

开源库TensorFlow.js大约在几年前推出。然而,直到现在我还没有设法去尝试它。在这篇文章中,我们将了解如何使用这项技术,并且我们将在一个真实世界的分类问题上做到这一点。我们的想法是利用TensorFlow.js的可能性,在浏览器或Node.js下构建和运行我们的机器学习和深度学习模式。说实话,我一开始是有点怀疑的。然而,这变成了一种很酷的方式,让网络开发者和数据科学家更紧密地联系在一起。
在这篇文章中,我们介绍了:
- 为什么要考虑Tensorflow.js?
- 安装
- 葡萄酒质量分类问题
- 数据分析
- 用Tensorflow.js实现
1.为什么要考虑Tensorflow.js?
从本质上讲,在使用TensorFlow.js时,我们可以考虑几个好处。对我来说,主要的好处是,你可以直接在浏览器中建立模型。除此之外,你还可以从Python中导入现有的预训练模型并重新训练它们。想象一下,你正在使用基于NoSQL JSON的数据库(如MongoDB)的JavaScript栈工作。这当然是我们应该考虑使用TensorFlow.js的用例。
TensorFlow.js包含了Keras API,并将其作为高级API公开。这非常好,它简化了构建机器学习和深度学习模型的过程。它还包括一个低级别的API,以前称为deeplearn.js,可用于线性代数和自动微分*。也支持急切执行。TensorFlow.js由WebGL驱动,这是一个JavaScript*API,用于在任何网络浏览器中渲染2D和3D图形,不需要插件。
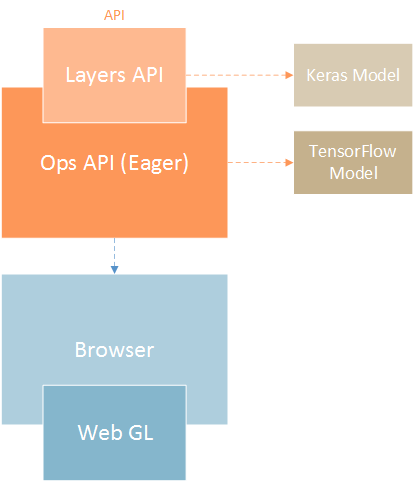
在这篇文章中,我们将使用TensorFlow.js建立一个简单的神经网络,它将解决一个简单的分类问题。然而,在此之前,让我们看看如何安装TensorFlow.js。
2.安装
我们有几种方法可以使用TensorFlow.js。首先,当然是通过在我们的主HTML文件中添加 脚本 标签在我们的主HTML文件中使用。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
你也可以用以下方式安装它 npm 或 纱在Node.js下进行设置。
npm install @tensorflow/tfjs
yarn add @tensorflow/tfjs

TensorFlow有GPU支持,性能更高。你可以像这样安装它。
npm install @tensorflow/tfjs-node-gpu
npm install @tensorflow/tfjs-node-gpu
只有当你的系统有一个支持CUDA的NVIDIA® GPU并且你使用Linux时,才可以使用这个选项。如果不是这种情况,你仍然可以通过使用TensorFlow与naitiveC++绑定来获得更好的结果。
npm install @tensorflow/tfjs-node
yarn add @tensorflow/tfjs-node
3.葡萄酒质量分类问题
如果你读过我们以前的一些文章,你可能会注意到我们喜欢使用这个数据集。这是因为这个数据集对于简单的 分类分析来说确实很好,但它来自真实世界。我们的目标是根据提供的化学数据来预测葡萄酒的质量。数据本身是关于Vinho Verde,一种来自葡萄牙米尼奥地区的独特产品。这种产品占葡萄牙葡萄酒总产量的15%,葡萄牙是世界上第十大葡萄酒生产国。

信息收集时间为2004年5月至2007年2月,由于隐私和物流问题,只提供了物理化学 和感官 变量。数据集中没有提供价格和产地的数据。数据集包含两个.csv文件,一个是红葡萄酒(1599个样本),一个是白葡萄酒(4898个样本)。在这篇文章中,我们将只使用白葡萄酒的样本。
