

[

](garystafford.medium.com/?source=pos…)
6月26日
-
14分钟阅读
[
保存
开发用于查询AWS上的数据湖的Spring Boot应用程序
了解如何开发云原生、RESTful Java服务,使用Amazon Athena的API查询基于AWS的数据湖中的数据。
讲座
AWS提供了一系列完全管理的服务,使构建和管理安全的数据湖变得更快、更容易,包括AWS Lake Formation、AWS Glue和Amazon S3。额外的分析服务,如亚马逊EMR、AWS Glue Studio和亚马逊Redshift,使数据科学家和分析师能够快速、经济地对大量的半结构化和结构化数据进行高性能查询。
不太明显的是,团队如何开发建立在数据湖之上的面向内部和外部客户的分析应用程序。例如,想象一下电子商务平台上的卖家,也就是本篇文章中使用的场景,希望通过分析销售趋势和买家的喜好,对其产品做出更好的营销决策。此外,假设分析所需的数据必须从多个系统和数据源汇总;这是数据湖的理想用例。
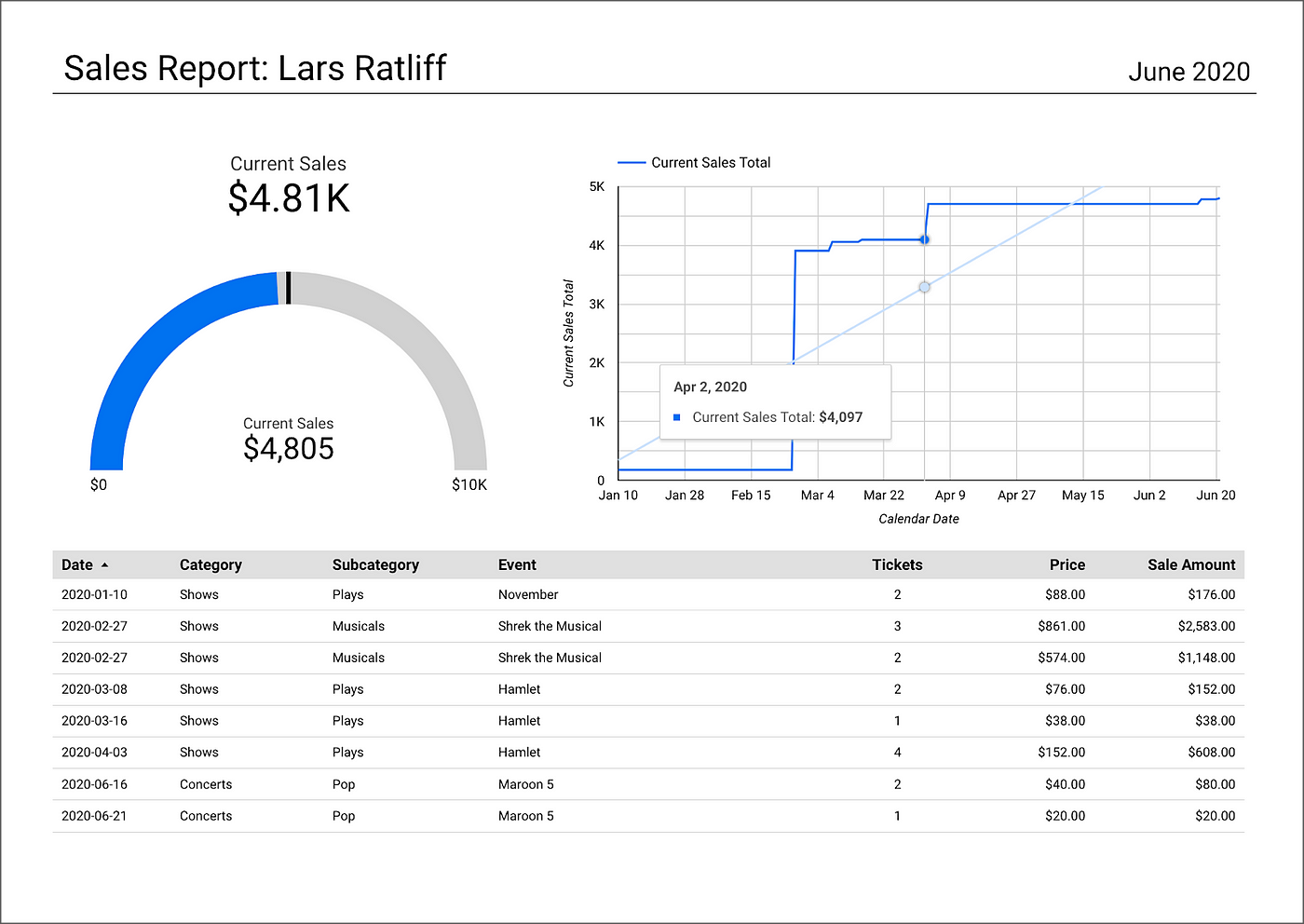
从Spring Boot服务的/salesbyseller端点生成的个性化销售报告的例子
在这篇文章中,我们将探讨一个JavaSpring BootRESTful Web服务的例子,它允许终端用户查询存储在AWS上的数据湖中的数据。该RESTful Web服务将通过使用Amazon Athena的AWS Glue数据目录访问以Apache Parquet形式存储在Amazon S3中的数据。该服务将使用Spring Boot和AWS SDK for Java来提供一个安全的、RESTful应用编程接口(API)。
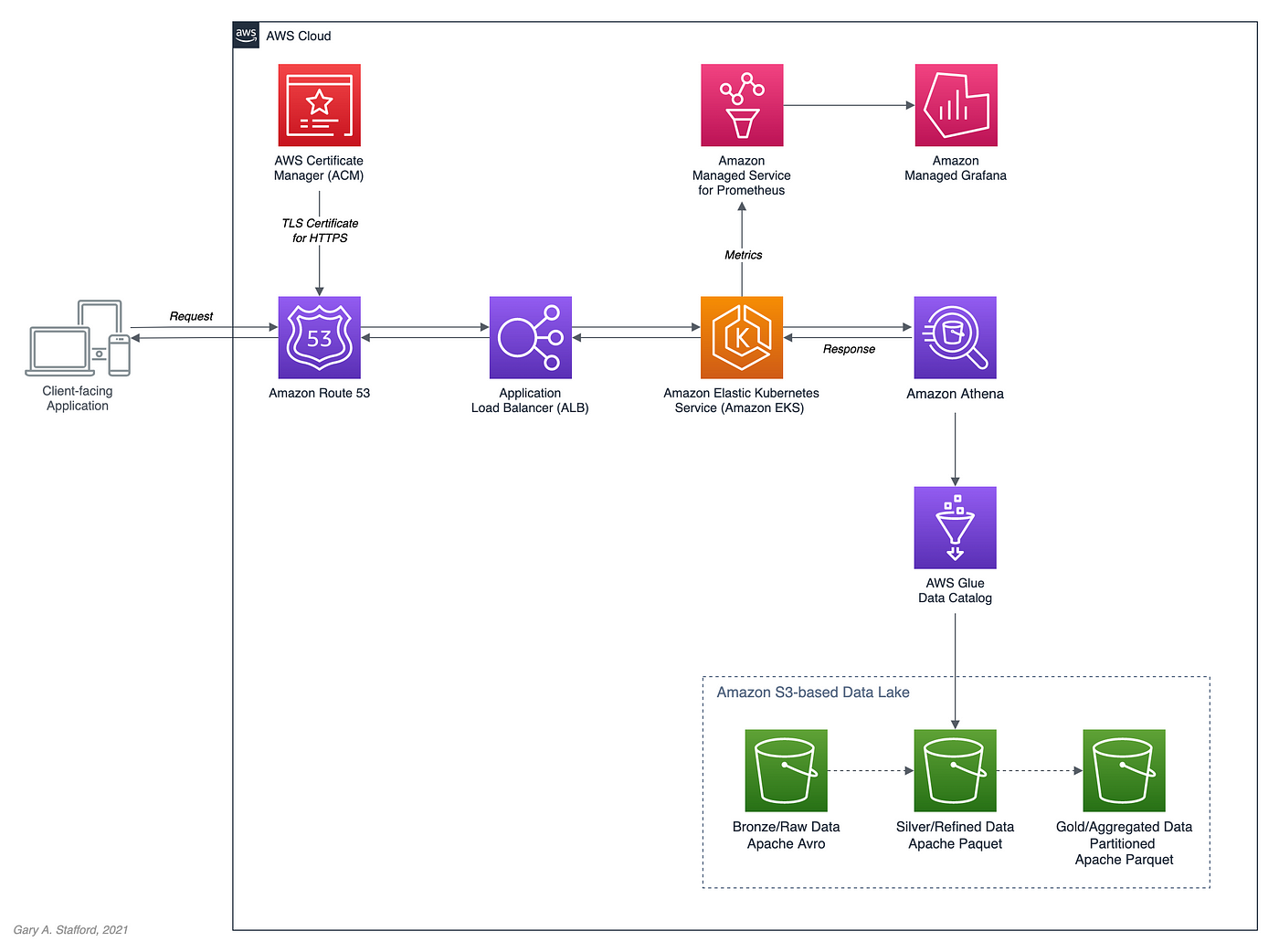
本帖所展示的高层次架构
