

在这篇文章中,我们将详细了解预训练模型PoseNet,其中包括posenet的需求和工作,可能的操作,它的应用,以及对现有posenet模型的可能改进。
我们将学到什么?
- 什么是Posenet?
- Posenet如何工作?
- 解释Posenet中使用的关键词
- Posenet的必要性
- 对PoseNet的操作
- 姿势网的结构
- 关于谷歌网络
- CNN中的全连接层
- Posenet中的损失函数
- 对Posenet结构的改进
- 总结
什么是PoseNet?
Posenet是预先训练好的模型,用作后期检测技术,可以在给定的视频和图像中检测出人类的姿势。换句话说,Posenet是一个深度学习的张量模型,它通过估计身体的各个部分作为关键点(这个模型总共有17个关键点),即鼻子、右肘、右腕等,这些关键点相互连接,形成身体的骨架结构,并给所有的点打上信心分数,因为这个模型只估计它们来识别一个姿势。
- Posenet可以估计单个或多个姿势。要么,我们可以通过使用像
ml5.js,ps5.js和Tensorflow.js这样的库来确定物体的实时姿势,要么我们可以使用同样的库对图像集进行姿势检测,如COCO数据集等。
注意:
ml5.js,ps5.js将在浏览器中工作,因为它几乎不需要python知识,而如果你想使用python实现,tensorflow.js是一种方法,它也可以在浏览器中工作,但唯一的区别是它提供了python支持。
Posenet是如何工作的?
- Posenet是在MobileNet架构中训练的。MobileNet是谷歌在ImageNet数据集上开发的一个卷积神经网络,主要用于图像分类和使用置信度分数的目标估计。
PoseNet模型的一些好处!!
另外,Posenet是一个轻量级的模型,它使用深度可分离的卷积来加深网络,减少参数,计算成本,这反过来又增加了模型的准确性。因此,作为轻量级的模型,它很容易在网络浏览器上运行,也就是说,Posenet是可以在浏览器上运行的预训练模型。这将它与其他依赖API的库区分开来,使得任何人在笔记本电脑或个人桌面上的配置有限的情况下,广泛使用这个模型。
Posenet总共使用了17个关键点,从我们的眼睛、耳朵到脚踝和膝盖,还包括手腕、肘部、肩膀和鼻子。
如果给Posenet的图片不清楚,那么它就会返回信心分数,告诉它对图片中的特定姿势有多大信心。这是以
JSON响应的形式完成的。
Posenet中使用的关键词解释:!!!!
姿势估计是通过卷积神经网络对输入的RGB图像进行处理,在此基础上应用多姿势或单姿势算法,通过说明图像中的姿势、其姿势置信度分数、关键点位置及其关键点置信度分数来提供模型输出。
让我们逐一查看每个关键词。
- 姿势PoseNet:PoseNet返回姿势对象(可以是单个或多个对象)的所有关键点,以及作为输入的图像中每个检测到的人的实例级置信度得分。
- 姿势置信度得分分数:它通过估计分数的置信度来确定姿势的整体准确性,其范围从0.0到1.0。如果输入的图像数据集不够强大,这可以被隐藏。
- 关键点如前所述,人的一部分姿势是通过Posenet本身返回的一些点来估计的,目前只包括17个点,例如:鼻子、左脚、左膝、右耳、左臀、右肘等。
