

- 关于
- 学习
- 社区
- 开始编码
博客用NativeJDB调试本地编译的Java代码
2022年6月29日#java#debugger#native#cloud#container
用NativeJDB调试原生编译的Java代码

作者:Mandana Vaziri

共同作者:。Ansu Varghese,研究型软件工程师,IBM
与以下人员合作。
Max Andersen, Dimitris Andreadis, Andrew Dinn, Stuart Douglas, Jason Greene, David Grove, David Lloyd, Thomas Qvarnstrom, Foivos Zakkak, Galder Zamarreno (IBM Research and Red Hat)
Quarkus是一个云原生Java开发框架,它允许将Java代码映射到Kubernetes容器并进行本地编译。本机编译对于无服务器计算非常有用,它避免了在容器中运行JVM的开销,让我们直接执行无服务器代码。调试原生编译的代码不是一件容易的事。由于大量的代码优化,以及原生与非原生编译代码中使用的库的差异,它可能与原始的Java源代码有很大的不同。在某些情况下,为了更好地理解程序,有必要同时查看源代码和汇编代码,这使调试工作更加复杂。
本地可执行文件可以用GDB进行调试,GDB是一个C/C++调试器,与emacs这样的工具结合使用,可以逐步浏览源代码。然而,这些工具对于一个Java开发者来说可能并不熟悉。最近,VSCode和IntelliJ的扩展已经被开发出来以缓解这个问题。这两个工具都是针对它们所扩展的IDE的,并且由于目前Java本地编译器的限制,需要在Linux环境下使用。
NativeJDB是一个开源的工具,支持对本地编译的Java代码进行远程调试。原则上,这允许从任何支持Java平台调试器架构(JPDA)的IDE中进行调试,如IntelliJ、Eclipse或VSCode。远程附加意味着用户可以在任何操作系统上启动调试会话,而NativeJDB进程本身在Linux容器中运行。我们的挑战是在JPDA和GDB之间架起一座桥梁,这两个堆栈通常是不互相交流的。为了实现这一目标,我们基本上教GDB使用Java Debug Wire Protocol(JDWP),该协议被IDE用来与Java调试器进行通信。
当编写Quarkus代码时,开发者有可能在原生编译之前用普通的Java调试器发现错误。当观察到本地可执行文件的行为与程序在JVM上执行时不同时,NativeJDB就很有用。它可以用来探索优化和库中的差异,以解释行为上的反常现象。NativeJDB不是Quarkus特有的,可以用来调试任何本地编译的Java代码。
架构和实现
NativeJDB是一个包裹GDB的Java进程,GDB本身包裹着本地可执行文件,它作为一个服务器,理解JDWP协议。它类似于用于控制和调试运行中的Java进程的JDWP代理。在这种情况下,用户可以附加到这样一个进程,并可以开始调试它。NativeJDB的使用方法类似:一旦它被启动,用户就会使用IDE的远程调试配置附加到它身上。
然后IDE使用JDWP与NativeJDB进行通信。在最初的握手和寒暄(如能力和可用的类集)之后,协议允许用户操作IDE的接口,这将触发适当的JDWP数据包被发送到NativeJDB。这些数据包由NativeJDB解释并翻译成GDB-MI命令。我们使用MI接口与GDB通信,因为它是在GDB之上建立工具的推荐接口。然后,GDB对这些命令做出响应,这些响应被翻译成JDWP数据包并送回IDE。
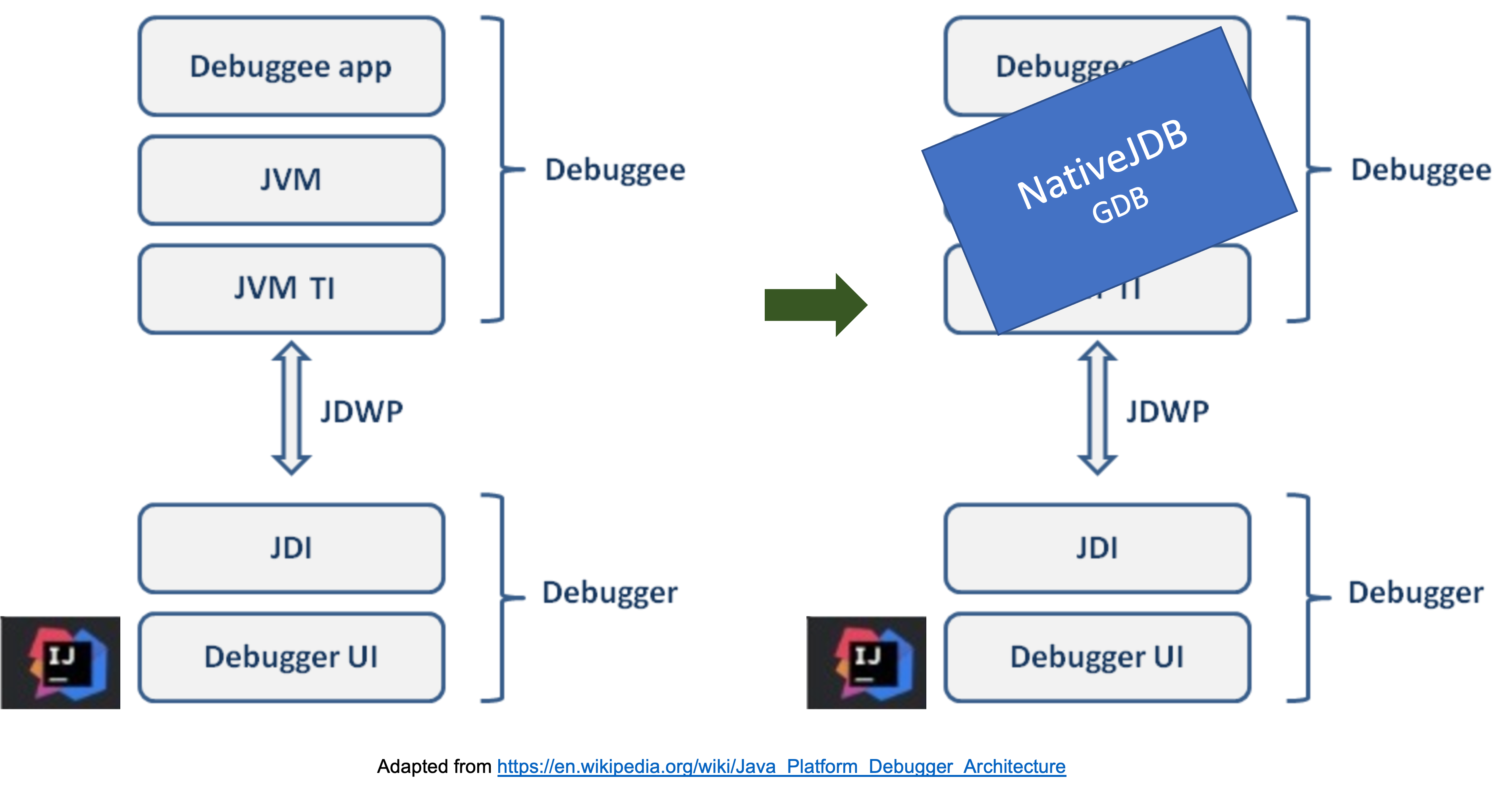