Amazon Athena是一个基于Presto的无服务器、交互式查询服务,用于查询数据,并使用标准SQL分析Amazon S3中的大数据。使用AWS SDK for Java和Athena API暴露的Athena功能,Spring Boot服务将演示如何访问表、视图、准备好的语句和保存的查询(又称命名查询)。
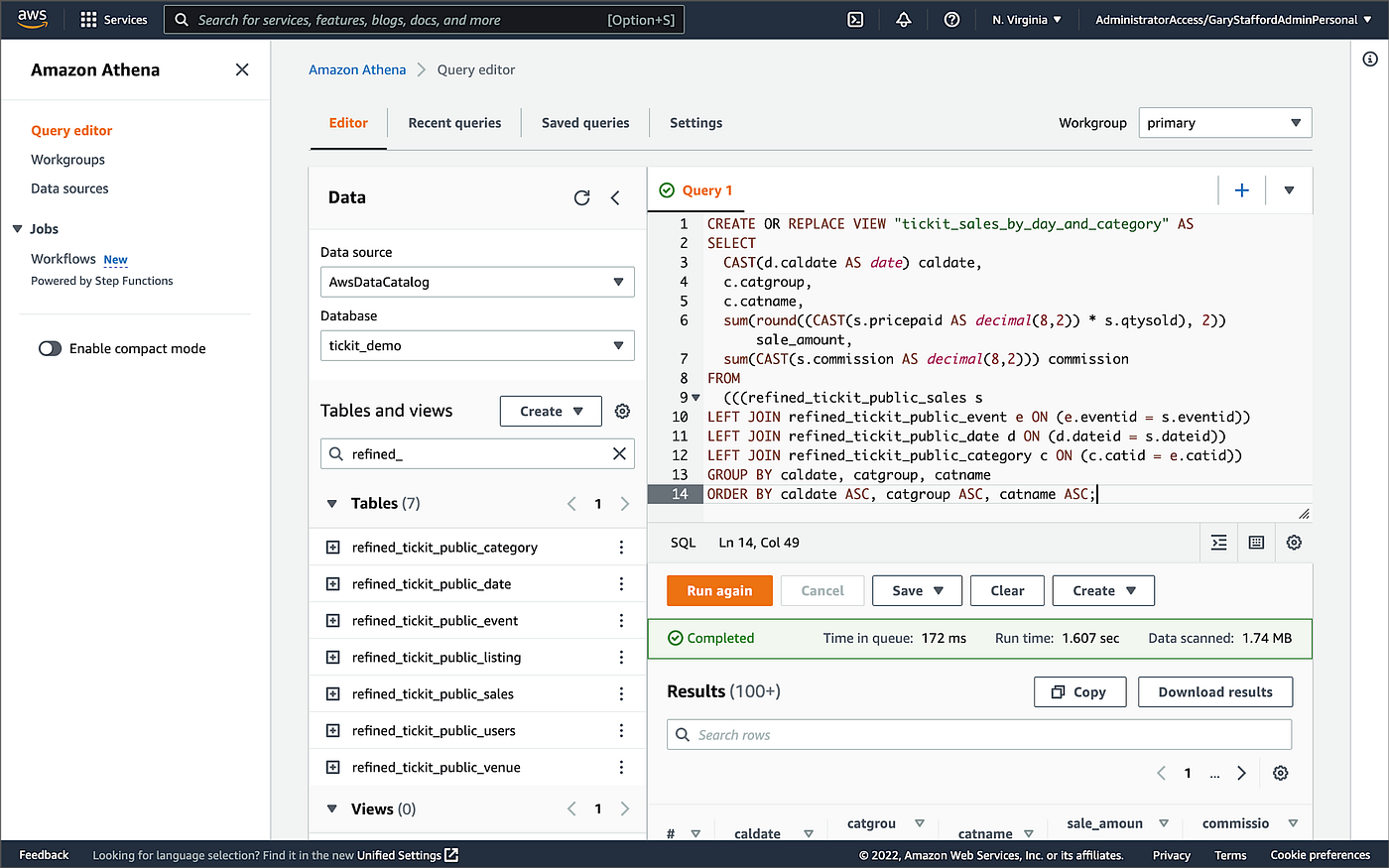
亚马逊Athena查询编辑器
TL;DR
在阅读全文之前,你想探索本帖Spring Boot服务的源代码或将其部署到Kubernetes吗?所有的源代码、Docker和Kubernetes资源都是开源的,可以在GitHub上找到。
git clone --depth 1 -b main \ https://github.com/garystafford/athena-spring-app.git
Spring Boot服务的Docker镜像也可以在Docker Hub上找到。
Docker Hub上提供的Spring Boot服务镜像
数据湖数据源
我们可以使用许多可用的数据源来在AWS上建立一个示范数据湖。这篇文章使用了AWS提供的TICKIT样本数据库,它是为AWS的云数据仓库服务Amazon Redshift设计的。该数据库由七个表组成。之前的两篇文章和相关视频《用Apache Airflow在AWS上构建数据湖》和《在AWS上构建数据湖》详细介绍了本篇文章中使用AWS Glue和可选的Apache Airflow与Amazon MWAA的数据湖设置。
[
用Apache Airflow构建数据湖
使用包括亚马逊托管工作流在内的各种服务组合,在AWS上以编程方式构建一个简单的数据湖...
淘宝网
](garystafford.medium.com/building-a-…)
[
在AWS上构建数据湖
在AWS上使用各种服务组合构建一个简单的数据湖,包括AWS Glue、AWS Glue Studio、Amazon Athena...
