

几天前,关于DALL-E 2及其从文字描述中创造出逼真图像的能力的新闻在全世界掀起了风暴。尽管,这个消息让我感到惊讶,但我几乎不感到惊讶。一段时间以来,机器学习和深度学习正在主导计算机视觉领域,工程师们正在想出越来越多有趣的解决方案。
从Facebook的标签建议到自动驾驶汽车,神经网络真的占领了这个世界。事实上,10年前人工智能的复兴始于其在计算机视觉中的应用。也就是说,在一个叫做图像分类的计算机视觉问题中。今天,我们可以在浏览器中使用JavaScript解决这个问题。让我们来看看我们如何做到这一点。
在这篇文章中,我们涵盖了:
- 什么是图像分类?
- 卷积神经网络--用于图像分类的神经网络(以及更多)
- 数据集和TensorFlow.js的安装
- 加载和准备数据
- 用Tensorflow.js实现图像分类
1.什么是图像分类?
图像分类,有时也被称为*图像识别,*是根据图像中出现的物体,将一个或多个 标签关联到给定的图像。如果我们只分配一个标签,我们说的是单标签分类,如果我们给图像分配多个标签,我们说的是多标签分类。
卷积神经网络(CNN).我们将在下一节详细介绍什么是CNN以及它们是如何工作的。然而,我们可以说,CNN是在2012年在 ImageNet大规模视觉识别挑战赛(ILSVRC)中打破记录后普及的。
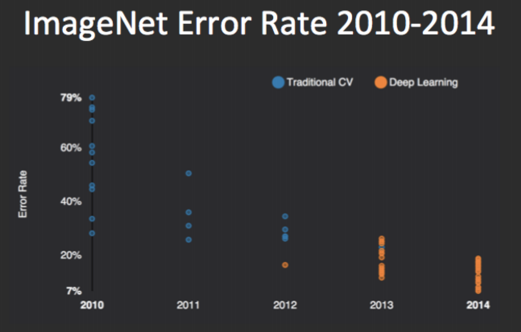
这个比赛评估了大规模的物体检测和图像分类的算法。他们提供的数据集包含1000个图像类别和超过120万张图像。图像分类算法的目标是正确预测物体属于哪个类别。自2012年以来,这个比赛的每个获胜者都使用了CNN。
2.卷积型神经网络--用于图像分类的神经网络(以及更多)
这种类型的神经网络早在20世纪90年代由Yann LeCun创建,他是今天Facebook的人工智能研究主任。与该领域的其他想法类似,这个想法也源于生物学。研究人员检测到,来自视觉皮层的单个神经元仅在被称为感受野的视野限制区域内对刺激做出反应。
因为不同神经元的这些领域是重叠的,它们共同构成了整个视觉领域。这实际上意味着,某些神经元 只有在视野中存在某种属性 时才会被激活,例如,水平边缘。因此,如果你的视野中有水平边缘,不同的神经元会被 "激活",而如果在我们的视野中有,比方说垂直边缘,不同的神经元会被激活。
例如,看一看这张图片,告诉我们你看到了什么。

这是一个众所周知的视错觉,最早出现在1892年的德国幽默杂志上。你可以注意到,你可以看到鸭子或兔子,这取决于你如何观察 这个图像。在这个和类似的错觉中发生的事情是,它们利用之前提到的视觉皮层的功能来迷惑我们。看一下下面的同一图像。

如果你的注意力徘徊在红色方块所在的区域,你会说你看到一只鸭子。然而,如果你的注意力集中在图像中标有蓝色方块的区域,你会说你看到一只兔子。
这意味着,当你观察到图像的某些特征时,不同的神经元组被激活,你将这个图像分类为兔子 或鸭子。这正是卷积神经网络利用的功能。它们检测图像上的特征,然后根据这些信息对其进行分类 。

我们将不讨论卷积神经网络如何工作的细节。你可以在这里阅读所有相关内容。然而,我们将强调一些 主要的组成部分。首先,所谓的卷积层检测图像的特征。这一层使用过滤器来检测低层次的特征,如边缘和曲线,以及更高层次的特征,如脸或手。
比卷积神经网络使用额外的层来去除图像的线性,这可能会导致过度拟合。当线性被去除后,就会使用额外的层来压缩图像**(投票**)并使 数据扁平化 。
最后,这些信息被传入一个神经网络,在卷积神经网络的世界里被称为全连接层。同样,本文的目标是向你展示如何实现所有这些概念,所以关于这些层的更多细节,它们是如何工作的,以及它们各自的目的是什么,可以在这里找到。