每个样品都包含这些特征:
- 固定酸度
- 挥发性酸度
- 柠檬酸
- 残糖
- 氯化物
- 游离二氧化硫
- 二氧化硫总量
- 浓度
- pH值
- 硫酸盐
- 酒精含量
- 质量(0-10分之间)
4.数据分析
我知道在JavaScripuniverse中,一定有适合本章目的的库。但是,我懒得去找它们,所以数据的分析是在Python中完成的。如果你有建议,我可以为这些目的使用哪些JavaScript模块,请把信息发给我,我将非常感激。
数据分析是由几个子步骤本身组成的:
- 单变量分析- 分析每个特征的类型和性质。
- 缺失数据处理--检测缺失数据并制定相关策略。
- 离群点检测--检测数据中的异常情况。离群点是指在某些数据中偏离整体模式的样本。
- 相关分析--比较彼此之间的特征。
在单变量分析中,我们注意到输出数据的质量实际上是整数而不是类别。这将在实施过程中得到处理。除此以外,我们还注意到特征不在同一尺度上。这可能会导致一个问题,所以我们也需要在实施过程中处理这个问题。
 在缺失数据处理阶段,我们注意到有些样品的 固定酸度 特征是空的。我们的策略是用该特征的平均值来替换这一信息。也有其他的选择,比如用最大特征值来改变缺失值,或者一些默认值。让我们检查一下质量分布,检测一下离群值。
在缺失数据处理阶段,我们注意到有些样品的 固定酸度 特征是空的。我们的策略是用该特征的平均值来替换这一信息。也有其他的选择,比如用最大特征值来改变缺失值,或者一些默认值。让我们检查一下质量分布,检测一下离群值。

从上图中,我们可以看到大部分的葡萄酒都属于5到6的类别。这意味着大多数的葡萄酒都是平均水平,我们只有少数质量高或低的葡萄酒。最后,让我们检查一下相关矩阵(correlationmatrix)。
正如你所看到的,我们无法检测到对质量影响太大的特征。唯一能引起我们怀疑的是 残留糖分 特征和 密度 特征之间的高相关性 。然而,我们将把这两个特征留在游戏中,看看我们会在哪里着陆。
5.用Tensorflow.js实现
5.1 作为JSON的数据
数据集本身是以*.csv文件格式出现的。所以我们要做的第一件事就是将其转换为JSON文件并上传。你可以在这里找到整个新创建的JSON文件。一般来说,.csv文件中的每个样本现在都是一个单独的JSON*节点。下面是它的样子。
[
{
"fixed_acidity":7,
"volatile_acidity":0.27,
"citric_acid":0.36,
"residual_sugar":20.7,
"chlorides":0.045,
"free_sulfur_dioxide":45,
"total_sulfur_dioxide":170,
"density":1.001,
"pH":3,
"sulphates":0.45,
"alcohol":8.8,
"quality":6
},
{
"fixed_acidity":6.3,
"volatile_acidity":0.3,
"citric_acid":0.34,
"residual_sugar":1.6,
"chlorides":0.049,
"free_sulfur_dioxide":14,
"total_sulfur_dioxide":132,
"density":0.994,
"pH":3.3,
"sulphates":0.49,
"alcohol":9.5,
"quality":6
},
...
