

GPU已经成为科学计算堆栈的重要组成部分,随着GPU技术的进步,以及在云端或内部访问GPU的便利性,PyData社区花时间和精力让PyData库的用户能够使用GPU是最有利的。PyData生态系统中的典型用户对SciPy、scikit-learn和scikit-image等库的API相当熟悉,目前这些库在很大程度上仅限于CPU上的单线程操作(也有例外,比如线性代数功能和scikit-learn功能,这些功能在引擎盖下使用OpenMP)。在这篇博文中,我将讨论我们如何将PyData生态系统中的基本库和CuPy一起使用Python阵列API标准,以使这些库的用户能够使用GPU。随着Python数据API标准联盟对该标准的引入及其在NEP 47中的采用机制,现在可以编写在NumPy和其他采用阵列API标准的数组/张量库之间可移植的代码。我们还将讨论实际实现这种可移植性的工作流程和挑战。
动机和目标
这个练习的动机来自于这样一个事实:在SciPy和scikits中拥有GPU特定的代码将是过于专业化的,而且非常难以维护。这个演示的目标是:(a)在一个真实世界的代码例子中,用SciPy、scikit-learn和scikit-image一起展示在GPU上工作的东西,以及(b)证明有明显的性能优势。我们将使用CuPy作为这个演示的GPU库。由于CuPy支持NVIDIA GPU以及AMD的ROCm GPU平台,这个演示将在这些GPU上运行。
最终目标是让SciPy、scikit-learn和scikit-image接受任何类型的数组,因此它们可以与CuPy、PyTorch、JAX、Dask和其他库一起工作。这项工作是AMD赞助的一个更大的项目的一部分,该项目旨在为SciPy、scikit-learn、scikit-image及其他项目提供对GPU和分布式支持的扩展性。
阵列API标准的入门读物
截至目前,NumPy每月下载量超过1亿次(来自conda和PyPI),是数组计算的基本选择库。在过去的十年中,发展了大量的数组库,这些数组库或多或少都源于NumPy的API,而它的API并不是很好定义。这是由于NumPy是一个仅适用于CPU的库,而今天这些依赖性库是为各种奇特的硬件建立的。因此,这些库的API出现了很大的分歧,以至于要写出能与这些库中的多个(或全部)库一起工作的代码相当困难。阵列API标准旨在解决这个问题,它为构建和使用阵列的最常见方式指定了一个API。在写这篇文章的时候,NumPy(>=1.22.0)和CuPy(>=10.0.0)已经采用了Array API标准。
关于使用数组API标准的注意事项
阵列API标准的定义及其用法可能会随着时间的推移而发生变化。这篇博文只是为了说明我们如何使用它来使SciPy和scikits等库的用户能够使用GPU,以及由此带来的性能优势。它不一定定义任何围绕采用该标准的最佳实践。这种采用的最佳实践仍然是一项正在进行的工作,并将在未来一年中不断发展。
例子:通过光谱聚类进行图像分割
我们选择了一个例子来证明采用Array API标准使GPU在SciPy和scikits中可以使用,这个例子取自scikit-learn的文档:将一张希腊硬币的图片分割成若干区域。这个例子在图像的体素与体素之间的差异所创建的图形上使用光谱聚类,将该图像分成多个部分同质的区域(或群组)。从本质上讲,频谱聚类是为了寻找图中的群组,即找到连接最多的子图,从而确定群组。另外,它也可以被描述为寻找具有最大数量的集群内连接和最小数量的集群间连接的子图。

来自庞贝的希腊钱币("英国伦敦大英博物馆")。
来源:www.brooklynmuseum.org/opencollection/archives/image/51611
我们在这个演示中使用的数据集是来自庞贝的希腊钱币(来自skimage.data.coins 模块)。这是一个在灰色背景下勾勒出几个硬币的图像数据。
我们将硬币的数据转换为一个图形对象,然后对其应用光谱聚类来分割硬币。
使代码在GPU上运行的过程
get_namespace - 获得阵列API模块
NEP 47,"采用阵列API标准",概述了为阵列提供者和消费者库采用阵列API标准的基本工作流程。现在我们将详细描述我们如何在SciPy、scikit-learn和scikit-image的分叉中实现这一过程。
阵列API定义了一个名为__array_namespace__ 的方法,该方法返回阵列API模块,其中包含所有可访问的阵列API函数。它有几个关键的好处。
- 让数组消费库能够检查进入的数组是否支持该标准。
- 访问所有与数组对象一起工作的函数,而不需要明确导入Python模块。
NEP 47建议定义一个名为get_namespace 的实用函数来检查这种属性。
一个可能实现get_namespace 函数的例子被定义如下。
import numpy as np
def get_namespace(*xs):