3.数据集和Tensorflow.js的安装
3.1 数据集
在之前的一篇文章中,我们使用Python 和Keras实现了这种类型的神经网络。我们创建了一个能够检测和分类手写数字的神经网络。为此,我们使用了MNIST数据集。
这是神经网络世界中一个著名的数据集。它的前身是**NIST**,它有一个由60,000个样本组成的训练集和由10,000个手写数字图像组成的测试集。所有数字的大小都已标准化并居中。图像的大小也被固定为28×28像素。这就是为什么这个数据集如此受欢迎。
使用卷积神经网络,我们可以得到几乎是人类的结果。说到这个数据集的预测准确性,记录是由平行计算中心(乌克兰,赫梅利尼茨基)保持的。他们使用了一个只有5个卷积神经网络的集合,得到的错误率为0.21%。基本上,他们在99.79%的情况下给出了正确的结果。真棒,不是吗?
对于我们计划在这里做的JavaScript实现,我们还需要一个简单的HTTP服务器。我使用的是这个,它可以用npm轻松安装。
> npm install http-server
它可以用命令来运行。
\> http-server
3.2 安装Tensorflow.js
我们有几种方法可以使用TensorFlow.js。首先,当然是通过在我们的主HTML文件中添加 脚本 标签在我们的主HTML文件中使用。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
你也可以用以下方式安装它 npm 或 yarn在Node.js下进行设置。
npm install @tensorflow/tfjs
yarn add @tensorflow/tfjs
4.加载数据
为了更快地加载 上述数据,谷歌的人给我们提供了这个精灵文件和这段代码,以便我们能够管理这个精灵文件。然而,我不得不对这段代码进行了一些调整,以更好地满足我的需求,所以它看起来是这样的。
const IMAGE_SIZE = 784;
const NUM_CLASSES = 10;
const NUM_DATASET_ELEMENTS = 65000;
const TRAIN_TEST_RATIO = 5 / 6;
const NUM_TRAIN_ELEMENTS = Math.floor(TRAIN_TEST_RATIO * NUM_DATASET_ELEMENTS);
const NUM_TEST_ELEMENTS = NUM_DATASET_ELEMENTS - NUM_TRAIN_ELEMENTS;
const MNIST_IMAGES_SPRITE_PATH =
'https://storage.googleapis.com/learnjs-data/model-builder/mnist_images.png';
const MNIST_LABELS_PATH =
'https://storage.googleapis.com/learnjs-data/model-builder/mnist_labels_uint8';
/**
* A class that fetches the sprited MNIST dataset and returns shuffled batches.
*
* NOTE: This will get much easier. For now, we do data fetching and
* manipulation manually.
*/
export class MnistData {
constructor() {
this.shuffledTrainIndex = 0;
this.shuffledTestIndex = 0;
}
async load() {
// Make a request for the MNIST sprited image.
const img = new Image();
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const imgRequest = new Promise((resolve, reject) => {
img.crossOrigin = '';
img.onload = () => {
img.width = img.naturalWidth;
img.height = img.naturalHeight;
const datasetBytesBuffer =
new ArrayBuffer(NUM_DATASET_ELEMENTS * IMAGE_SIZE * 4);
const chunkSize = 5000;
canvas.width = img.width;
canvas.height = chunkSize;
for (let i = 0; i < NUM_DATASET_ELEMENTS / chunkSize; i++) {
const datasetBytesView = new Float32Array(
datasetBytesBuffer, i * IMAGE_SIZE * chunkSize * 4,
IMAGE_SIZE * chunkSize);
ctx.drawImage(
img, 0, i * chunkSize, img.width, chunkSize, 0, 0, img.width,
chunkSize);
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
for (let j = 0; j < imageData.data.length / 4; j++) {
// All channels hold an equal value since the image is grayscale, so
// just read the red channel.
datasetBytesView[j] = imageData.data[j * 4] / 255;
}
}
this.datasetImages = new Float32Array(datasetBytesBuffer);
resolve();
};
img.src = MNIST_IMAGES_SPRITE_PATH;
});
const labelsRequest = fetch(MNIST_LABELS_PATH);
const [imgResponse, labelsResponse] =
await Promise.all([imgRequest, labelsRequest]);
this.datasetLabels = new Uint8Array(await labelsResponse.arrayBuffer());
// Create shuffled indices into the train/test set for when we select a
// random dataset element for training / validation.
this.trainIndices = tf.util.createShuffledIndices(NUM_TRAIN_ELEMENTS);
this.testIndices = tf.util.createShuffledIndices(NUM_TEST_ELEMENTS);
// Slice the the images and labels into train and test sets.
this.trainImages =
this.datasetImages.slice(0, IMAGE_SIZE * NUM_TRAIN_ELEMENTS);
