

异常检测是为了找到偏离规范的数据点。换句话说,这些是不遵循预期模式的点。离群值和异常值是用来描述异常数据的术语。异常检测在各种领域都很重要,因为它能提供有价值的、可操作的见解。例如,核磁共振成像扫描中的异常可能表明大脑中的肿瘤区域,而制造厂传感器的异常读数可能表明一个损坏的部件。
通过本教程后,你将能够。
- 定义和理解异常检测。
- 实施异常检测算法来分析和解释结果。
- 看到任何数据中可能导致异常行为的隐藏模式。
什么是异常点检测?
离群点只是一个数据点,它与特定数据集中的其他数据点有很大的偏差。同样,异常检测是帮助我们识别数据离群点的过程,或与其他大部分数据点有很大偏差的点。
当涉及到大型数据集时,可能包括非常复杂的模式,不能通过简单地查看数据来检测。因此,为了实现关键的机器学习应用,对异常检测的研究具有重要意义。
异常现象的类型
在数据科学领域,我们有三种不同的方式来对异常情况进行分类。正确理解它们可能会对你处理异常的方式产生很大的影响。
- 点或全局异常:对 应于与其他数据点有明显差异的数据点,全局异常是已知的最常见的异常形式。通常情况下,全局异常是在离任何数据分布的平均值或中位数很远的地方发现的。
- 背景性或条件性异常:这 些异常点的数值与同一背景下的其他数据点的数值有很大的不同。一个数据集中的异常点可能不是另一个数据集中的异常点。
- 集体异常点:因为具有相同的异常点特征而被紧紧聚在一起的异常点对象被称为集体异常点。例如,你的服务器不是每天都受到网络攻击,因此,它会被认为是一个异常值。
虽然有许多用于异常检测的技术,但让我们实现几个技术,以了解它们如何用于各种用例。
隔离森林
就像随机森林一样,隔离森林是使用决策树建立的。它们是以无监督的方式实现的,因为没有预先定义的标签。隔离森林的设计理念是,异常点是数据集中 "少数且独特的 "数据点。
回顾一下,决策树是使用信息标准(如基尼指数或熵)建立的。明显不同的群体在树的根部被分开,而在树枝的深处,更细微的区别被识别。基于随机挑选的特征,隔离森林以树状结构处理随机分样的数据。那些深入到树中的样本,需要更多的切割来分离它们,它们是异常的概率非常小。同样地,在树的较短分支上发现的样本更有可能是异常的,因为树发现将它们与其他数据区分开来更简单。
在这次会议上,我们将在Python中实现隔离森林,了解它是如何检测数据集中的异常情况的。我们都知道不可思议的scikit-learn API,它提供了各种API以方便实现。因此,我们将使用它来应用隔离森林,以证明它在异常检测方面的有效性。
首先,让我们加载必要的库和包。
from sklearn.datasets import make_blobs
from numpy import quantile, random, where
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
数据准备
我们将使用make_blob() 函数来创建一个带有随机数据点的数据集。
random.seed(3)
X, _ = make_blobs(n_samples=300, centers=1, cluster_std=.3, center_box=(20, 5))
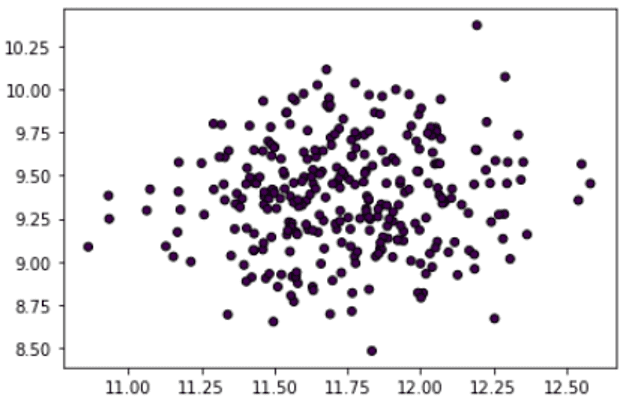
让我们来看看数据集图,看看数据点在样本空间中的随机分离。
plt.scatter(X[:, 0], X[:, 1], marker="o", c=_, s=25, edgecolor="k")
定义和拟合用于预测的隔离森林模型
如前所述,我们将使用scikit-learn API中的IsolationForest 类来定义我们的模型。在类的参数中,我们将设置估计器的数量和污染值。然后,我们将使用fit_predict() 函数,通过拟合模型来获得数据集的预测结果。
IF = IsolationForest(n_estimators=100, contamination=.03)
predictions = IF.fit_predict(X)
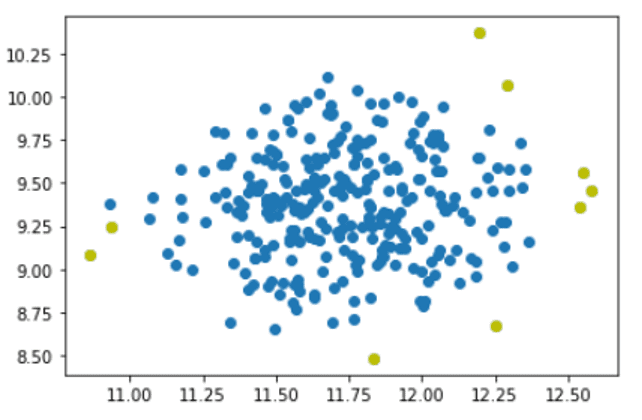
现在,让我们把负值作为离群值提取出来,用颜色突出显示异常值的结果。
outlier_index = where(predictions==-1)
values = X[outlier_index]
plt.scatter(X[:,0], X[:,1])
plt.scatter(values[:,0], values[:,1], color='y')
plt.show()
把所有这些放在一起,下面是完整的代码。
from sklearn.datasets import make_blobs
from numpy import quantile, random, where
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
random.seed(3)
X, _ = make_blobs(n_samples=300, centers=1, cluster_std=.3, center_box=(20, 5))
plt.scatter(X[:, 0], X[:, 1], marker="o", c=_, s=25, edgecolor="k")