邓小平
](garystafford.medium.com/building-a-…)
这两篇文章使用了由Databricks推广的数据湖模式,将数据划分为青铜*(又称原始*)、白银*(又称精炼*)和黄金*(又称聚合*)。数据湖模拟了一个典型的场景,数据来自于多个来源,包括电子商务平台、CRM系统和SaaS供应商,必须对其进行汇总和分析。

上一篇文章中展示的高层次的数据湖架构
使用IntelliJ IDE的Spring项目
虽然不是要求,但我使用了JetBrains IntelliJ IDEA 2022(终极版)来开发和测试该帖的Spring Boot服务。用IntelliJ引导Spring项目很容易。开发人员可以使用与IntelliJ捆绑的Spring Initializr插件快速创建一个Spring项目。
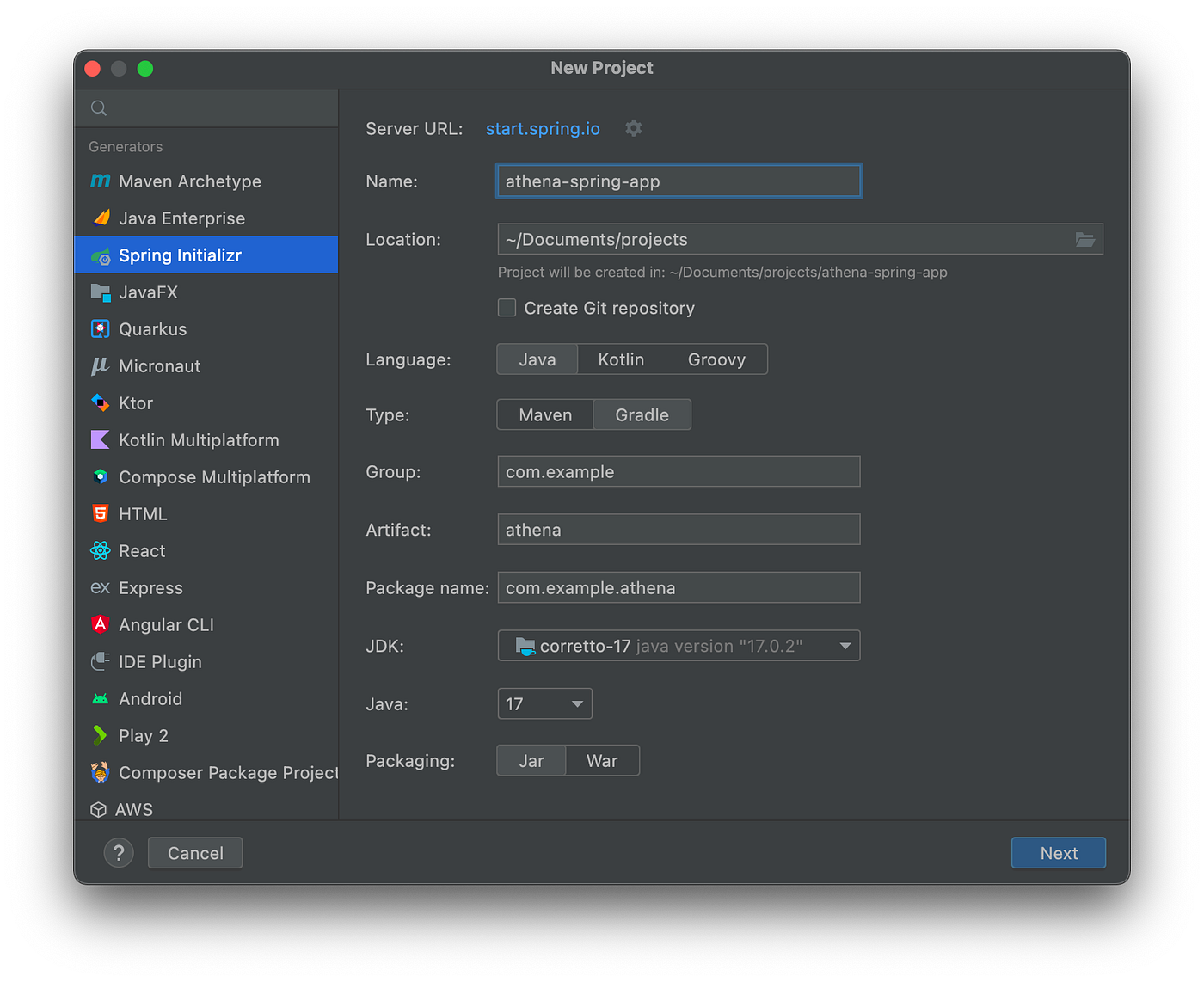
JetBrains IntelliJ IDEA插件对Spring项目的支持
Spring Initializr插件的新项目创建向导是基于start.spring.io的。该插件允许你快速选择你想纳入项目的Spring依赖项。
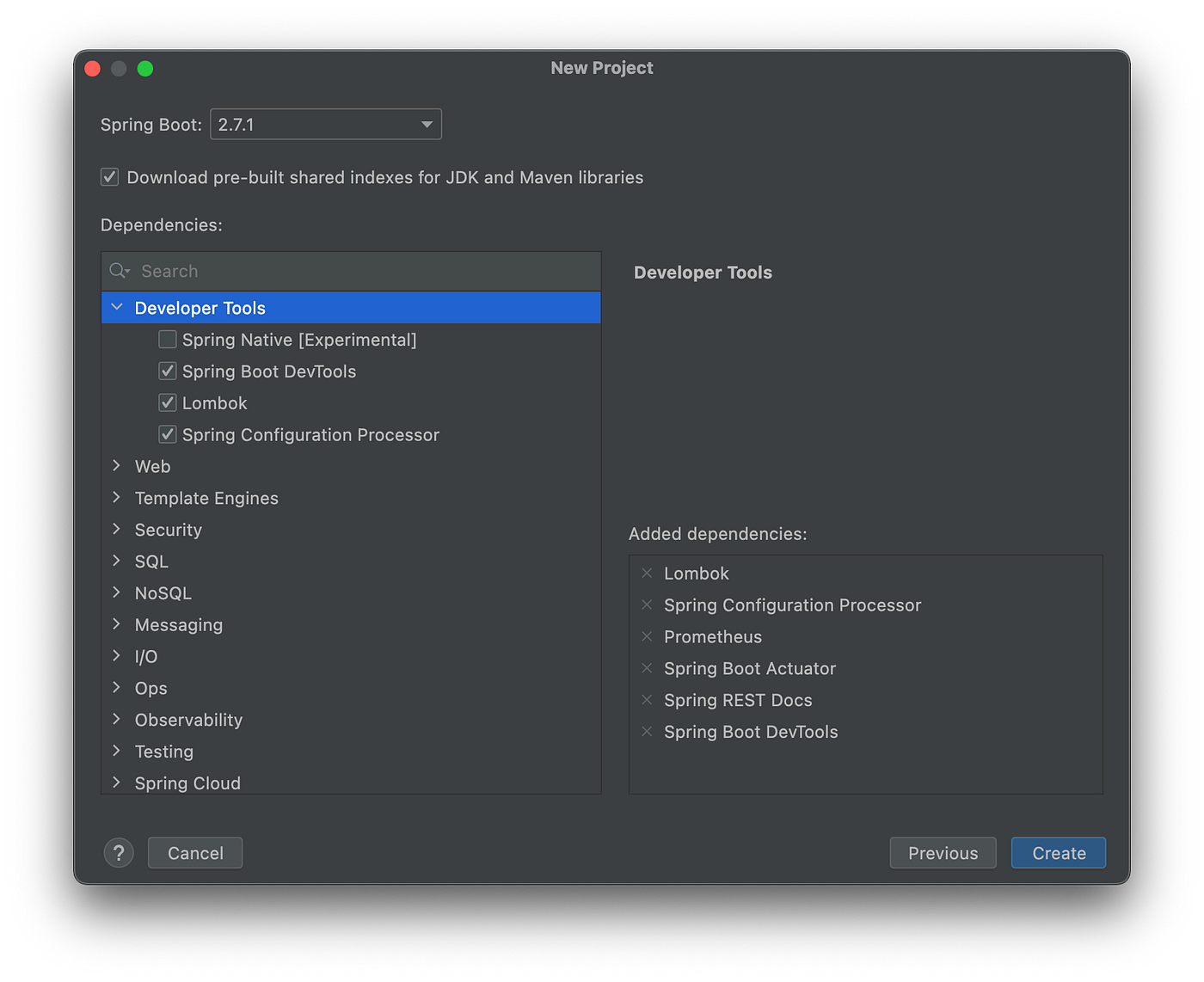
在IntelliJ中向一个新的Spring项目添加依赖项
Visual Studio代码
流行的Visual Studio Code IDE也有几个Spring扩展,包括微软的Spring Initializr Java支持扩展。
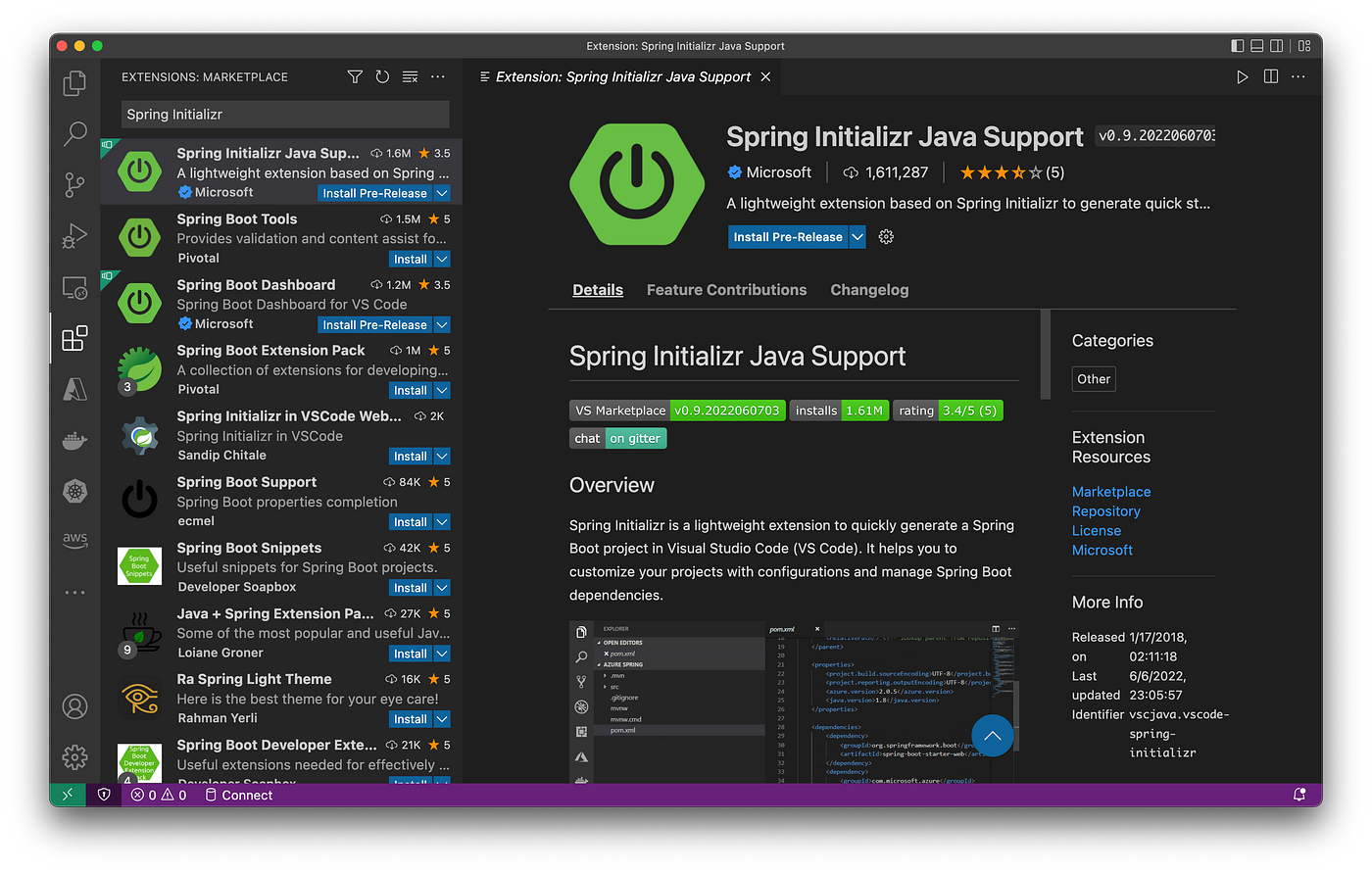
微软为Visual Studio Code提供的Spring Initializr Java支持扩展
Gradle
本帖使用Gradle而不是Maven来开发、测试、构建、打包和部署Spring服务。根据上图所示的新项目设置中选择的包,Spring Initializr插件的新项目创建向导会创建一个build.gradle 文件。额外的包,如Lombak和Rest Assured,是单独添加的。
亚马逊Corretto
Spring boot服务是为Amazon Corretto 17的最新版本开发和编译的。据AWS称,Amazon Corretto是一个无成本、多平台、可生产的开放Java开发工具包(OpenJDK)的发行版。Corretto带有长期支持,包括性能增强和安全修复。Corretto被认证为与Java SE标准兼容,在亚马逊内部被用于许多生产服务。
