

简介
图是存储某些类型的数据的一种便捷方式。这个概念是从数学中移植过来的,并适用于计算机科学的需要。
由于很多东西都可以用图来表示,图的遍历已经成为一项常见的任务,特别是在数据科学和机器学习中使用。
Prim算法是如何工作的?
普利姆算法的设计是为了找到一个 ***最小生成树(MST)*为一个连接的、加权的无向图。这意味着该算法找到了一棵 "树"(一种没有循环的结构),它通过所有可用的边的一个子集连接所有的顶点,这些边的权重最小。
与Dijkstra算法一样,Prim算法也是一种贪婪的算法,但Prim算法允许负加权的边。
在算法的最后,我们将循环浏览包含最低成本边的数组,并将它们相加,得到图中MST的值。
我们将讨论这个算法的每一步是如何工作的,但可以列出算法的一个粗略的轮廓。假设我们有一个加权图G ,有一组顶点(节点)V ,有一组边E 。
- 我们选择其中一个节点
s作为起始节点,并设定从s到s的距离为0。 - 我们将从节点
s,给其他每个节点分配一个数字,在开始时将其标记为无穷大。这个数字将随着我们的算法进展而改变和更新。 - 每个节点
s,也将有一个代表 "父 "节点的数字,我们在MST中从它那里连接。这个数字被初始化为-1,除了起始节点外,其他每个节点在Prim算法结束时都会有一个与-1不同的数字与之相关。 - 对于每一个节点
s,我们将找到连接一个已经包括在MST中的节点的最小边。 不是已经包含在MST中。由于Prim's是一种贪婪的算法,一旦我们进入节点,我们就可以肯定我们已经选择了连接它和它的父节点的最短路径。我们重复这个步骤,直到所有的节点都被添加到MST中。 - 最后,我们在我们的MST数组中循环,把边加起来,得到MST的值。
Prim算法的可视化
让我们快速可视化一个简单的例子--手动使用Prim算法在以下图形上寻找最小生成树。
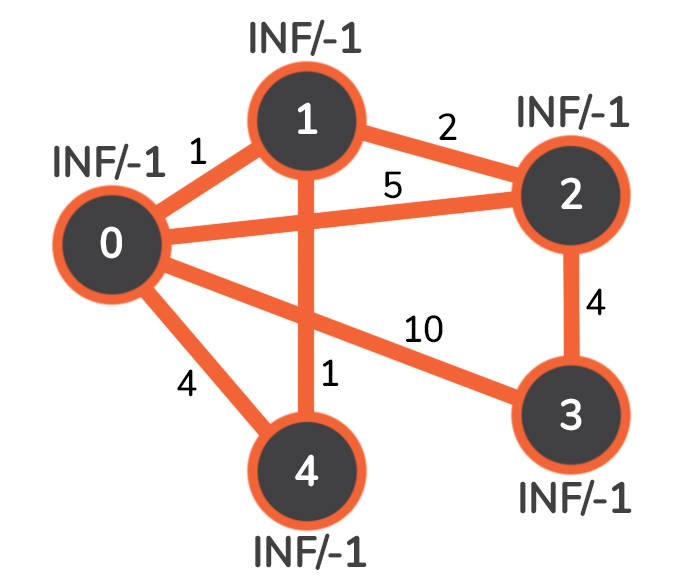
我们将有5个节点,编号为0到4,每条边上的数字代表该边的权重。让我们来描述一下INF/-1 对:开头的-1 代表父节点,从该节点有一条连接到当前节点的边,其权重为INF 。当然,随着算法的进行,这些值也会被更新。
