

本文将解释如何使用数据库快照执行ETL,以及如何利用数据库快照执行从操作数据库到数据仓库的增量数据提取。
简介
正如你所知,由于许多原因,ETL(提取-转换-加载)操作是数据仓库中最具挑战性的任务之一。 在ETL中,最困难的任务之一是确定来自源的增量数据集。在上一篇文章《使用复制来改善SQL Server中的ETL过程》中,我们研究了如何使用复制来改善数据仓库中的ETL过程。
下面是数据仓库的示意图,它显示了ETL如何将操作数据源连接到数据仓库,以执行各种类型的数据分析,如OLAP立方体、仪表盘、报告、透视表等。
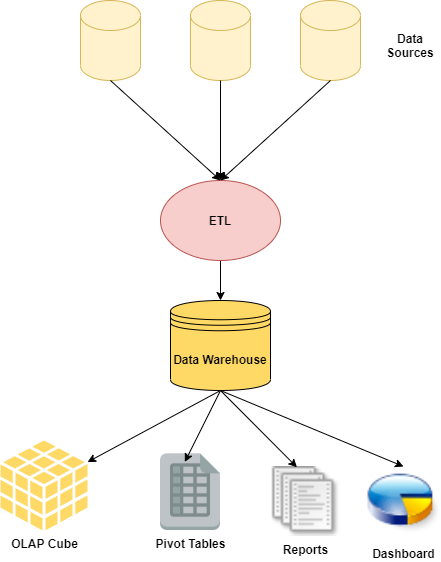
如你所知,数据仓库从多个来源提取数据,这些来源可以是数据库或任何其他来源。由于ETL以批处理模式运行,通常是每天一次,所以识别从上一次运行到新的运行之间所修改的数据很重要。如你所知,大多数运行中的数据库会经历许多变化,提取这些包括插入、更新和删除的修改是非常重要的。
根据不同的数据源,有许多不同的增量数据提取选项,我们将讨论如何在作为操作数据源的SQL Server数据库上进行增量数据提取。在这篇文章中,我们将具体讨论如何在操作数据源中使用数据库快照来进行ETL提取增量数据。
数据库快照如何工作
在我们讨论使用数据库快照实现ETL之前,让我们看看数据库快照是如何工作的以及它的架构。
顾名思义,数据库快照给你一个特定时间的数据库状态。因此,让我们看看如何在SQL Server中创建一个数据库快照。到目前为止,在SQL Server中还没有提供创建数据库快照的用户界面,你必须使用下面的脚本。
CREATE DATABASE ssTransactionSystem_dbss20211017
ON _( NAME = TransactionSystem,
FILENAME = _'C:\SP\Data\ssTransactionSystem_dbss20211017.ss' )
AS SNAPSHOT OF TransactionSystem;
在上面的脚本中,TrnsactionSystem是操作数据库,而ssTransactionSystem_dbss20211017是快照数据库名称,这就是你要调用的数据库名称。FILENAME提供了稀疏文件的路径。一旦执行上述脚本,将创建空的备用文件,如下图所示。
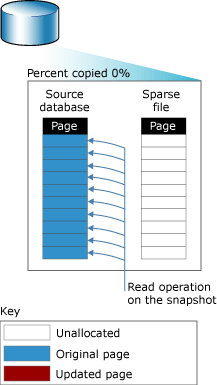
来源:MSDNMSDN
当对源操作数据库进行修改时,原来的数据页会在修改前被移到稀疏文件中,如下图所示。
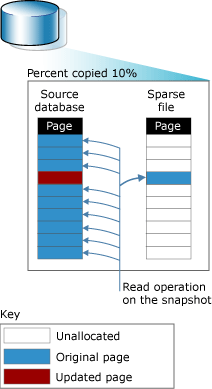
来源:MSDNMSDN
当你从数据库快照中读取修改前的数据时,会从稀疏文件中读取,而未修改的数据则会从原始数据源中读取。通过这样做,你可以按照数据库快照的最后创建时间来获得数据。这些快照在快照节点下可用。
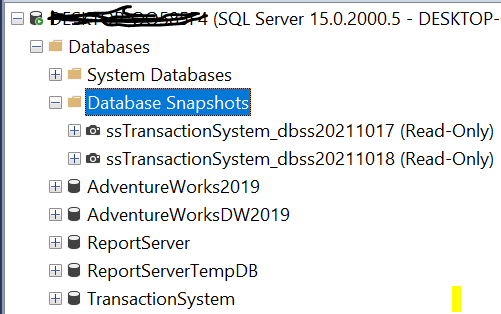
正如你在上图中看到的,数据库快照是可用的,我们可以从这个数据库中进行查询,就像你从一个典型的数据库中进行查询一样,不需要了解数据库快照的架构。
SELECT database_id
,NAME
,DB_NAME(source_database_id) SourceDatabase
FROM sys.databases
上面的查询显示了数据库的列表,以及哪些是快照数据库和它们的源数据库。
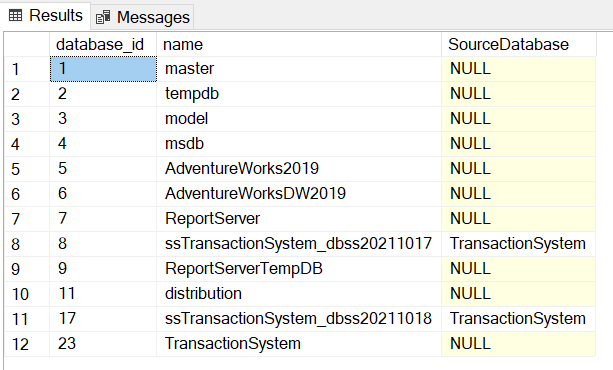
你可以看到,两个数据库快照是从TransactionSystem数据库中创建的。
使用数据库快照实现ETL
在大多数情况下,ETL是一种批处理模式,通常在午夜执行。在建议的方法中,ETL过程是在创建数据库快照后开始的,下面是它的脚本。
DECLARE @exceqry AS VARCHAR(1500)
,@dbname VARCHAR(500)
,@snapshotQuery VARCHAR(5000)
SET @dbname = 'ssTransactionSystem_dbss' + CAST(YEAR(GETDATE()) AS VARCHAR(4)) + CAST(MONTH(GETDATE()) AS VARCHAR(4)) +