所有的点在图像中显示如下[图(A)]
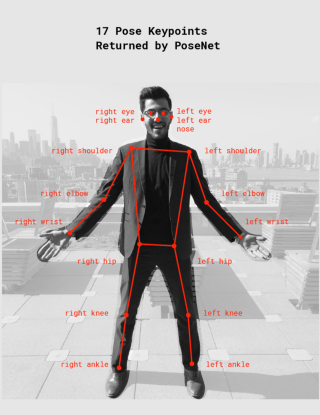
- 关键点置信度得分信度:这决定了对估计的关键点的准确性的信心,其范围在0.0到1.0之间。与姿势信心分数一样,如果认为不够强大,它可以用来隐藏关键点。
- 关键点位置识别:我们将给模型的输入图像分为关键点,简而言之就是检测整个图像中有用关键点的二维(x,y)坐标。
Posenet的必要性
- 通常,Posenet,vSLAM这些相机姿态估计模型需要大量的标记数据,这可以通过使用迁移学习来减少。同时,通过CNN在大型图像分类数据上学习到的重现,可以通过使用更小的数据集来解决摄像机姿势估计的问题。
- 传统的vSLAM算法和解决方案已被提出用于各种环境和应用,其中大多数都有类似的结构。因此,他们面临着同样的限制,正是。
由于运动模糊、高速旋转、部分遮挡和场景中的动态物体的存在,经常失去跟踪。这使得它们不适合像无人驾驶飞行器这样的情况。
- 最常见的vSLAM算法依赖于昂贵的管道,包括手工制作的数据库特征、相机的固有参数、关键帧的选择和存储、在一组图像中寻找一些特征对应等。此外,对于单眼图像来说,它还存在着一种现象,叫做 比例漂移导致不一致的相机轨迹。
- 为了摆脱所有这些问题,Posenet提供了端到端的可训练架构。现在,我们将了解Posenet架构。
Posenet的架构
在这一节,我们将了解Posenet的架构和细节。
- Posenet使用修改过的GoogleNet,并利用ImageNet数据集的迁移学习,该数据集用于分类任务,以训练使用单眼图像的姿势检测网络。此外,他们通过策划和制作优化所需的更复杂的损失函数来提高性能。通过使用LSTM单元来更好地利用每个图像中的空间信息,这一点得到了进一步的改善。
- 为了使Posenet解决方案比vSLAM解决方案更准确,可以使用哪些信息来获得数据集的属性,而不需要施加更复杂的CNN架构。
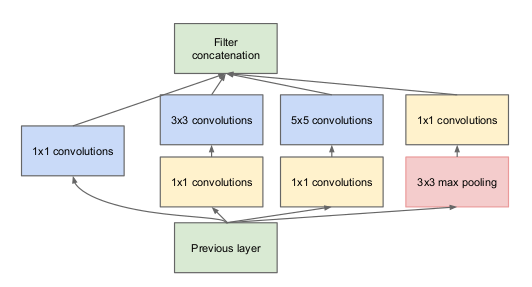
- GoogleNet是为物体分类和检测而设计的,它有一个基于inception模块的22层深度神经网络,如下图所示。
起始模块也被称为起始层。[图(B)]
- 与vSLAM算法不同,Posenet在单眼图像上工作,而且对运动模糊和光照条件(如果它们不断变化)具有鲁棒性。此外,它们不需要访问相机参数、良好的初始化和手工制作的特征。
关于谷歌网络
- 用于图像检测和分类的GoogleNet是一个基于Inception模块的22层深度神经网络,如图(B)所示。
- GoogleNet接受224×224像素的输入,并通过9个堆叠在一起的初始模块传播,使用ReLu
修正的线性单元:其输出为f(x)=Max(0,x)。它的确切用途是比其他非线性函数如:sigmoid,tanh的性能更好,而且,CNN可以学习非线性值,这使得它可以用于现实世界。
- 就像这样,输入数据被抽象化,停留在最后一层,同时还有两个中间抽象到全连接层和softmax层,以帮助预测对象类别。
作为CNN的最后一层,它将卷积过程的输出作为输入,并多次应用线性变换,最后用激活函数来预测图像的类别。
