

简介
排序是用于解决问题的基本技术之一,特别是在那些与编写和实现高效算法有关的问题中。
通常情况下,排序是与搜索结合在一起的--这意味着我们首先对给定集合中的元素进行排序,然后在其中搜索一些东西,因为在一个已排序的集合中搜索一些东西通常比在一个未排序的集合中搜索更容易,因为我们可以做出有根据的猜测并对数据进行假设。
有很多算法可以有效地对元素进行排序,但在本指南中,我们将看看背后的理论,以及如何在Java中实现Quicksort。
有趣的是:从JDK7开始,JVM中用于Arrays的现成排序的算法是一种双枢轴Quicksort!
Java中的Quicksort
Quicksort是一种属于分而治之算法组的排序算法,它是一种就地(不需要辅助数据结构)、非稳定(不保证排序后同值元素的相对顺序)的排序算法。
分割和征服算法以递归的方式将一个问题分解为两个或多个相同类型的子问题,使其更容易解决。这种分解一直持续到一个问题简单到可以单独解决为止(我们称之为基本情况)。
这种算法已被证明在处理大数组时能得到最好的结果,另一方面,在处理较小的数组时,像 选择排序等算法可能会被证明更有效率。
Quicksort修改了选择排序的基本思想,因此,在每一步中,一个元素都被放在它在排序数组中的位置上,而不是一个最小值(或最大值)。
这个元素被称为 枢轴.然而,如果我们想使用分而治之的方法,将数组的排序问题减少到两个子数组中,我们需要遵守以下几点:当我们将支点放在数组中的位置时,我们需要将其余的元素分成两个更小的组--支点的 左的元素比它小或等于它,而在 右上的元素比中枢大。
这实际上是算法的关键步骤--称为分区,如果我们希望我们的Quicksort也是高效的,有效地实现它是必须的。
在讨论Quicksort如何工作之前,我们应该解决如何选择哪个元素作为支点的问题。最完美的情况是,我们总是选择能将数组精确分成两半的元素。然而,由于这几乎是不可能实现的,我们可以通过一些不同的方式来解决这个问题。
例如,支点可以是我们当前处理的数组(或子数组)中的第一个或最后一个元素。我们可以选择一个中位数元素作为支点,甚至可以选择一个随机元素来扮演这个角色。
我们有多种方法来完成这一任务,本文中我们将采取的方法是始终选择第一个(即数组中最左边的元素)作为支点。现在让我们跳到一个例子中,解释这一切是如何进行的。
Quicksort的可视化
假设我们有以下数组。
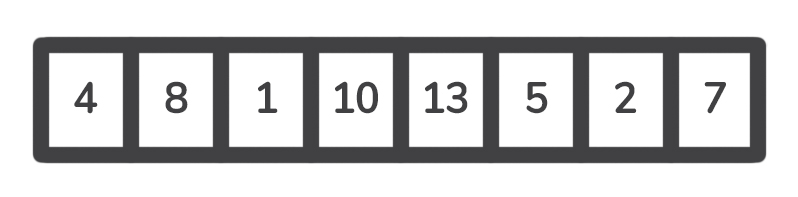
在这个例子中,第一次迭代的支点是4 ,因为决定选择数组的第一个元素作为支点。现在要进行分割了--我们需要将4 放在它在排序后的数组中的位置。
这个位置的索引将是2 ,所以在第一次分区后,我们的数组将看起来像这样。
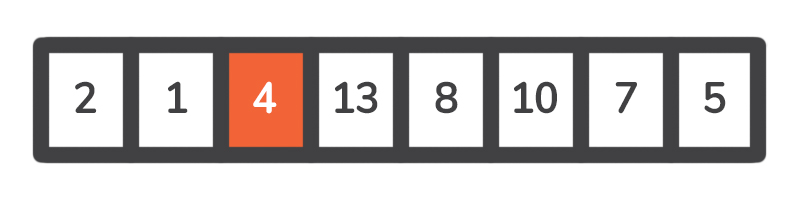
![]()
注意:值得注意的是,位于支点左右的元素并没有像它们应该的那样被排序。
这是可以预料的--每当我们分割一个不是基数的数组(即大小为1 )时,元素会以随机的顺序分组。
重要的是我们之前讨论过的:枢轴左边的元素要小于或等于,右边的元素要比枢轴大。这并不是说它们不能在第一组中排序--虽然不太可能,但还是有可能发生。