IDE和GDB之间的通信可以是同步和异步的,包括错误信息。在某些情况下,来自IDE的一个命令可以导致同步和异步的响应。例如,设置一个断点有一个同步响应,但相应的断点-命中是一个异步事件,会从NativeJDB发送到IDE。原则上,NativeJDB可以用于任何有JDWP实现的IDE,但它主要是在IntelliJ中测试和工作。它也不需要对现有的IDE进行任何改变或扩展,并且可以与社区以及商业版的IntelliJ一起使用。
今天,GraalVM和qbicc中的本地镜像构建器在Linux环境下产生调试信息,其源码映射到原始Java源代码(对其他平台的支持也正在进行中)。NativeJDB的架构允许用户在任何操作系统上运行的IDE中启动调试会话,并附加到Linux容器中运行的NativeJDB进程。所以它不需要从Linux开始。它也可以和社区以及商业版本的GraalVM一起使用。
NativeJDB由几个不同的组件组成。我们使用Docker来构建一个本地可执行文件,并为debuggee Java应用程序产生调试信息。我们的Docker设置使用Ubuntu O/S。NativeJDB的前端是一组解析和构建JDI数据结构的类。它的后端解析并构建与GDB通信对应的数据结构。
NativeJDB一直在使用一个脚手架式JVM来帮助它获得某些静态信息并加快开发速度。所以目前NativeJDB除了运行本地可执行文件外,也将程序作为一个Java进程来启动。它依附于该进程并暂停该进程,以获取程序的一般静态信息。在未来,我们会去掉这个脚手架,取而代之的是来自GDB的信息,尽管它在快速原型设计中非常有用。
行动中的NativeJDB!
要开始使用,你需要以下的仓库,并按照每个仓库的说明进行操作。
请看下面的视频,看看NativeJDB的运行情况。
还有这个视频展示了NativeJDB在GettingStarted Quarkus应用程序上的运行。
特点
-
能够在编辑器中显示Java源码,并通过代码进行操作
-
与IntelliJ和Java11一起工作
-
与GraalVM的本地编译图像一起工作
-
与Qbicc的本地编译图像一起工作(正在进行中)
-
使用IDE的Debug Console本身进行调试的功能。
-
暂停/恢复
-
设置断点(插入/启用)
-
清除断点(删除/禁用)
-
跨越/进入/返回步骤(正在进行)。
-
在IDE调试器窗格中的堆栈框架信息
-
变量(本地+静态)值(工作正在进行中)
-
查看堆栈框架内的汇编代码(正在进行中)
-
多线程和线程信息
-
NativeJDB不支持热代码替换。另外,目前运行时间很短的程序需要一个Thread.sleep()。这是由于NativeJDB今天使用了一个脚手架虚拟机,需要一点时间来连接和暂停它。当我们在未来摆脱了脚手架后,这个问题就会消失。还有一个已知的问题是,在某些情况下,断点在循环中只起作用一次(与这个gralvm问题有关),而步骤操作有时反而会继续。
总结
通过这篇博客,我们展示了一个名为NativeJDB的新的调试工具,它允许用户远程附加和调试一个原生编译的Java代码。它在现代IDE中的Java调试框架和GDB之间提供了一座桥梁。它不需要对现有的IDE进行扩展,并且允许用户在任何O/S上开始他们的调试会话。
在未来,我们可以探索让NativeJDB与除IntelliJ之外的其他IDE一起工作,这在原则上应该是可行的。
NativeJDB目前是一个工作原型,我们期待着反馈、建议和贡献
参考文献
Quarkus是开放的。这个项目的所有依赖性都在Apache软件许可2.0或兼容许可下提供。
这个网站是用Jekyll建立的,托管在GitHub Pages上,是完全开源的。如果你想让它变得更好,请分叉该网站并向我们展示你的成果。
导航
关注我们
获取帮助
语言
Quarkus是由社区项目组成的