比方说,0 将是我们的起始节点。我们在前面提到,当我们选择起始节点时,我们需要设置与自己的距离为0 。由于0 是与自己有最小边的节点,我们可以安全地假设0 属于MST,我们就把它加进去。经过这个小小的改变,图看起来如下。

![]()
白色的节点代表我们添加到MST中的节点。
下一步是使Prim的算法成为现实的一个步骤。我们循环浏览节点0 的所有邻居,沿途检查一些东西。
- 如果该边缘存在
- 如果邻居节点已经被添加到MST中
- 如果通往邻居的边的成本低于当前通往该邻居的最小成本的边
0 的第一个邻居是1 。连接它们的边的权重为1 。该边存在,而当前节点1 不在 MST 中,所以剩下的就是检查从0 到1 的边是否是通向节点1 的最小加权边。很明显,1 小于INF ,所以我们把节点1 的距离/父对更新为1/0 。
我们对节点0 的其他邻居采取完全相同的步骤,之后我们选择具有最小边权重的节点加入到MST中,并将其标记为蓝色。这个节点就是1 。
现在我们有了下面这个图。
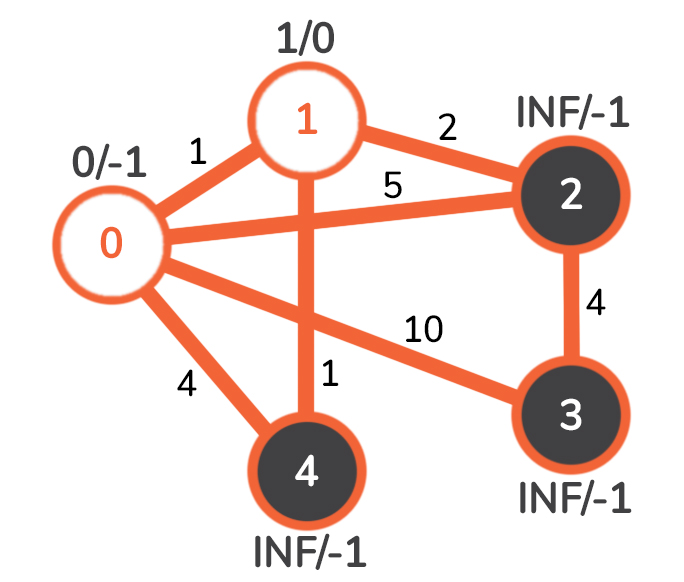
我们现在要考虑的节点是1 。正如我们对节点0 所做的那样,我们检查节点1 的所有邻居。
节点0 已经被添加到MST中,所以我们跳过这一个。
节点2 是下一个邻居,从节点1 通向它的边的权重是2 。这条边的权重比之前通往该节点的边小,后者的权重是5 ,来自节点0 。
另一个邻居节点4 也是如此:从节点1 通向它的边的权重是1 ,而之前从节点0 通向节点4 的最小的权重边是4 。
我们选择下一个没有被添加到MST的节点,并且从节点1 ,有最小的加权边。这个节点就是节点4 。
更新后,我们有以下的图。

当我们考虑节点4 ,我们看到我们不能更新任何当前的边。也就是说,节点4 的两个邻居都已经属于MST,所以那里没有什么可更新的,我们只是在算法中继续前进,在这一步不做任何事情。
我们继续寻找一个与属于MST的节点相连的节点,并且具有最小的加权边。这个节点目前是2 ,它通过有权重的边连接到节点1 ,2 。图看起来如下。