CAST(DAY(GETDATE()) AS VARCHAR(4))
SET @exceqry = 'DROP DATABASE ' + @dbname
IF EXISTS (
SELECT 1
FROM sys.databases
WHERE NAME = @dbname
)
EXEC (@exceqry)
SET @snapshotQuery = 'CREATE DATABASE ' + @dbname + ' ON _( NAME = TransactionSystem, FILENAME = _''C:\DineshA\Data\' +
@dbname + '.ss'') AS SNAPSHOT OF TransactionSystem; '
EXEC (@snapshotQuery)
上述脚本将在数据库快照可用的情况下放弃,并创建一个新的数据库快照。如果你需要更频繁地安排ETL,你需要稍微修改上述查询。
接下来就是要找出如何使用数据库快照提取ETL的数据。由于我们有前一天和今天的快照,因此如下面的脚本所示,这是一个比较两个数据库的问题。
SELECT 'INS' Type
,SalesOrderID
FROM ssTransactionSystem_dbss20211018.Sales.SalesOrderHeader
WHERE SalesOrderID NOT IN (
SELECT SalesOrderID
FROM ssTransactionSystem_dbss20211017.Sales.SalesOrderHeader
)
UNION ALL
SELECT 'DEL' Type
,SalesOrderID
FROM ssTransactionSystem_dbss20211017.Sales.SalesOrderHeader
WHERE SalesOrderID NOT IN (
SELECT SalesOrderID
FROM ssTransactionSystem_dbss20211018.Sales.SalesOrderHeader
)
正如你所看到的,你可以很容易地发现插入和删除,如下图所示。
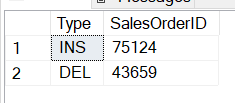
同样,你也可以发现修改的情况。这些数据可以被转移到一个暂存环境,然后执行必要的转换和加载操作。
优势
使用数据库快照进行ETL的主要优势之一是,数据库快照的创建时间是可以忽略不计的,因为你只是在创建一个空文件。这意味着无论是大的还是小的操作数据库,创建数据库快照的时间都非常短。因此,当我们使用ETL时,使用数据库快照不会对时间长度产生影响。
数据库快照的另一个重要因素是,当从数据库快照中读取数据时,不会对源数据进行任何锁定。这是一个非常重要的特点,因为ETL处理的是大量的数据,如果你直接读取这些数据,通常会对源数据产生额外的负荷。
由于数据库快照可以在镜像数据库的基础上创建,所以使用数据库快照的ETL可以在镜像数据库上使用。这是一个很好的选择,因为我们可以利用闲置的镜像数据库进行ETL。
限制因素
虽然使用数据库快照的ETL有一些重要的功能,但也有一些需要担心的限制。其中一个重要的限制是,数据库快照是紧紧附着在源数据库上的。因此,你不能将数据库快照从操作数据库中分离出来。这可以从数据库快照的架构中看出。这意味着,当从数据库快照中读取数据时,将导致额外的服务器性能,从而影响源系统。
这种机制至少需要两个数据库快照。如果你没有放弃之前创建的数据库快照,那么将会对运行系统产生性能影响,因为当有数据变化时,源系统必须更新数据库快照的所有稀疏文件。
数据库快照有更多的限制,当文件流在数据库中被启用时,它们不能被应用。 此外,如果你的数据库被配置为全文搜索,你同样不能配置数据库快照。
如果你在SQL Server 2016版本之前使用数据库快照,你必须使用SQL Server企业版。然而,从SQL Server 2016到SQL Server 2019,数据库快照不仅支持企业版,也支持标准版、网络版,甚至支持SQL Server的Express版。
总结
在这篇文章中,我们讨论了一种从操作数据库中提取数据的新方法。在这篇文章中,我们讨论了如何使用数据库快照进行ETL,以改善ETL过程。虽然你不能从源数据库中删除数据库快照,但为了提取最后一批之间的修改数据,可以使用数据库快照。
