


Vector byiconicbestiary
关键的经验之谈
- 大多数对进入数据科学领域感兴趣的初学者总是担心数学要求。
- 数据科学是一个非常量化的领域,需要高级数学。
- 但要想入门,你只需要掌握一些数学题目。
- 在这篇文章中,我们将讨论统计和概率在数据科学和机器学习中的重要性。
统计学和概率论
统计和概率用于特征的可视化、数据预处理、特征转换、数据归纳、降维、特征工程、模型评估等。本文将重点介绍该领域初学者的基本统计和概率概念,即。均值或期望值、方差和标准差、置信区间、中心极限定理、相关性和协方差、概率分布和贝叶斯定理。
平均数或期望值
假设 X是一个有N个观测值的随机变量,那么X 的均值由以下公式给出
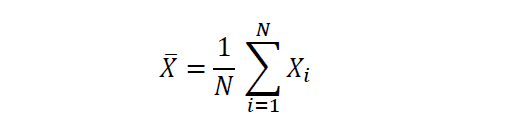
平均值或期望值是一种中心趋势的量度。
方差和标准差
假设X是一个有N个观测值的随机变量,那么X的方差由以下公式给出。
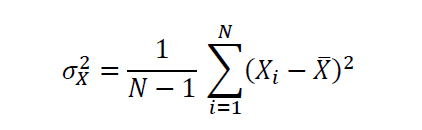
标准差是方差的平方根,是对不确定性或波动性的一种测量。
信心区间
假设随机变量X是正态分布,那么68%和95%的置信区间*(CI*)由以下公式给出
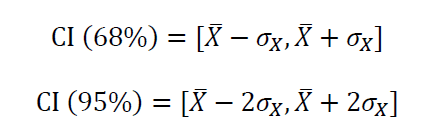
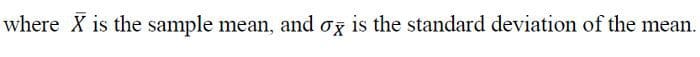
中心极限定理(CLT)
中心极限定理(CLT)指出,概率分布样本的平均值是一个随机变量,其平均值由人口平均值给出,标准差由人口标准差除以N的平方根给出,其中N是样本大小。
让 是人口平均值,
是人口标准差。如果我们从规模为N的人口中抽取一个小样本,那么根据CLT,样本平均值为
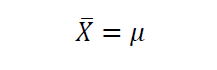
而样本的标准差为
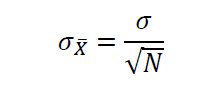
相关性和协方差
相关性和协方差是对数据集中共同运动的衡量。为了量化特征之间的相关程度,我们可以用这个公式来计算协方差矩阵。
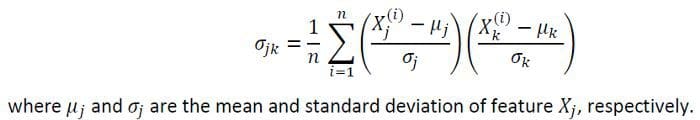
概率分布
尽管我们总是假设数据集中的变量或特征是正态分布的,但绘制概率分布图以直观了解特征的分布情况是很重要的。例如,使用R的dslabs包中的高度数据集,我们可以计算出数据集中所有高度的概率分布,如下图2所示。
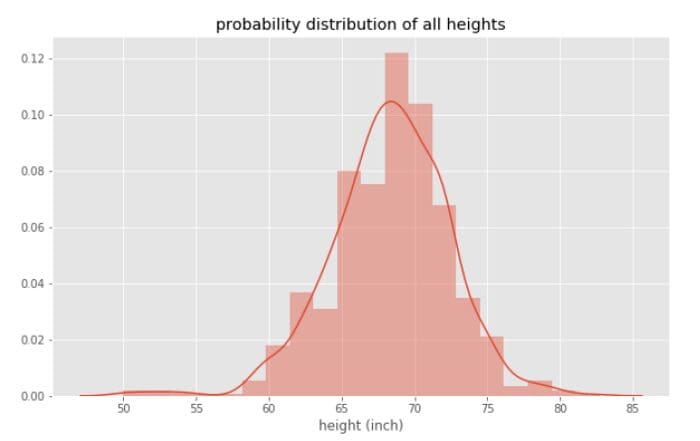
图2
从图2中,我们观察到高度数据集近似于正态分布,其平均值约为68英寸。现在,如果我们分别绘制男性和女性身高的概率分布,我们会观察到两条不同的曲线,如图3所示。
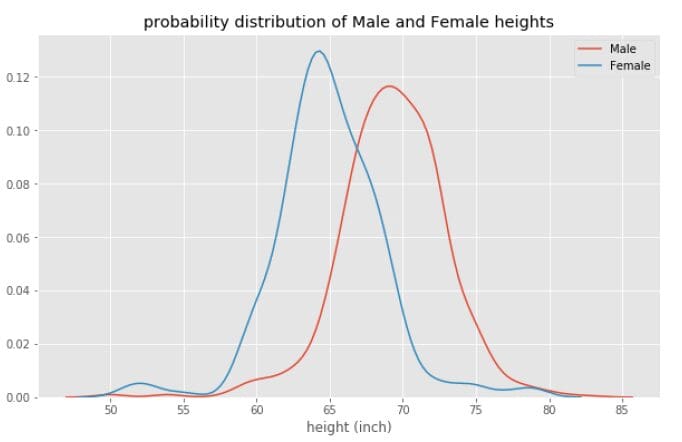
图3
从图3中,我们观察到女性的平均身高(约63英寸)小于男性的平均身高(约69英寸),这表明从统计学上讲,男性平均比女性高。欲了解更多信息和用于生成图2和图3的代码,请参见这篇文章。贝叶斯定理的解释。
贝叶斯定理
贝叶斯定理在二元分类问题中起着重要作用。它被用来解释二元分类算法的输出。贝叶斯定理指出,两个事件A和B的条件概率通过这个方程相关。
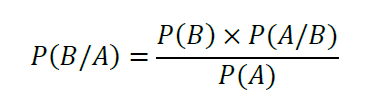
关于贝叶斯定理在二元分类问题中的实现,请看这篇文章。贝叶斯定理详解。
总结
综上所述,我们已经讨论了概率和统计学中的7个重要概念,这些概念对于数据科学的初学者来说是必不可少的。其他高级主题包括AB测试、假设测试、蒙特卡洛模拟等。