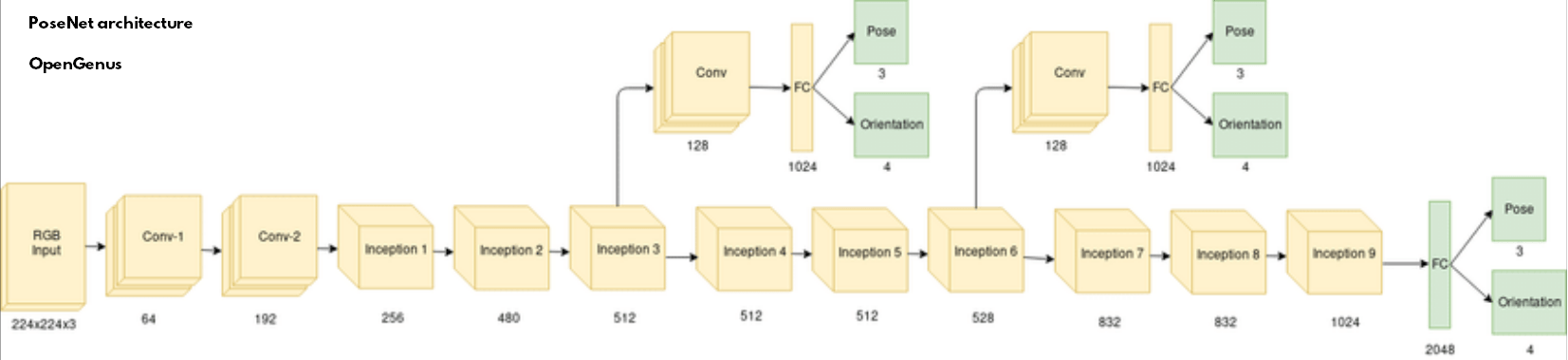
但是,在posenet中,softmax层(帮助对图像进行分类)被两个平行的全连接层所取代,它们分别有3个或4个单元。此外,它还在最后一个初始模块的顶部增加了2048个单元的全连接层。
Posenet架构如下所示:[图C]
对PoseNet的操作
在posenet上有3个功能,即姿势、方向和全连接层,它们与所有的初始模型、卷积过程和最后一个初始模块顶部的2048单元FC层相连接。
CNN中的全连接层
- 当输入、卷积和池化层使特征提取部分成为可能时,卷积过程的输出是全连接层的输入,它预测不同图像的不同类别。
- 我们已经知道,该层通过多次应用线性变换对输入进行转换,并将其送至激活函数以预测类别。
- 给予该层的输入就像给予神经网络层一样。
这里的特征图矩阵被转换为向量<x1,x2,x3,x4.....>。在全连接层的帮助下,结合它们,我们创建了所需的模型。然后,通过使用Sigmoid、softmax、ReLu,我们得到了模型中输入的物体的类别。虽然,softmax分别用3个或4个单元取代了2个平行的全连接层。这些通常是回归到姿势(表现为(x,y,z)坐标)和方向(以四元数表示)。
Posenet中的损失函数
- 根据上面描述的模型,输出矢量x*'和四元数q'*分别代表估计的位置和方向。网络中的这些参数对每个图像I进行了优化,其损失函数计算如下。
损失(I)= ||x-x*'||2*+ß||q-q*'||2*
这里,x表示地面真实位置,q表示方向。由于四元数被限制在单位流形范围内,方向误差变得最小,比位置误差小。这就是为什么ß被用来平衡损失项的原因,它是一个恒定的比例因子。
但是,Posenet的作者替换了这个恒定的比例因子,以适应提高网络的精度和摄像机姿势回归的损失函数。
新的损失函数是根据同调不确定性制定的。
损失(I)=||x-x*'||2×* e(-ŝx)+ ŝx +||q-q*'||2×* e(-ŝq)+ ŝq
对Posenet结构的改进
一些改进可以通过使用整个视场作为输入,在图像周围使用更多的局部序列,从而产生最佳的输出,并对序列帧进行降采样,在训练和测试数据之间有足够的重叠。数据增强可以减少测试和训练数据之间的差值。而且,通过使用LSTM单元(即使是长度为1的单元),其平均表现与较长的序列长度一样好。这是因为与CNN的全连接层相比,它们的结构相对更复杂,甚至在单张图像的输入上也能明显看出。
我们可以说,Posenet可以通过赋予视野比输入图像的分辨率更多的重要性而得到改进。另外,根据训练标签,我们可以在训练期间以更高的精度覆盖更多的区域,在测试时也能获得更高的精度。最后,我们可以说LSTM单元在时间信息上不是那么有用,因为它对小的平移是不变的,但由于其复杂的性质,与它们的对应的全连接层相比,它们确实表现更好。
总结
我们在OpenGenus的这篇文章中了解了posenet,以及为什么它需要超过vSLAM算法。此外,我们还看到了posenet的架构,以及如何通过LSTM、增加视场和数据增强来改进它。此外,我们还了解了GoogleNet以及对posenet的操作。此外,我们还学习了posenet中需要的重要关键字和损失函数。