我们继续往下看,在这里,"分而治之 "发挥了作用--我们可以把原来的问题分解成两个小问题。
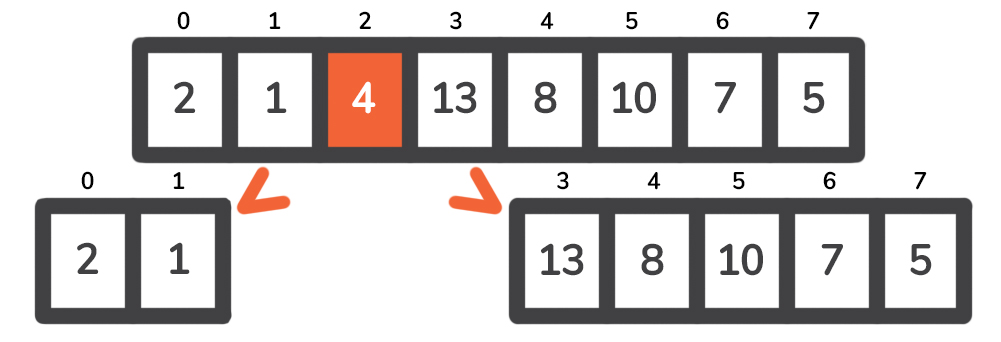
对于左边的问题,我们有一个大小为2 的数组,枢纽元素将是2 。在将支点定位后(在1 ),我们得到一个数组[1, 2] ,之后我们就没有左边的问题的案例了,因为[1, 2] 的唯一两个子案例是[1] 和[2] ,它们都是基本案例。这样我们就完成了左边的子案例,并认为这部分数组已经排序。
现在是右边--枢轴是13 。因为它是我们要处理的数组中所有数字中最大的一个,所以我们有如下设置。
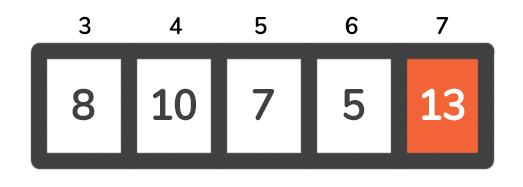
与先前不同的是,枢轴将我们的数组分解成两个子案例,这里只有一个案例--[8, 10, 7, 5] 。现在的支点是8 ,我们需要把它带到数组中的位置5 。
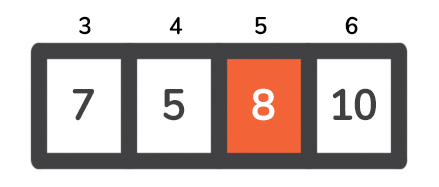
枢轴现在将数组分成了两个子案例:[7, 5] 和[10] 。由于[10] 的大小是1 ,所以这是我们的基本情况,我们根本不考虑它。
唯一剩下的子数组是[7, 5] 。这里,7 是枢轴,在把它带到它的位置(索引4 )后,在它左边的位置3 ,只有5 。我们没有更多的子数组,这就是算法的结束。
在运行Quicksort之后,我们有如下的排序数组。
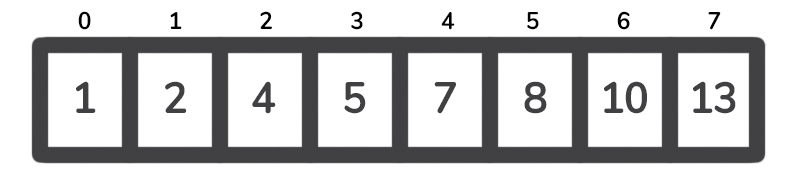
这种方法也考虑到了数组中的重复情况,因为枢轴左边的所有元素都小于或等于枢轴本身。
在Java中实现Quicksort
有了对Quicksort工作原理的良好直觉,我们就可以继续实施了。首先,我们将通过程序的主要部分,来运行Quicksort本身。
由于Quicksort是一种分而治之的算法,它自然是以递归方式实现的,尽管你也可以以迭代方式进行(任何递归函数也可以以迭代方式实现)--不过,实现起来并不那么干净。
static void quicksort(int[] arr, int low, int high){
if(low < high){
int p = partition(arr, low, high);
quicksort(arr, low, p-1);
quicksort(arr, p+1, high);
}
}
![]()
注意: low和high代表当前正在处理的数组的左和右边距。
partition(arr, low, high) 方法对数组进行分割,在执行时,变量p 存储分割后的枢轴的位置。
这个方法只有在我们处理有多个元素的数组时才会被调用,因此只有在low < high 。
由于Quicksort是就地工作的,所以在数组中可以找到的起始多元素集保持不变,但我们已经完成了我们的目标--将小的或相等的元素分组到支点的左边,而比支点大的则在右边。
之后,我们递归调用quicksort 方法两次:对数组中从low 到p-1 的部分和从p+1 到high 的部分。