源代码
Spring Boot RESTful Web服务中的每个API端点都有一个相应的POJO数据模型类、服务接口和服务实现类以及控制器类。此外,还有一些常见的类,如配置、客户端工厂和Athena特定的请求/响应方法。最后,还有视图和准备好的语句的额外类依赖关系。
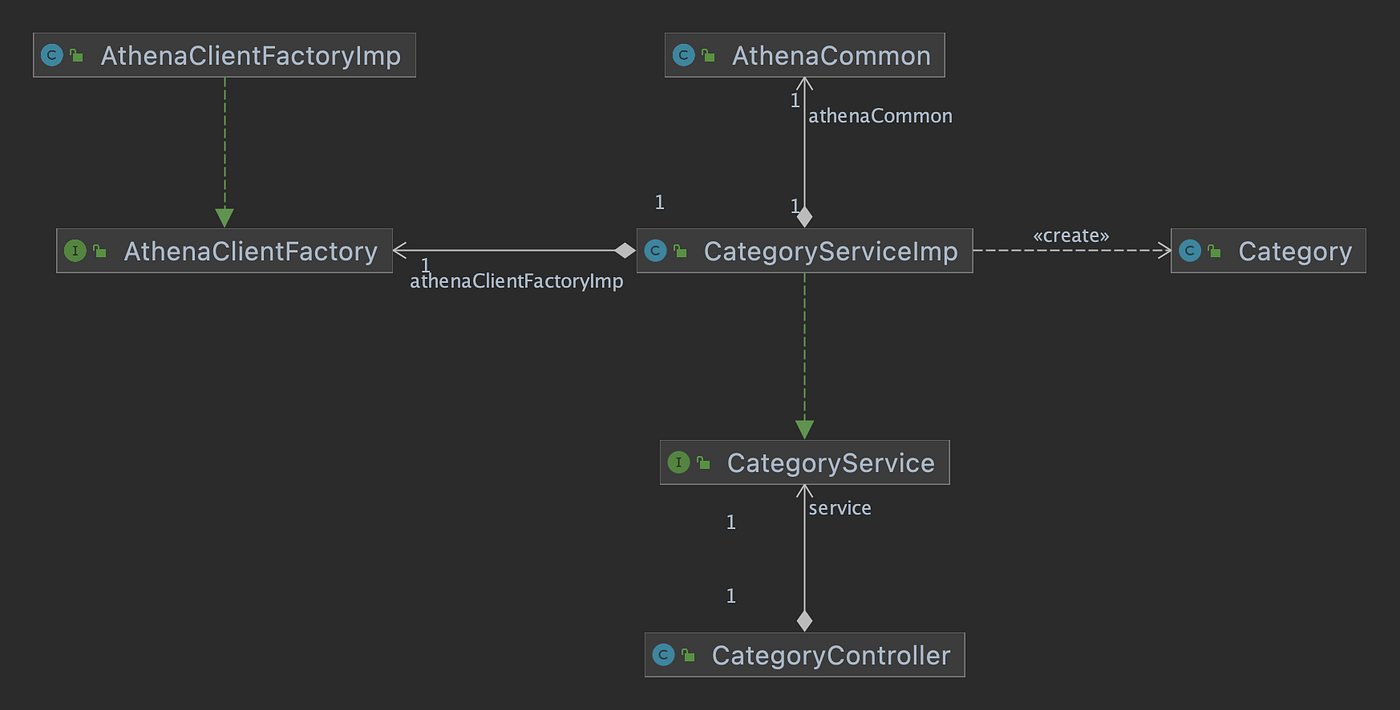
与查询Amazon Athenarefined_tickit_public_category 表有关的Java类关系
项目的源代码是按照包和类的类型来安排逻辑层次的。
基于POJO的数据模型
对于Spring Boot RESTful Web服务中的每个API端点,都有一个相应的Plain Old Java Object(POJO)。根据维基百科,POGO是一个普通的Java对象,不受任何特定限制的约束。POJO类类似于JPA实体,代表存储在关系型数据库中的持久性数据。在这种情况下,POJO使用Lombok的@Data 注解。根据文档,这个注解为所有字段生成了getters,一个有用的toString 方法,以及检查所有非临时字段的hashCode 和equals 实现。它还为所有非最终字段生成了设置器和一个构造器。
Event POJO数据模型
这些POJO中的每一个都直接对应于AWS Glue数据目录中的一个 "银 "表。例如,Event POJO对应于tickit_demo 数据目录数据库中的refined_tickit_public_event 表。该POJO定义了从数据湖中相应的数据目录表读入Spring Boot服务的数据模型。
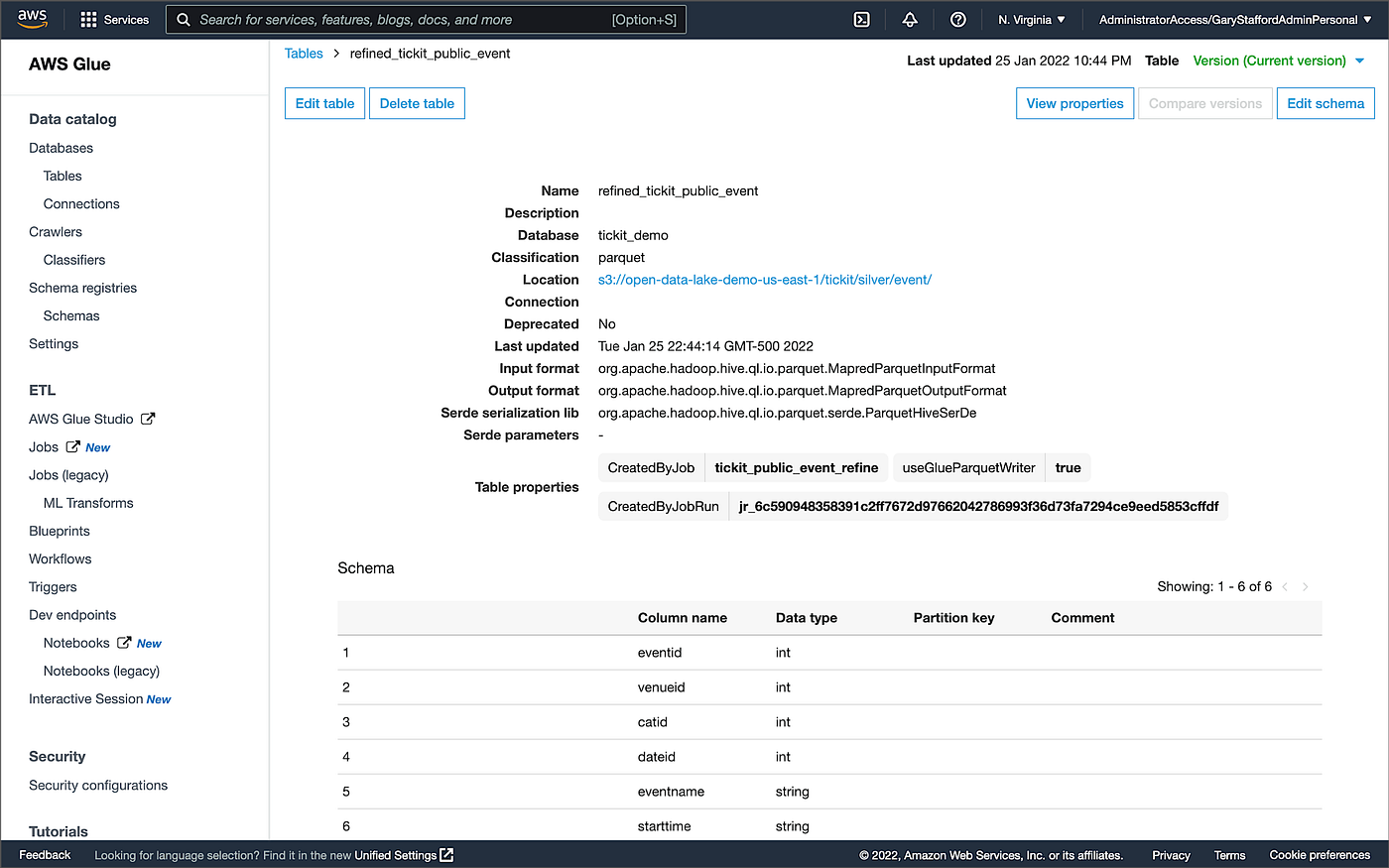
胶水数据目录 refined_tickit_public_event表
胶水数据目录表是Athena查询和存储在Amazon S3对象存储中的基础数据之间的接口。Athena查询以该表为目标,从S3返回底层数据。

Tickit分类数据作为Apache Parquet文件存储在Amazon S3中
服务