this.testImages = this.datasetImages.slice(IMAGE_SIZE * NUM_TRAIN_ELEMENTS);
this.trainLabels =
this.datasetLabels.slice(0, NUM_CLASSES * NUM_TRAIN_ELEMENTS);
this.testLabels =
this.datasetLabels.slice(NUM_CLASSES * NUM_TRAIN_ELEMENTS);
}
nextDataBatch(batchSize, test = false) {
if(test)
return this.nextBatch(
batchSize, [this.trainImages, this.trainLabels], () => {
this.shuffledTrainIndex =
(this.shuffledTrainIndex + 1) % this.trainIndices.length;
return this.trainIndices[this.shuffledTrainIndex];
});
else
return this.nextBatch(batchSize, [this.testImages, this.testLabels], () => {
this.shuffledTestIndex =
(this.shuffledTestIndex + 1) % this.testIndices.length;
return this.testIndices[this.shuffledTestIndex];
});
}
nextBatch(batchSize, data, index) {
const batchImagesArray = new Float32Array(batchSize * IMAGE_SIZE);
const batchLabelsArray = new Uint8Array(batchSize * NUM_CLASSES);
for (let i = 0; i < batchSize; i++) {
const idx = index();
const image =
data[0].slice(idx * IMAGE_SIZE, idx * IMAGE_SIZE + IMAGE_SIZE);
batchImagesArray.set(image, i * IMAGE_SIZE);
const label =
data[1].slice(idx * NUM_CLASSES, idx * NUM_CLASSES + NUM_CLASSES);
batchLabelsArray.set(label, i * NUM_CLASSES);
}
const xs = tf.tensor2d(batchImagesArray, [batchSize, IMAGE_SIZE]);
const labels = tf.tensor2d(batchLabelsArray, [batchSize, NUM_CLASSES]);
return {xs, labels};
}
}
下面是这个MnistData类的一些主要内容。图像和这些图像的标签被加载到trainImages、testImages、 trainLabels和testLabels字段中。这个函数需要首先被调用。一旦完成,我们就可以使用方法nextDataBatch从这些数据集中获得成批的 数据。在下面,这些方法是用不同的图像和标签调用nextBatch函数。这个函数也将数据转换为张量 ,这是处理所必需的。
5.用Tensorflow.js实现图像分类
让我们从我们解决方案的index.html文件开始。在之前的文章中,我们介绍了几种安装TensorFlow.js的方法。其中之一是将其集成到HTML文件的脚本标签中。这就是这里要做的。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Convolutional Neural Networks</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<script src="./data.js" type="module"></script>
<script src="./script.js" type="module"></script>
</head>
<body>
</body>
</html>
请注意,我们为TensorFlow.js添加了脚本标签,并添加了tfjs-vis。这是一个用于浏览器内 可视化的小库。在这个HTML文件中,我们导入了data.js文件,它应该与index.html文件和script.js文件位于同一个文件夹中。我们的完整实现就在这个文件中。为了运行整个过程,你所要做的就是在你的浏览器中打开index.html。
现在,让我们来看看script.js文件,它是大部分实施方案的所在地。下面是主 运行函数的样子。
async function run() {
const data = await getData();
await displayDataFunction(data, 30);
const model = createModel();
tfvis.show.modelSummary({name: 'Model Architecture'}, model);
await trainModel(model, data, 20);
await evaluateModel(model, data);
}
你可以注意到,这个函数与上一篇文章中的函数相似。它揭示了应用程序的工作流程 。在开始时,我们使用getDatafunction加载数据。
async function getDataFunction() {
var data = new MnistData();
await data.load();
return data;
}
首先,我们创建一个MnistData类的对象 。这个类位于data.jsfile中。然后,我们调用提到的加载 函数。它将初始化 创建对象的属性。一旦完成,我们就可以返回这个对象,用displayData函数在浏览器中显示输入数据。
async function singleImagePlot(image)
{
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(image, canvas);
return canvas;
}
async function displayDataFunction(data, numOfImages = 10) {
const inputDataSurface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
const examples = data.nextDataBatch(numOfImages, true);
for (let i = 0; i < numOfImages; i++) {
const image = tf.tidy(() => {
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = await singleImagePlot(image)
inputDataSurface.drawArea.appendChild(canvas);
image.dispose();
}
}
在这个函数中,我们首先创建一个名为输入数据的新标签。然后我们使用MnistData类的nextDataBatch函数获得一批测试数据。然后我们遍历这些图片,并将其从张量转换为可以显示的数据。最后,我们在创建的标签中显示它们。