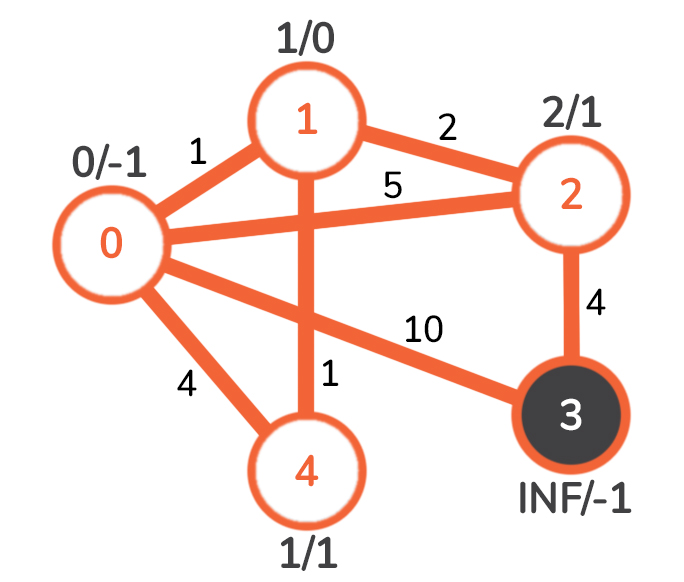
0 和1 两个节点都已经属于 MST,所以我们唯一可能去的节点是3 。从节点2 通向节点3 的边的权重是4 ,这显然小于之前从节点0 通向的10 。我们对其进行更新,得到以下图形。
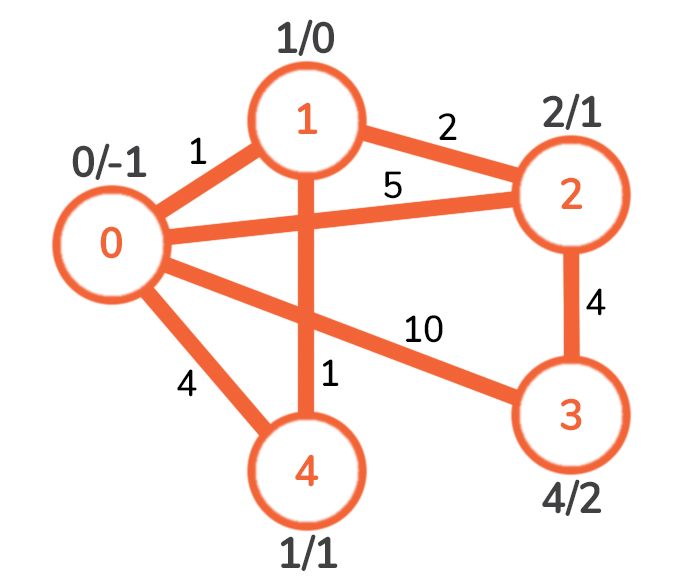
这样,我们已经访问了所有现有的节点,并将其添加到MST中,由于Prim的算法是一种贪婪的算法,这意味着我们已经找到了MST。
让我们回忆一下;被添加到跟踪我们的MST的数组中的边是以下内容。
- 权重的边缘
0-11 - 边缘
1-2的权重2 - 权重的边
1-41 - 权重的边
2-34
剩下的就是把组成MST的所有边加起来,之后我们得到我们例子中的图的MST的值是8 ,我们在这里结束了算法的执行。
Prim算法的时间复杂度是O((|E| + |V|)log|V|) ,其中|E| 是图中边的数量,|V| 是图中顶点(节点)的数量。
在Java中实现Prim的算法
有了一般的想法和可视化的方式,让我们在Java中实现Prim的算法。
在本指南中,我们将使用邻接矩阵的方法。请注意,我们也可以使用邻接列表来实现Prim的算法,但矩阵方法稍微容易一些,而且代码变得更短、更易读。
稍后要注意的一件事是,当我们初始化我们的邻接矩阵时,所有没有分配权重的地方将自动被初始化为0 。
图形类的实现
首先,我们要在我们的Graph 类中添加三个新的数组。
public class Graph {
private int numOfNodes;
private boolean directed;
private boolean weighted;
private double[][] matrix;
private double[] edges;
private double[] parents;
private boolean[] includedInMST;
private boolean[][] isSetMatrix;
// ...