通过AWS Glue从数据湖检索数据,使用Athena,由一个服务类处理。对于Spring Boot RESTful Web服务中的每个API端点,都有一个相应的服务接口和实现类。服务实现类使用Spring Framework的@Service 注解。根据文档,它表明注解的类是一个 "服务",最初由领域驱动设计(Evans,2003)定义为 "作为接口提供的操作,在模型中独立存在,没有封装的状态。"对于Spring Boot服务来说,最重要的是,这个注解作为@Component ,允许通过classpath扫描自动检测到实现类。
使用Spring常见的基于构造器的依赖注入(DI)方法*(又称构造器注入*),该服务自动连接了AthenaClientFactory 接口的一个实例。请注意,我们是在自动连接服务接口,而不是服务实现,如果需要的话,我们可以连接不同的实现,例如用于测试。
该服务调用AthenaClientFactory类的createClient() 方法,该方法使用几种可用的认证方法之一返回与Amazon Athena的连接。认证方案将取决于服务的部署地点以及你想如何安全地连接到AWS。一些选项包括环境变量、本地AWS配置文件、EC2实例配置文件,或来自网络身份提供者的令牌。
该服务类将由GetQueryResultsResponse 实例返回的有效载荷转化为有序的集合*(也称为序列*),List<E> ,其中E 代表一个POJO。例如,对于数据湖的refined_tickit_public_event 表,服务会返回一个List<Event> 。这种模式对于表、视图、准备好的语句和命名的查询都会重复。列的数据类型可以在运行中进行转换和格式化,添加新的列,跳过现有的列。
对于控制器类中定义的每个端点,例如:get(),findAll(), 和FindById() ,在服务类中都有一个相应的方法。下面,我们看到SalesByCategoryServiceImp 服务类中findAll() 方法的一个例子。这个方法对应于SalesByCategoryController 控制器类中名称相同的方法。每个服务方法都遵循一个类似的模式,即根据输入参数构建一个动态的Athena SQL查询,该查询通过AthenaClient 服务客户端使用GetQueryResultsRequest 的一个实例传递给Athena。
控制器
最后,Spring Boot RESTful Web服务中的每个API端点都有一个相应的控制器类。控制器类使用Spring Framework的@RestController 注解。根据文档,这个注解是一个方便的注解,它本身是用@Controller 和@ResponseBody 来标注的。携带该注解的类型被视为控制器,其中@RequestMapping 方法默认为@ResponseBody 语义。