# `xs` contains one or more arrays, or possibly Python
# scalars (accepting those is a matter of taste, but
# doesn't seem unreasonable).
namespaces = {
x.__array_namespace__()
if hasattr(x, '__array_namespace__') else None
for x in xs if not isinstance(x, (bool, int, float, complex))
}
if not namespaces:
# one could special-case np.ndarray above or use np.asarray here
# if older numpy versions need to be supported.
raise ValueError("Unrecognized array input")
if len(namespaces) != 1:
raise ValueError(f"Multiple namespaces for array "
"inputs: {namespaces}")
xp, = namespaces
if xp is None:
# Use numpy as default
return np, False
return xp, True
工作流程--用于使用get_namespace
现在让我们通过一个例子来看看这在实践中是如何运作的。考虑下面这个来自SciPy的函数。
def getdata(obj, dtype=None, copy=False):
"""
This is a wrapper of `np.array(obj, dtype=dtype, copy=copy)`
that will generate a warning if the result is an object array.
"""
data = np.array(obj, dtype=dtype, copy=copy)
# Defer to getdtype for checking that the dtype is OK.
# This is called for the validation only; we don't need
# the return value.
getdtype(data.dtype)
这个函数取自scipy/sparse/_sputils.py 。我们可以看到,这个函数在给定的数组对象上明确地调用了np.array 。obj,而没有意识到obj 的类型。这个实现显然不是通用的,无法支持NumPy以外的任何数组库。现在我们将应用Array API的get_namespace 魔法,通过在上面的代码中添加几行来使其通用。
def getdata(obj, dtype=None, copy=None):
"""
This is a wrapper of `np.array(obj, dtype=dtype, copy=copy)`
that will generate a warning if the result is an object array.
"""
xp, _ = get_namespace(obj)
data = xp.asarray(obj, dtype=dtype, copy=copy)
# Defer to getdtype for checking that the dtype is OK.
# This is called for the validation only; we don't need
# the return value.
getdtype(data.dtype)
现在你可以看到,get_namespace 为给定的对象找到与Array API标准兼容的命名空间,并对其调用.asarray ,而不是np.array 。因此,它对任何支持该标准的数组提供者库都是通用的。
 使用Array API标准编写可与多个库协同工作的代码的工作流程
使用Array API标准编写可与多个库协同工作的代码的工作流程
将其应用于我们的演示例子
现在让我们来看看我们的演示例子的代码(希腊钱币图片的区域分割),以了解如何使它在GPU上运行。
# Author: Gael Varoquaux <gael.varoquaux@normalesup.org>, Brian Cheung
# License: BSD 3 clause
import time
import numpy as np
from scipy.ndimage.filters import gaussian_filter
import matplotlib.pyplot as plt
import skimage
from skimage.data import coins
from skimage.transform import rescale
from sklearn.feature_extraction import image
from sklearn.cluster import spectral_clustering
from sklearn.utils.fixes import parse_version
# these were introduced in skimage-0.14
if parse_version(skimage.__version__) >= parse_version("0.14"):
rescale_params = {"anti_aliasing": False, "multichannel": False}
else:
rescale_params = {}
# 1. load the coins as a numpy array
orig_coins = coins()