IF = IsolationForest(n_estimators=100, contamination=.03)
predictions = IF.fit_predict(X)
outlier_index = where(predictions==-1)
values = X[outlier_index]
plt.scatter(X[:,0], X[:,1])
plt.scatter(values[:,0], values[:,1], color='y')
plt.show()
核心密度估计
如果我们认为一个数据集的常态应该符合某种概率分布,那么异常值就是那些我们应该很少看到的,或者是非常低的概率。核心密度估计是一种估计样本空间中随机的数据点的概率密度函数的技术。通过密度函数,我们可以检测数据集中的异常情况。
为了实施,我们将通过创建一个均匀分布来准备数据,然后应用scikit-learn库中的KernelDensity 类来检测离群值。
为了开始,我们将加载必要的库和包。
from sklearn.neighbors import KernelDensity
from numpy import where, random, array, quantile
from sklearn.preprocessing import scale
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
准备和绘制数据
让我们写一个简单的函数来准备数据集。一个随机生成的数据将被用作目标数据集。
random.seed(135)
def prepData(N):
X = []
for i in range(n):
A = i/1000 + random.uniform(-4, 3)
R = random.uniform(-5, 10)
if(R >= 8.6):
R = R + 10
elif(R < (-4.6)):
R = R +(-9)
X.append([A + R])
return array(X)
n = 500
X = prepData(n)
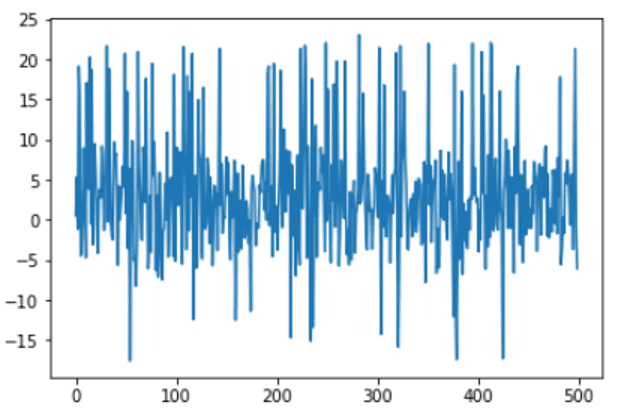
让我们用可视化的绘图来检查数据集。
x_ax = range(n)
plt.plot(x_ax, X)
plt.show()
准备并拟合用于预测的核密度函数
我们将使用scikit-learn API来准备和拟合模型。然后使用score_sample() 函数来获得数据集中样本的分数。接下来,我们将使用quantile() 函数来获得阈值。
kern_dens = KernelDensity()
kern_dens.fit(X)
scores = kern_dens.score_samples(X)
threshold = quantile(scores, .02)
print(threshold)
-5.676136054971186
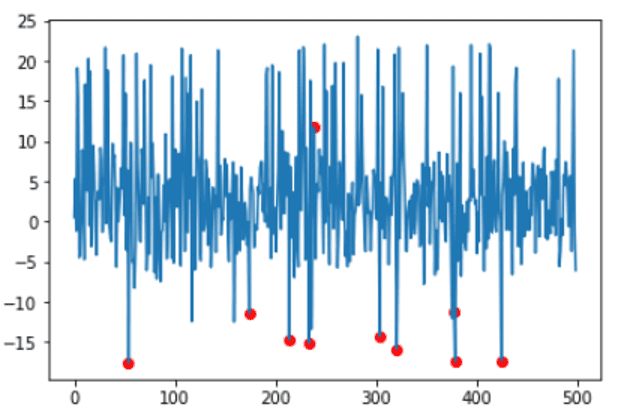
分数等于或低于获得的阈值的样本将被检测出来,然后用颜色突出显示异常情况。
idx = where(scores <= threshold)
values = X[idx]
plt.plot(x_ax, X)
plt.scatter(idx,values, color='r')
plt.show()
将所有这些放在一起,以下是完整的代码。
from sklearn.neighbors import KernelDensity
from numpy import where, random, array, quantile
from sklearn.preprocessing import scale
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
random.seed(135)
def prepData(N):
X = []
for i in range(n):
A = i/1000 + random.uniform(-4, 3)
R = random.uniform(-5, 10)
if(R >= 8.6):
R = R + 10
elif(R < (-4.6)):
R = R +(-9)
X.append([A + R])
return array(X)
n = 500
X = prepData(n)
x_ax = range(n)
plt.plot(x_ax, X)
plt.show()
kern_dens = KernelDensity()
kern_dens.fit(X)
scores = kern_dens.score_samples(X)
threshold = quantile(scores, .02)
print(threshold)
idx = where(scores <= threshold)
values = X[idx]
plt.plot(x_ax, X)
plt.scatter(idx,values, color='r')
plt.show()
总结
在本教程中,你发现了如何检测数据集中的异常情况。
具体来说,你学到了。
- 如何定义异常点及其不同类型
- 什么是隔离森林以及如何将其用于异常检测
- 什么是内核密度估计以及如何将其用于异常检测