控制器类使用基于构造函数的依赖注入(DI)对相应的服务类应用组件进行依赖。就像上面的服务例子一样,我们是自动连接服务接口,而不是服务实现。
控制器负责将有序的POJO集合序列化为JSON,并在初始HTTP请求的HTTP响应正文中返回JSON有效载荷。
查询视图
除了查询AWS Glue数据目录表*(又称Athena表*)外,我们还可以查询视图。根据文档,Amazon Athena中的视图是一个逻辑表,而不是一个物理表。因此,每次在查询中引用视图时,定义视图的查询就会运行。
为了方便起见,每次Spring Boot服务启动时,主AthenaApplication 类会调用View.java 类的CreateView() 方法,以检查视图是否存在,view_tickit_sales_by_day_and_category 。如果视图不存在,它就会被创建,并被所有应用程序的终端用户访问。视图是通过服务的/salesbycategory 端点来查询的。
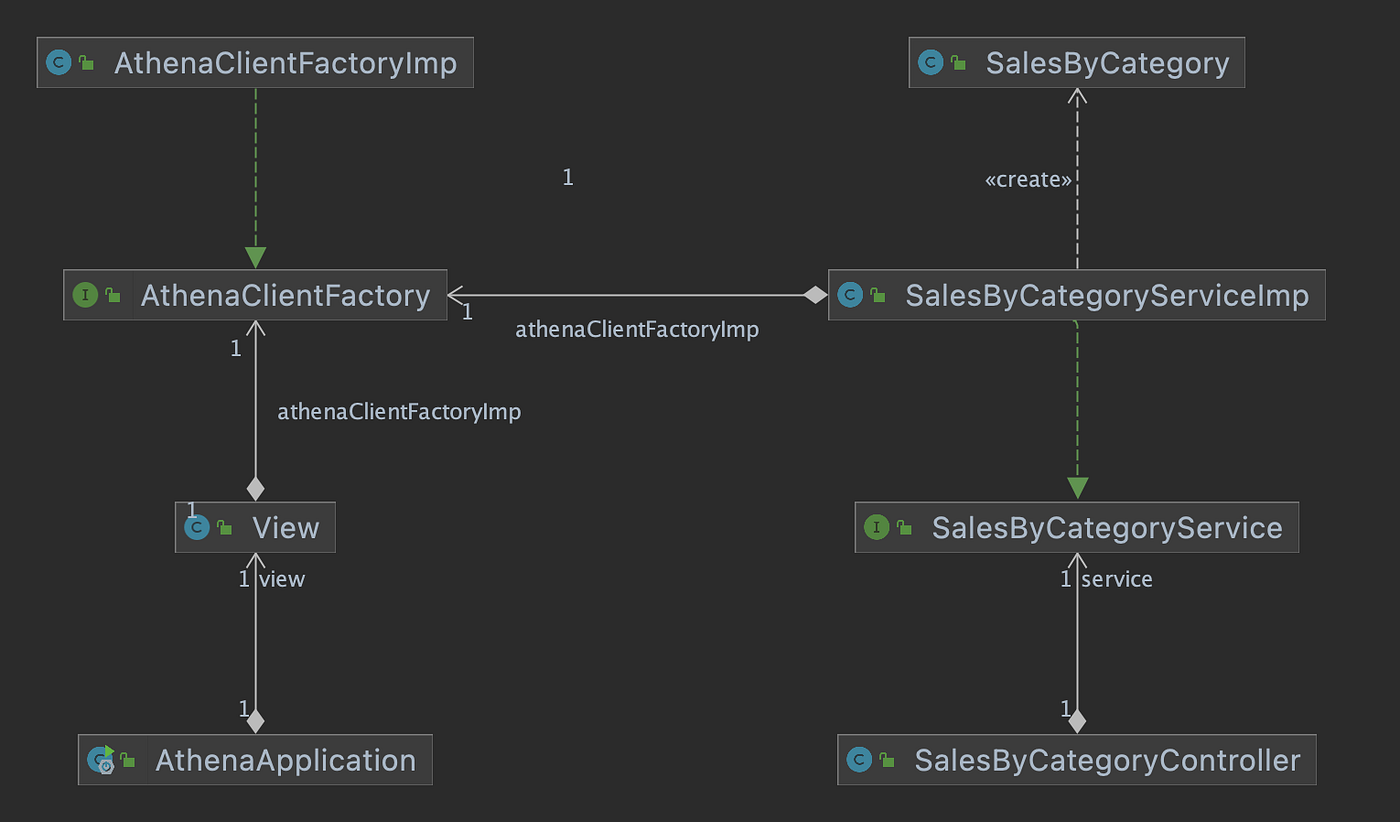
与查询Amazon Athena视图有关的Java类关系
这种确认或创建的模式在主AthenaApplication 类中的准备好的语句中重复出现*(详见下一节*)。
下面,我们看到服务在启动时调用的View 类。
除了/salesbycategory 端点查询一个视图外,其他都与查询一个表相同;它使用相同的模型-服务-控制器模式。
执行预先准备好的语句
根据文档,你可以使用Athena参数化查询功能来准备语句,以不同的查询参数重复执行同一个查询。服务使用的准备好的语句,tickit_sales_by_seller ,接受一个参数,即卖家的ID(sellerid )。准备好的语句使用/salesbyseller 端点执行。这个场景模拟了一个分析应用程序的终端用户,他想检索有关其销售的丰富的销售信息。
查询数据的模式与表和视图类似,只是我们没有使用常见的SELECT...FROM...WHERE SQL查询模式,而是使用EXECUTE...USING 模式。
例如,要为一个ID为3的卖家执行准备好的语句,我们会使用EXECUTE tickit_sales_by_seller USING 3; 。我们将卖家的ID 3作为路径参数传递,与服务所暴露的其他端点类似:/v1/salesbyseller/3 。