我们这样做是因为你知道,在JavaScript中处理JSON文件是很不方便的。
5.2 HTML文件
现在,让我们看看我们的index.html文件。
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Wine Quality Classification</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<script src="script.js"></script>
</body>
</html>
正如你所看到的,我们为TensorFlow.js添加了提到的脚本标签,并为tfjs-vis添加了附加标签。这是一个用于浏览器中可视化的小库。
5.3 JavaScript文件
除此以外,你可以注意到我们定义了script.js。这个文件与index.html位于同一个文件夹中。要运行这整个过程,你所要做的就是在你的浏览器中打开index.html。下面是script.js文件中的主 运行 函数的样子。
async function run() {
const data = await getData();
displayData(data);
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
const tensorData = prepareData(data);
const {inputs, outputs} = tensorData;
await trainModel(model, inputs, outputs, 100);
console.log('Done Training');
await evaluateModel(model, inputs, outputs);
}
这个函数本质上揭示了我们的工作流程。首先,我们使用getDatamethod从这个位置获取数据。
/**
* @desc retrieves data from defined location
* @return wine data as json
*/
async function getDataFunction() {
const wineDataReq = await fetch('https://raw.githubusercontent.com/NMZivkovic/file_hosting/master/wine_quality.json');
const wineData = await wineDataReq.json();
return wineData;
}
这可以通过使用fetch方法简单实现。之后,我们使用displayData来绘制一些有趣的图形。
/**
* @desc plots one
* @param array values - array of values
* @param string name - name of the plot
* @param string xoutput - x name
* @param string youtput - y name
*/
function singlePlot(values, name, xoutput, youtput)
{
tfvis.render.scatterplot(
{name: name},
{values},
{
xoutput: xoutput,
youtput: youtput,
height: 300
}
);
}
/**
* @desc plots one
* @param json data - complete json that contains wine quality data
*/
function displayDataFunction(data){
let displayData = data.map(d => ({
x: d.alcohol,
y: d.quality,
}));
singlePlot(displayData, 'Alchocol v Quality', 'Alchocol', 'Quality')
displayData = data.map(d => ({
x: d.chlorides,
y: d.quality,
}));
singlePlot(displayData, 'Chlorides v Quality', 'Chlorides', 'Quality')
displayData = data.map(d => ({
x: d.citric_acid,
y: d.quality,
}));
singlePlot(displayData, 'Citric Acid v Quality', 'Citric Acid', 'Quality')
}
注意,在上面的gist中,singlePlot函数也被介绍了。这个方法包装了tfjs-vis功能,只显示一个图形。displayData函数利用这个方法绘制了三个图形。下面是它们。
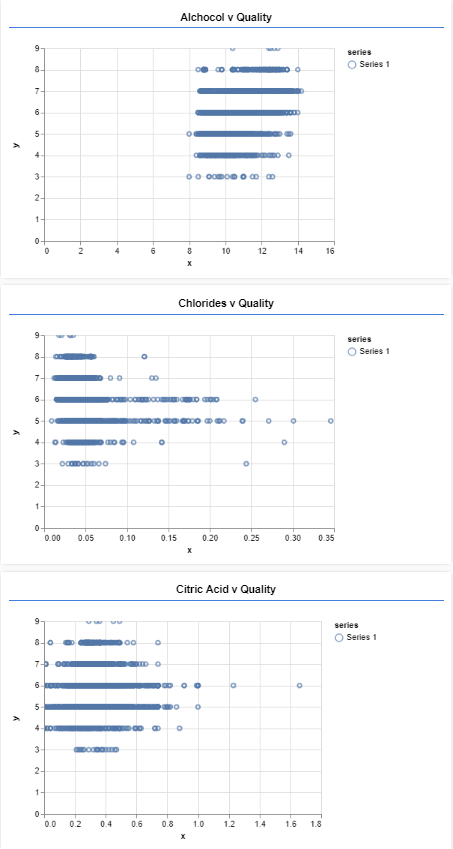
这里我们可以看到不同特征的质量分布。一旦我们将数据可视化,我们就可以创建我们的模型。这是在函数createModel中完成的。
/**
* @desc creates tensorflow graph
* @return model
*/
function createModelFunction() {
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [11], units: 50, useBias: true, activation: 'relu'}));
model.add(tf.layers.dense({units: 30, useBias: true, activation: 'tanh'}));
model.add(tf.layers.dense({units: 20, useBias: true, activation: 'relu'}));
model.add(tf.layers.dense({units: 10, useBias: true, activation: 'softmax'}));
return model;
}
这里的主要目标不是为这个问题生成一个完美的模型,而是尝试一些TensorFlow.js的可能性。如果你熟悉用Keras构建神经网络模型,这个API将很容易理解。然而,如果你想了解更多关于神经网络的知识,你可以在这里查看我们的一套电子书。