在我们讨论partition() 方法之前,为了便于阅读,我们将实现一个简单的swap() 函数,在同一个数组中互换两个元素。
static void swap(int[] arr, int low, int pivot){
int tmp = arr[low];
arr[low] = arr[pivot];
arr[pivot] = tmp;
}
现在,让我们深入了解一下partition() 方法的代码,看看它是如何完成我们上面所解释的内容的。
static int partition(int[] arr, int low, int high){
int p = low, j;
for(j=low+1; j <= high; j++)
if(arr[j] < arr[low])
swap(arr, ++p, j);
swap(arr, low, p);
return p;
}
当for 循环执行完毕后,j 的值为high+1 ,这意味着arr[p+1, high] 上的元素高于或等于中枢。正因为如此,我们需要对low 和p 位置上的元素再做一次交换,使支点在数组中处于正确的位置(即p 位置)。
我们需要做的最后一件事是运行我们的quicksort() 方法并对数组进行排序。我们将使用与之前例子中相同的数组,调用quicksort(arr, low, high) 将对数组的arr[low, high] 部分进行排序。
public static void main(String[] args) {
int[] arr = {4, 8, 1, 10, 13, 5, 2, 7};
// Sorting the whole array
quicksort(arr, 0, arr.length - 1);
}
这样的结果是
1, 2, 3, 4, 5, 7, 8, 10, 13
Quicksort的复杂性
Quicksort,以及其他采用分而治之策略的算法,其时间复杂度为O(nlogn) 。然而,与诸如 合并排序的最坏情况下的时间复杂度为O(nlogn) ,Quicksort在理论上的最坏情况下的时间复杂度为O(n^2) 。
复杂度取决于我们花多少时间来有效地选择一个支点,这有时会和数组本身的排序一样困难,由于我们期望选择一个支点是O(1) ,所以我们通常不能保证在每一步中我们都能选择最好的支点。
尽管Quicksort的最坏情况是O(n^2) ,但大多数选择枢轴的策略都是这样实现的,所以它们不会对复杂度造成太大影响,这就是为什么Quicksort的平均复杂度是O(nlogn) 。它被广泛实现和使用,这个名字本身就是对其性能能力的一种评价。
另一方面,Quicksort胜过Merge Sort的地方是空间复杂度--Merge Sort需要O(n) ,因为它使用一个单独的数组进行合并,而Quicksort是就地排序,其空间复杂度为O(1) 。
总结
在这篇文章中,我们已经介绍了Quicksort算法是如何工作的,它是如何实现的,并讨论了它的复杂性。尽管枢轴的选择可以 "决定 "这个算法,但它通常被认为是最有效的排序算法之一,并且在我们需要对有大量元素的数组进行排序时被广泛使用。