# 2. Resize it to 20% of the original size to speed up the processing
# Applying a Gaussian filter for smoothing prior to down-scaling
# reduces aliasing artifacts.
smoothened_coins = gaussian_filter(orig_coins, sigma=2)
rescaled_coins = rescale(smoothened_coins, 0.2, mode="reflect", **rescale_params)
# 3. Convert the image into a graph with the value of the gradient on the
# edges.
graph = image.img_to_graph(rescaled_coins)
# Take a decreasing function of the gradient: an exponential
# The smaller beta is, the more independent the segmentation is of the
# actual image. For beta=1, the segmentation is close to a voronoi
beta = 10
eps = 1e-6
graph.data = np.exp(-beta * graph.data / graph.data.std()) + eps
# Apply spectral clustering (this step goes much faster if you have pyamg
# installed)
N_REGIONS = 25
for assign_labels in ("kmeans", "discretize"):
t0 = time.time()
# 4. Apply spectral clustering on the graph (via `discretize` labelling).
labels = spectral_clustering(
graph, n_clusters=N_REGIONS, assign_labels=assign_labels, random_state=42
)
t1 = time.time()
labels = labels.reshape(rescaled_coins.shape)
# 5. Plot the resulting clustering
plt.figure(figsize=(5, 5))
plt.imshow(rescaled_coins, cmap=plt.cm.gray)
for l in range(N_REGIONS):
plt.contour(labels == l, colors=[plt.cm.nipy_spectral(l / float(N_REGIONS))])
plt.xticks(())
plt.yticks(())
title = "Spectral clustering: %s, %.2fs" % (assign_labels, (t1 - t0))
print(title)
plt.title(title)
plt.show()
让我们通过上面的代码来了解我们在这里要实现的目标。
- 我们有一个来自庞贝的希腊钱币数据集(从
skimage.data.coins)。 - 我们将图像的比例调整为20%,以加快处理速度
- 将图像转换为一个图形数据结构
- 在图上应用光谱聚类(通过
discretize标签)。 - 绘制出聚类的结果
现在,为了让它在GPU上运行,我们需要对这个演示代码(以及涉及到的每个库--见下一节)做一些小的修改。我们需要为GPU阵列使用不同的阵列输入。由于NumPy是一个只有CPU的库,我们将使用CuPy,它是一个与NumPy/SciPy兼容的数组库,用于用Python进行GPU加速计算。此外,我们把重新缩放系数做成变量,以便能够作为输入数据大小的函数进行性能基准测试。
对SciPy、scikit-learn、scikit-image和CuPy的改变