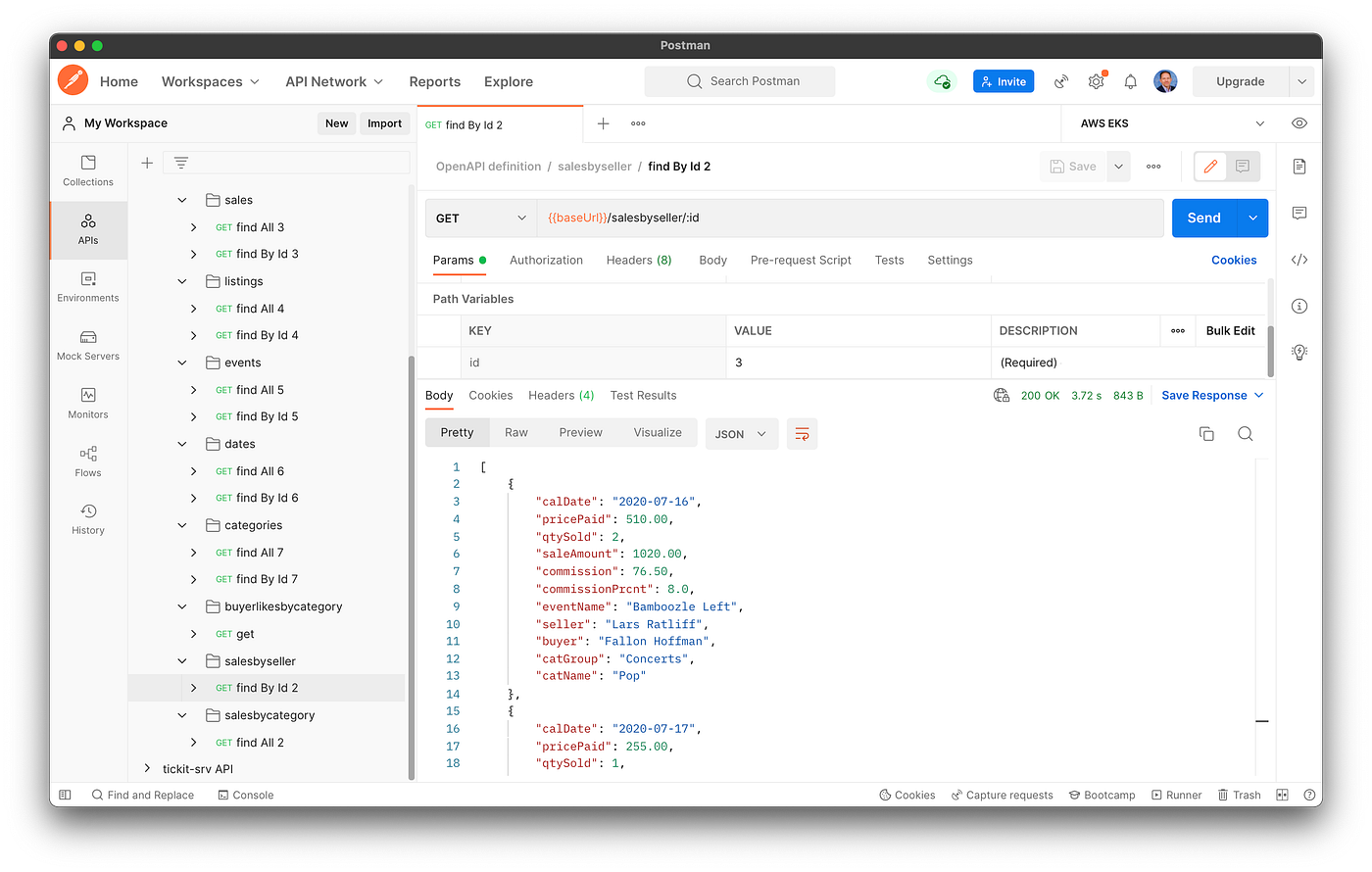
使用卖家的ID作为准备好的语句的参数,从Athena查询销售情况的结果
同样,除了/salesbyseller 端点执行一个准备好的语句并传递一个参数外,其他都与查询表或视图相同,使用相同的模型-服务-控制器模式。
使用命名查询的工作
除了表、视图和准备好的语句,Athena还有保存查询的概念,在Athena API和使用AWS CloudFormation时被称为命名查询。你可以使用Athena控制台或API来保存、编辑、运行、重命名和删除查询。查询是使用NamedQueryId ,这是查询的唯一标识符(UUID)。在处理现有的命名查询时,你必须参考NamedQueryId 。
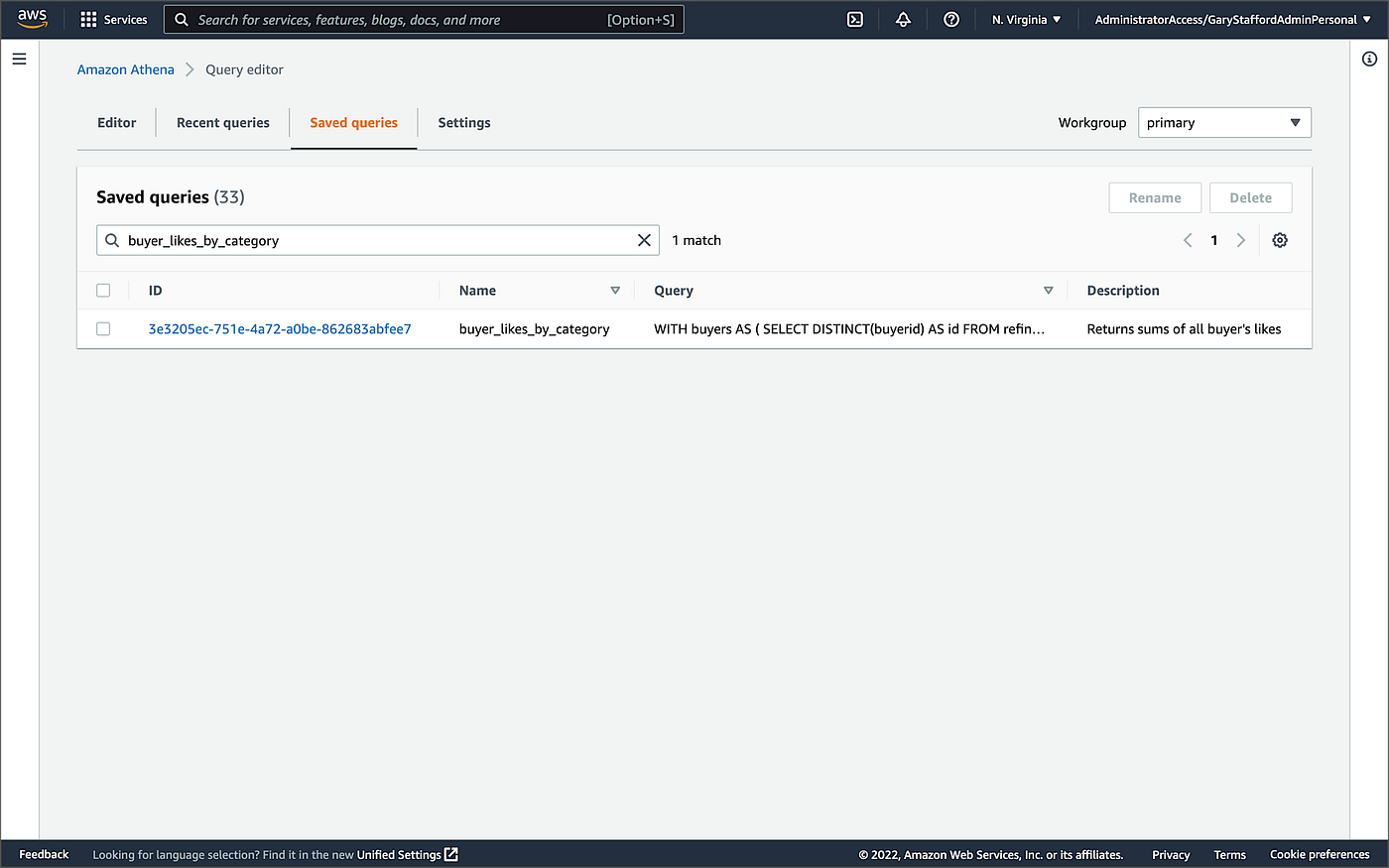
本文章中使用的保存的查询(命名查询)的例子
有多种方法可以以编程方式使用和重复使用现有的命名查询。在这个演示中,我事先创建了命名查询,buyer_likes_by_category ,然后将生成的NamedQueryId ,作为一个应用程序属性,在运行时或kubernetes部署时通过本地环境变量注入。
另外,你也可以在启动时遍历一个命名查询的列表,找到一个与名称相匹配的查询。然而,这种方法无疑会影响服务性能、启动时间和成本。最后,你可以在启动时使用一个像NamedQuery() ,包含在未使用的NamedQuery 类中的方法,类似于视图和准备好的语句。该命名查询的唯一NamedQueryId ,将被持久化为一个系统属性,可由服务类引用。缺点是,每次启动服务时,你都会创建一个重复的命名查询。因此,这种方法也不被推荐。
配置
负责为Spring Boot服务持久化配置的两个组件是application.yml 属性文件和ConfigProperties 类。该类使用Spring Framework的@ConfigurationProperties 注解。根据文档,该注解用于外部化配置。如果你想绑定和验证一些外部属性(例如,来自.properties 或.yml 文件),就把它添加到类定义或@Configuration 类中的@Bean 方法。绑定是通过调用注解类上的设置器来进行的,或者,如果使用@ConstructorBinding ,则通过绑定到构造器参数。