让我们快速浏览一下。我们使用sequential来为我们的模型创建一个占位符。这样,我们就可以在其中添加不同的层。然后,我们利用密集连接(dense)来添加密集连接的神经元层。在第一次调用中,我们创建了一个由50个神经元组成的隐藏层,以及一个由11个神经元组成的输入层。我们有11个输入,因为在我们的数据集中我们有11个特征。然后我们再增加两个隐藏层,分别有30和20个神经元。最后,我们的输出层有10个神经元,因为我们有10个可能的酒的类别。一旦我们用tfjs-vis打印出模型的摘要,我们得到的结果就是这样。

棒极了!现在,我们为模型本身准备数据。我们的模型不能使用JSON对象,也不能使用数组。我们需要创建张量对象。这是在prepareData函数中完成的。
/**
* @desc creates array of input data for every sample
* @param json data - complete json that contains wine quality data
* @return array of input data
*/
function extractInputs(data)
{
let inputs = []
inputs = data.map(d => [d.fixed_acidity, d.volatile_acidity, d.citric_acid, d.residual_sugar, d.chlorides, d.free_sulfur_dioxide, d.total_sulfur_dioxide, d.density, d.pH, d.sulphates, d.alcohol])
return inputs;
}
/**
* @desc converts data from json format to tensors
* @param json data - complete json that contains wine quality data
* @return tuple of converted data that can be used for training model
*/
function prepareDataFunction(data) {
return tf.tidy(() => {
tf.util.shuffle(data);
const inputs = extractInputs(data);
const outputs = data.map(d => d.quality);
const inputTensor = tf.tensor2d(inputs, [inputs.length, inputs[0].length]);
const outputTensor = tf.oneHot(tf.tensor1d(outputs, 'int32'), 10);
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const outputMax = outputTensor.max();
const outputMin = outputTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedoutputs = outputTensor.sub(outputMin).div(outputMax.sub(outputMin));
return {
inputs: normalizedInputs,
outputs: normalizedoutputs,
inputMax,
inputMin,
outputMax,
outputMin,
}
});
}
在这个函数中,我们首先将JSON对象转换成简单的数组。我们把数据分成输入和输出。在这个特殊的例子中,我们还没有把数据分成训练集和测试集,这是可以改进的地方。
一旦这样做了,我们就把它们转换成张量。最后,我们对数据进行归一化处理,也就是说,我们把它放在同一个尺度上。这是我们在数据分析阶段注意到的事情。另外,请注意,我们使用oneHotmethod将输出数据转换为分类变量。
所以,我们已经完成了所有的准备步骤,我们可以使用trainModel函数来训练我们的模型。
/**
* @desc trains model
* @return trained model
*/
async function trainModelFunction(model, inputs, outputs, epochs) {
model.compile({
optimizer: tf.train.adam(),
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
const batchSize = 64;
return await model.fit(inputs, outputs, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'accuracy'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
再一次,你可以注意到TensorFlow.js保留了与Python中TensorFlowAPI相似的API。我们用Adam优化器和cathegorical crossentropy编译我们的模型。然后我们用fitmethod调用来运行训练过程。这个过程也是可视化的。
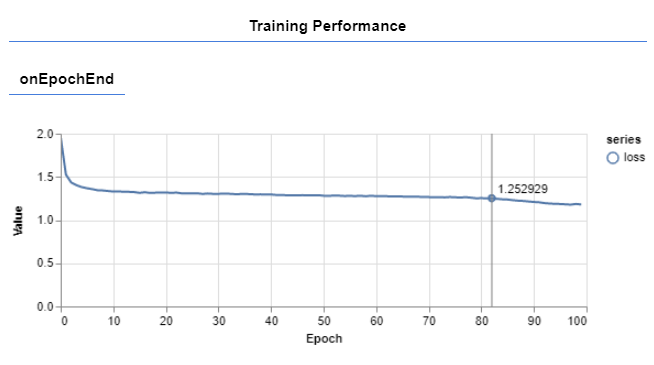
最后,我们使用evaluateModel方法来评估我们神经网络的准确性。这个方法只是对创建的模型的评估方法的一个封装。
/**
* @desc evaluates the model
*/
async function evaluateModelFunction(model, inputs, outputs)
{
const result = await model.evaluate(inputs, outputs, {batchSize: 64});
console.log('Accuracy is:')
result[1].print();
}
评估的输出被打印在控制台。
准确率是:0.7163332223892212
我们得到的准确率只有71%,这意味着我们的模型还有很多需要改进的地方。然而,我们能够在浏览器中完成这一切,这很了不起。
总结
在这篇文章中,我们学习了如何使用JavaScript进行机器学习和深度学习。我们弄清楚了如何使用TensorFlow.js制作基本模型并对其进行训练。在未来的文章中,我们将进一步研究这个库,并尝试用它来实现更复杂的架构。
谢谢你的阅读!