由于SciPy、scikit-learn、scikit-image主要是为NumPy设计的,所以我们需要使用Array API标准来根据输入的数据调度到CuPy或NumPy。我们通过改变上述演示中调用的所有函数,使其使用get_namespace ,并替换所有np. (或numpy. )的实例,以正确调度到适当的数组库。这在某些地方很简单,而在其他地方就不那么简单了。我们将在下一节中讨论更具挑战性的情况。
该演示的最终代码可以在这里看到。
SciPy、scikit-learn、scikit-image和CuPy的变化可以在这里看到。
该演示的笔记本可以在这里看到。
挑战与变通
目前,Array API标准指定了NumPy API中很多最常用的函数。这使得用标准中的等价函数替换NumPy函数变得更加容易。但仍有一些粗糙的边缘,这使得这个过程有点困难。这就是我们在这个过程中面临的三个主要问题。
1.编译的代码
SciPy和Scikits中有很多功能不是纯Python。性能关键的部分是使用编译代码扩展编写的。这些部分依赖于NumPy的内部内存表示,这使得它们只能在CPU上运行。这使得使用CuPy执行这些函数时无法使用阵列API标准。还有一个项目,uarray ,用于调度编译后的代码,需要和Array API标准一起使用,以使其完全通用。
例如,请看下面这段代码。
from scipy import sparse
graph = sparse.coo_matrix(<input_arrays>)
这里的sparse.coo_matrix 是scipy.sparse 模块中的一个C++扩展。我们需要将CuPy数组调度到cupyx.scipy.sparse.coo_matrix ,将NumPy数组调度到scipy.sparse.coo_matrix 。这是不可能通过get_namespace 。为了这个演示,我们增加了一个变通方法,直到我们在SciPy中实现对基于uarray 的后端支持。对于CuPy来说,这个变通方法看起来像这样。
xp, _ = get_namespace(<input_arrays>)
if xp.__name__ == 'cupy.array_api':
from cupyx.scipy import sparse as cupy_sparse
coo_matrix = cupy_sparse.coo_matrix
else:
coo_matrix = scipy.sparse.coo_matrix
graph = coo_matrix(<input_arrays>)
请注意,这个变通方法只对NumPy/CuPy数组有效。
2.未实现的函数
我们遇到了一些NumPy的函数,这些函数被我们的希腊硬币演示所使用,但在Array API标准中没有直接的对应。这主要是由于这些函数不够通用,无法在Array API中定义。在这个练习中,我们遇到了一些未实现的函数的例子。
np.atleast_3dnp.stridesnp.realnp.clip
对于其中的一些,解决方案是重新实现一个等价的函数,对于其余的,解决方法是使用库中特定的NumPy/CuPy APIs,然后再转换回符合Array API标准的Array 对象。
3.NumPy API和Array API标准之间的不一致性
尽管该标准已经成功地覆盖了NumPy API,但仍有一些地方存在两者之间的不一致。这可能是函数行为缺失或不同,或者函数或参数名称不匹配(例如,标准中的concat ,而不是np.concatenate )。
下面是一个NumPy和Array API标准之间命名不一致的例子。
In [1]: import numpy as np
In [2]: import numpy.array_api as npx
# Numpy API
In [3]: np.concatenate
Out[3]: <function numpy.concatenate>
# Array API
In [4]: npx.concat
Out[4]: <function numpy.array_api._manipulation_functions.concat...>
这里是一个索引操作的行为不一致的例子。
In [1]: import numpy as np