}
让我们简单地看看这些数组分别代表什么。
edges代表一个数组,用于保存属于MST的、连接节点和父节点的边的值。parents给我们提供每个节点的父节点的信息。includedInMST告诉我们,我们要检查的节点是否已经属于MST中。
然后,我们将这些内容与之前声明的变量一起添加到构造函数中。
public Graph(int numOfNodes, boolean directed, boolean weighted) {
this.directed = directed;
this.weighted = weighted;
this.numOfNodes = numOfNodes;
// Simply initializes our adjacency matrix to the appropriate size
matrix = new double[numOfNodes][numOfNodes];
isSetMatrix = new boolean[numOfNodes][numOfNodes];
edges = new double[numOfNodes];
parents = new double[numOfNodes];
includedInMST = new boolean[numOfNodes];
for(int i = 0; i < numOfNodes; i++){
edges[i] = Double.POSITIVE_INFINITY;
parents[i] = -1;
includedInMST[i] = false;
}
}
我们已经为我们的每个单独的数组分配了numOfNodes 空间。这里的一个重要步骤是初始化。
- 开始时到每一个节点的距离被设置为
Double.POSITIVE_INFINITY。这基本上意味着我们还没有从任何其他节点到达该节点,因此到它的距离是Infinity。这个数字在Java中也代表Infinity,是一种数据类型。 - 由于在算法开始时没有一个节点被到达,每一个节点的父节点都被设置为
-1,表示该特定节点没有它所到达的父节点。我们可以将父节点的值设置为-1,原因是我们将节点从0到n-1,其中n是节点的数量,所以从逻辑上来说,有一个节点-1是没有意义的。 - 在算法的开始,没有一个节点属于MST,所以从逻辑上讲,不包括任何一个节点,即把
includedInMST中的每一个成员的值设为false。
addEdge() 和printMatrix() 方法保持不变,因为它们的作用都是不言自明的,我们就不深究了。
然而,我们确实需要额外的getters和setters,让我们能够改变上述数组。这些是以下内容。
public int getNumOfNodes() {
return numOfNodes;
}
public double getEdges(int i) {
return edges[i];
}
public void setEdges(double edge, int node) {
this.edges[node] = edge;
}
public boolean getIncludedInMST(int i) {
return includedInMST[i];
}
public void setIncludedInMST(int node) {
this.includedInMST[node] = true;
}
public double[][] getMatrix() {
return matrix;
}
public void setParents(double parent, int node) {
this.parents[node] = parent;
}
public double getParents(int i) {
return parents[i];
}
![]()
如果这些获取器/设置器中的任何一个不直观--每一个获取器和设置器都将在我们实现Prim的算法时使用它们时被额外解释。
至此,我们已经完成了对加权Graph 的适应性实现,我们可以继续讨论算法本身了。
Prim算法的实现
准备好了Graph ,我们就可以继续实现在它上面运行的算法了。让我们用一组节点和它们的边来初始化一个Graph 。我们将使用与前面章节中的可视化相同的节点和边的集合。
public class Prim {
public static void main(String[] args){
Graph graph = new Graph(5, false, true);
graph.addEdge(0, 1, 1);
graph.addEdge(0, 2, 5);
graph.addEdge(0, 3, 10);
graph.addEdge(0, 4, 4);
graph.addEdge(1, 2, 2);
graph.addEdge(1, 4, 1);
graph.addEdge(2, 3, 4);
// ...
