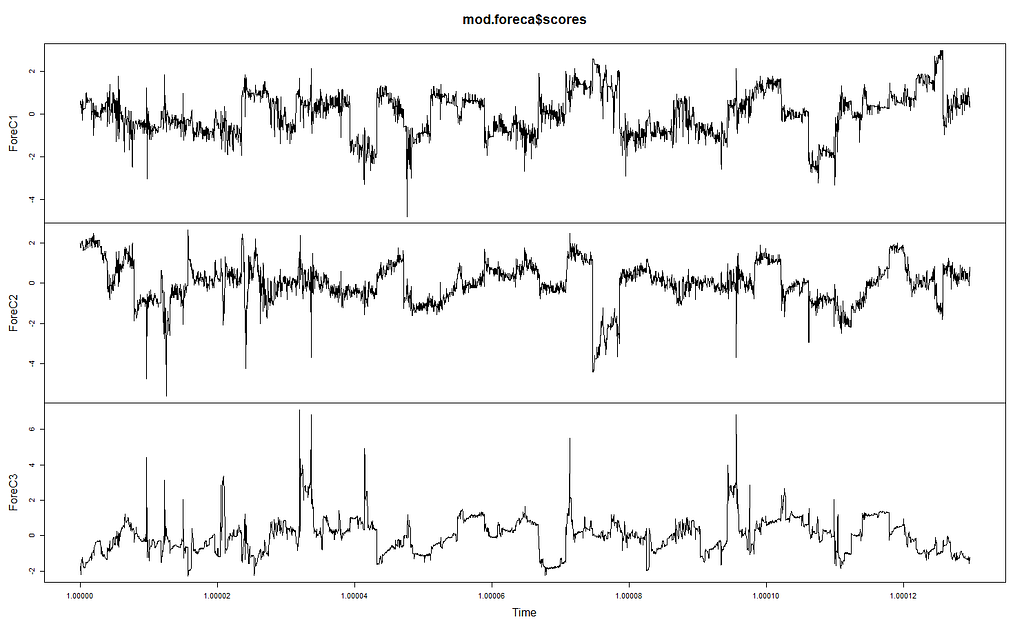
可预测成分。
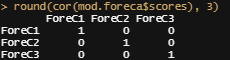
还有相关矩阵。哎哟,不妙。虽然你希望集群是正交的,但如果它们是那么整齐和干净的,因此是零的话,我会非常惊讶。
下面是一个显示多变量时间序列的估计谱的图。这三个群组似乎遵循同样的趋势。不知道这个图有多大帮助。说实话,我觉得整个软件包有点奇怪,除了双曲线图,它和你从局部最小二乘法得到的图非常熟悉。我想,这只是我缺乏理解而已

好了,我希望你喜欢这篇博文。处理秒速快三精准人工下注计划中的时间序列数据是很好的,也很有挑战性,但最重要的部分是你要尽量坚持最初的研究问题。我偏离了这一点,但分析数据不仅仅是工作,也应该是一种乐趣 :-)
如果有不妥之处,请告诉我。
目标导向的灌注参数计算中的变化》最初发表在《Dev Genius》杂志上,人们通过强调和回应这个故事来继续对话。