In [2]: import numpy.array_api as npx
# Works with NumPy API
In [3]: x = np.arange(10)
In [4]: x[np.arange(2)]
Out[4]: array([0, 1])
# Doesn't Works with Array API
In [5]: z = npx.arange(10)
In [6]: z[npx.arange(2)]
-----------------------------------------------------------------
...
IndexError: Non-zero dimensional integer array indices are not allowed in the array API namespace
每个不一致的地方都可以被解决。函数重命名可能需要通过参考Array API标准文档进行一些侦查工作,但通常是很容易的代码修改。行为上的差异有时会更难处理。阵列API标准的目的是提供一套正交但完整的功能--所以如果可以在加速器设备上执行一些阵列操作,那么在标准中通常有一种方法可以访问它。在少数情况下,整数索引是其中之一,扩展标准的工作仍在进行中,我们可能会打开一个功能请求,或在现有的讨论中作出贡献,同时在我们自己的代码中添加一个解决方法。
结果
在处理了上述所有的挑战之后,我们的演示可以使用CuPy数组作为输入。在这一节中,我们将讨论它在GPU上的性能与CPU的对比。
我们在AMD GPU和NVIDIA GPU上运行。下面我们展示了演示代码在CPU和GPU上的运行时间与输入数组大小的函数比较图。图中的X轴是图像尺寸,即沿两个维度重新缩放后的原始图像的尺寸。在这个演示中,重新缩放的因素是。0.1, 0.2, 0.4, 0.6, 0.8和1。
在AMD GPU上。
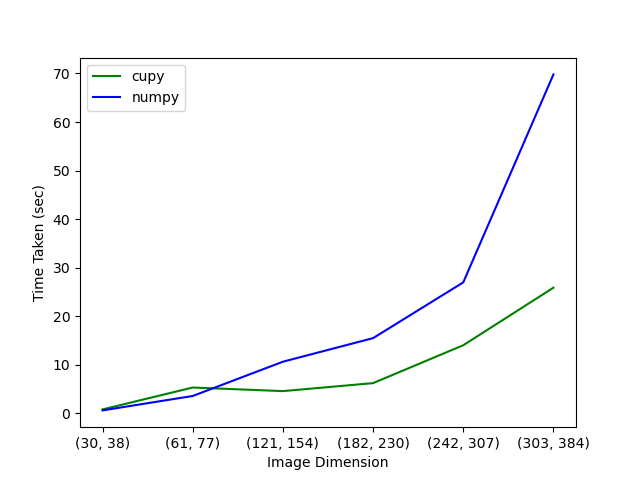
这是在一台配备有32GB内存的AMD Instinct MI50 GPU和64个物理核心的CPU的服务器上运行。
在NVIDIA GPU上。
这是在一个拥有24GB内存的NVIDIA TITAN RTX GPU和一个拥有24个物理核心的CPU上运行的。
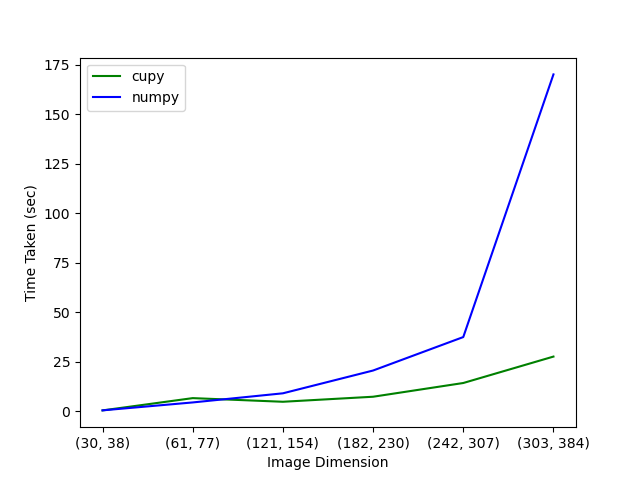
GPU与CPU的对比图显示了你所期望的:对于较大的图像尺寸,使用CuPy(即在GPU上)的计算要比使用NumPy(即在CPU上)的计算快。对于小于61 x 77的图像,在GPU上的计算比在CPU上的计算要慢。这是由于向设备(GPU)移动数据的开销,与实际计算所需的时间相比,这是非常重要的。图像越大,计算时间越长,因此,数据传输变得越不重要,使用GPU的性能改进也越大。
复制这些结果
运行上述分析的代码和说明可以在这个资源库中找到。Quansight-Labs/array-api-gpu-demo。
上述分析需要对以下库进行修改。
cupyscipyscikit-learnscikit-image
这些修改存在于@aktech对上述项目的分叉的array-api-gpu-demo 分支中。
在上述repo中,你可以找到我们为NVIDIA和AMD平台创建Docker镜像的代码。README中还包含了如何从Docker Registry中获取已构建的Docker镜像的说明。一旦你进入了Docker容器,运行演示就像运行一样简单。
python segmentation_performance.py
在装有AMD GPU的机器上运行ROCm容器是这样做的。
docker run -it --device=/dev/kfd --device=/dev/dri --security-opt seccomp=unconfined --group-add video ghcr.io/quansight-labs/array-api-gpu-demo-rocm:latest bash
接下来的步骤
目前,我们只修改了我们需要的功能,以便能够在GPU上运行我们的演示。当然,还有很多功能最终可以被移植到支持Array API标准上。其最终目标是使SciPy、scikit-learn和scikit-image等消耗数组的库与多个数组库完全兼容。