}
}
使用graph.printMatrix() 打印出这个矩阵,输出如下。
/ 1.0 5.0 10.0 4.0
1.0 / 2.0 / 1.0
5.0 2.0 / 4.0 /
10.0 / 4.0 / /
4.0 1.0 / / /
我们还需要一个名为minEdgeNotIncluded() 的方法,找到通向尚未包含在MST中的邻居的最小加权边。
public static int minEdgeNotIncluded(Graph graph){
double min = Double.POSITIVE_INFINITY;
int minIndex = -1;
int numOfNodes = graph.getNumOfNodes();
for(int i = 0; i < numOfNodes; i++){
if(!graph.getIncludedInMST(i) && graph.getEdges(i) < min){
minIndex = i;
min = graph.getEdges(i);
}
}
return minIndex;
}
Infinity 在开始时,我们将min ,表示我们还没有找到最小的边。变量minIndex 代表我们正在寻找的最小边所连接的节点,我们在开始时将其初始化为-1 。之后,我们循环浏览所有的节点,寻找一个还没有被包含在MST中的节点,之后我们检查连接到该节点的边是否是 更小的比我们当前的min 边。
最后,我们准备实现Prim的算法。
public class Prim {
public static void main(String[] args){
// Initialized and added the graph earlier
int startNode = 0;
// Distance from the start node to itself is 0
graph.setEdges(0, startNode);
for(int i = 0; i < graph.getNumOfNodes()-1; i++){
int node = minEdgeNotIncluded(graph);
graph.setIncludedInMST(node);
double[][] matrix = graph.getMatrix();
for(int v = 0; v < graph.getNumOfNodes(); v++){
if(matrix[node][v] != 0 &&
!graph.getIncludedInMST(v) &&
matrix[node][v] < graph.getEdges(v)){
graph.setEdges(matrix[node][v], v);
graph.setParents(node, v);
}
}
}
double cost = 0;
for(int i = 0; i < graph.getNumOfNodes(); i++){
if(i != startNode){
cost += graph.getEdges(i);
}
}
System.out.println(cost);
}
}
代码本身可能有点混乱,所以让我们深入了解一下,并解释其中每一部分的作用。
首先,我们选择我们的startNode ,即0 。记住,我们需要一个节点来开始,这个节点可以是集合中的任何节点,但在这个例子中,它将是0 。我们将节点0 到自身的距离设定为0 。
在for 循环中,对于从0 到n-1 的每一个i ,我们寻找一个节点s ,以便使边i-s 是来自i 的最小的边。在我们找到相应的节点后,由于Prim的算法是一种贪婪的算法,我们确信从节点i 到任何其他节点都没有更小的边,除了s ,所以我们将s 添加到MST中。
接下来是通过节点s 的所有邻居。让我们回顾一下在邻接矩阵中如何处理非初始化的权重。
在我们的邻接矩阵中,所有没有被分配权重的地方将自动被初始化为
0。
这一点很重要,因为在matrix[i][j] 这个位置上的任何(负数或正数)数字都表示节点i 和j 之间存在一条边,而0 表示没有。
因此,一条边(和一个节点)被添加到MST中需要满足的条件有以下三个。
- 我们检查
matrix[i][j]的值是否与0不同,如果是,我们就知道该边存在,该值代表节点i和j之间的权重。 - 我们检查该邻居是否已经被添加到MST中。如果是,我们就跳过这个节点,继续寻找下一个邻居。
- 如果从节点
i到节点j的边的值小于从不同节点到节点j的已经存在的值,我们更新距离/父节点这一对来反映这种情况,即距离成为边i-j的值,我们到达节点j的父节点是节点i。
这大概总结了Prim的算法是如何工作的。剩下要做的就是通过edges 数组,把组成MST的所有边加起来,找到它的值。这正是我们代码的最后部分所做的,并将结果存储在cost 。
让我们用MST的输出来总结一下这个算法。
System.out.println("MST consists of the following edges:");
for(int i = 1; i < graph.getNumOfNodes(); i++){
System.out.println("edge: (" + (int)graph.getParents(i) + ", " + i + "), weight: " + graph.getEdges(i));
}
让我们运行它,看看输出。
MST consists of the following edges:
edge: (0, 1), weight: 1.0
edge: (1, 2), weight: 2.0
edge: (2, 3), weight: 4.0
edge: (1, 4), weight: 1.0
结论
在本指南中,我们已经涵盖并解释了如何使用Prim算法在Java中找到一个 ***最小跨度树(MST)***在Java中。
Prim算法和Kruskal算法是解决这个问题最常用的两种算法之一,它在设计计算机网络、电信网络和一般的网络等领域都有应用。