一旦数据被可视化,我们就可以进入更有趣的实现部分并创建模型。这是在函数createModel中完成的。
function createModelFunction() {
const cnn = tf.sequential();
cnn.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
cnn.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
cnn.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
cnn.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
cnn.add(tf.layers.flatten());
cnn.add(tf.layers.dense({
units: 10,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
cnn.compile({
optimizer: tf.train.adam(),
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return cnn;
}
基本上,我们创建了两个卷积层,之后是最大轮询层。最后,我们将数据平铺到一个数组中,并将其放入全连接层,在本例中,这只是一个有10个神经元的密集层。这最后一层实际上是输出层,它预测图像的类别。然后用分类交叉熵和Adam优化器对模型进行编译 。一旦我们用tfjs-vis打印出模型的摘要,我们得到的结果就是这样。

酷!"。现在,我们已经准备好了输入数据和模型,所以我们可以训练它。这是在trainModel函数中完成的。
async function trainModelFunction(model, data, epochs) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const batchSize = 512;
const [trainX, trainY] = getBatch(data, 5500);
const [testX, testY] = getBatch(data, 1000, true);
return model.fit(trainX, trainY, {
batchSize: batchSize,
validationData: [testX, testY],
epochs: epochs,
shuffle: true,
callbacks: fitCallbacks
});
}
基本上,我们得到一批训练数据和一批测试数据。然后我们在模型上点燃拟合方法,将训练数据用于训练 ,将测试数据用于评估。损失和准确度等指标在每个 epoch 后使用tf-vis 显示出来。

这个过程的最后一步是对我们的模型进行评估 。为此,我们显示每个数字的准确性 ,我们使用混淆矩阵的概念。这个矩阵只是一个表格,通常用来描述分类模型的性能。这一切都在evaluateModelf 函数中完成。
function predict(model, data, testDataSize = 500) {
const testData = data.nextDataBatch(testDataSize, true);
const testxs = testData.xs.reshape([testDataSize, 28, 28, 1]);
const labels = testData.labels.argMax([-1]);
const preds = model.predict(testxs).argMax([-1]);
testxs.dispose();
return [preds, labels];
}
async function displayAccuracyPerClass(model, data) {
const [preds, labels] = predict(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function displayConfusionMatrix(model, data) {
const [preds, labels] = predict(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(
container, {values: confusionMatrix}, classNames);
labels.dispose();
}
async function evaluateModelFunction(model, data)
{
await displayAccuracyPerClass(model, data);
await displayConfusionMatrix(model, data);
}
正如你所看到的,这个函数正在使用诸如displayAccuracyPerClass、displayConfusionMatrix 和predict 等辅助函数来制作这些图表。

我们在这个简单的模型中得到了相当好的结果,而且只用了20个epochs。我们可以通过增加卷积层或增加epochs的数量来改善 这些结果。当然,这也会对训练过程的长度产生影响。
总结
在这篇文章中,我们有机会看到我们如何利用TensorFlow.js的卷积神经网络。我们学习了如何操作这种类型的神经网络的特定层,并在浏览器中运行它们。
谢谢你的阅读!