该 [@ConfigurationPropert](http://twitter.com/ConfigurationPropert)ies注释包括athena 的prefix 。这个值对应于application.yml 属性文件中的athena 前缀。ConfigProperties 类中的字段被绑定到application.yml 中的属性。例如,属性,namedQueryId ,被绑定到属性,athena.named.query.id 。此外,该属性被绑定到一个外部环境变量,NAMED_QUERY_ID 。这些值可以由外部配置系统、Kubernetes秘密或外部秘密管理系统提供。
AWS IAM:认证和授权
为了让Spring Boot服务与Amazon Athena、AWS Glue和Amazon S3互动,你需要建立一个AWS IAM角色,一旦通过认证,服务就会承担这个角色。该角色必须与包含必要的Athena、Glue和S3权限的附加IAM策略相关联。对于开发,该服务使用类似于下图的策略。请注意,这个策略比推荐用于生产的策略更广泛;它并不代表最小特权的安全最佳实践。特别是,在创建策略时,应严格避免对资源使用过于宽泛的* 。
除了IAM策略授予的授权,AWS Lake Formation可以与Amazon S3、AWS Glue和Amazon Athena一起使用,在数据库、表、列和行级别授予对数据集的细粒度访问。
Swagger用户界面和OpenAPI规范
查看和试验通过控制器类提供的所有端点的最简单方法是使用Swagger UI,包括在Spring Boot服务示例中,通过 [springdoc-openapi](https://springdoc.org/)Java库。Swagger UI的访问地址是:/v1/swagger-ui/index.html 。
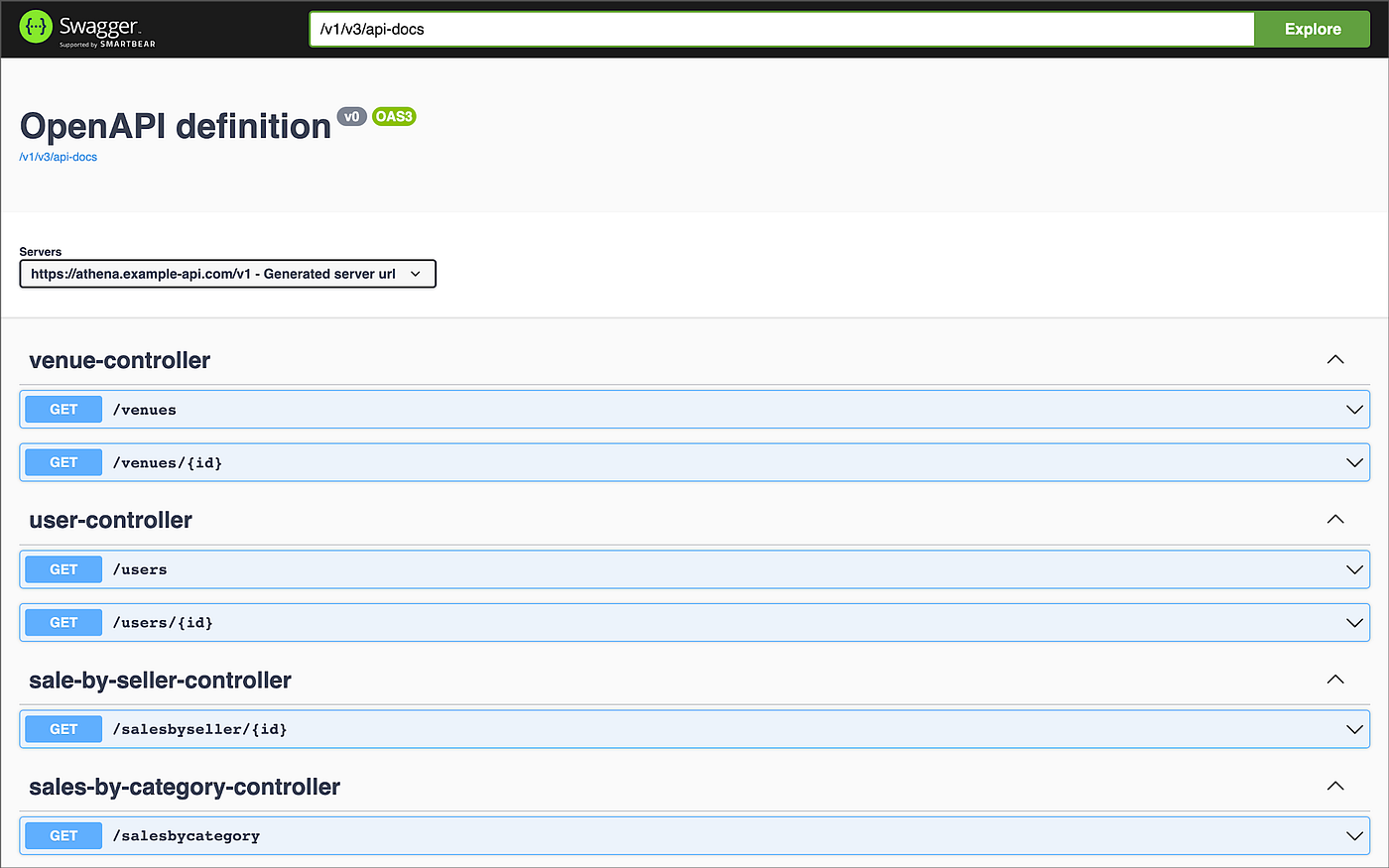
Swagger用户界面显示服务控制器类所暴露的端点
OpenAPI规范(前身为Swagger规范)是一种用于REST APIs的API描述格式。/v1/v3/api-docs 端点允许你生成一个OpenAPI v3规范文件。OpenAPI文件描述了整个API。

Spring Boot服务的OpenAPI v3规范
OpenAPI v3规范可以保存为文件并导入到Postman等应用程序中,Postman是用于构建和使用API的API平台。
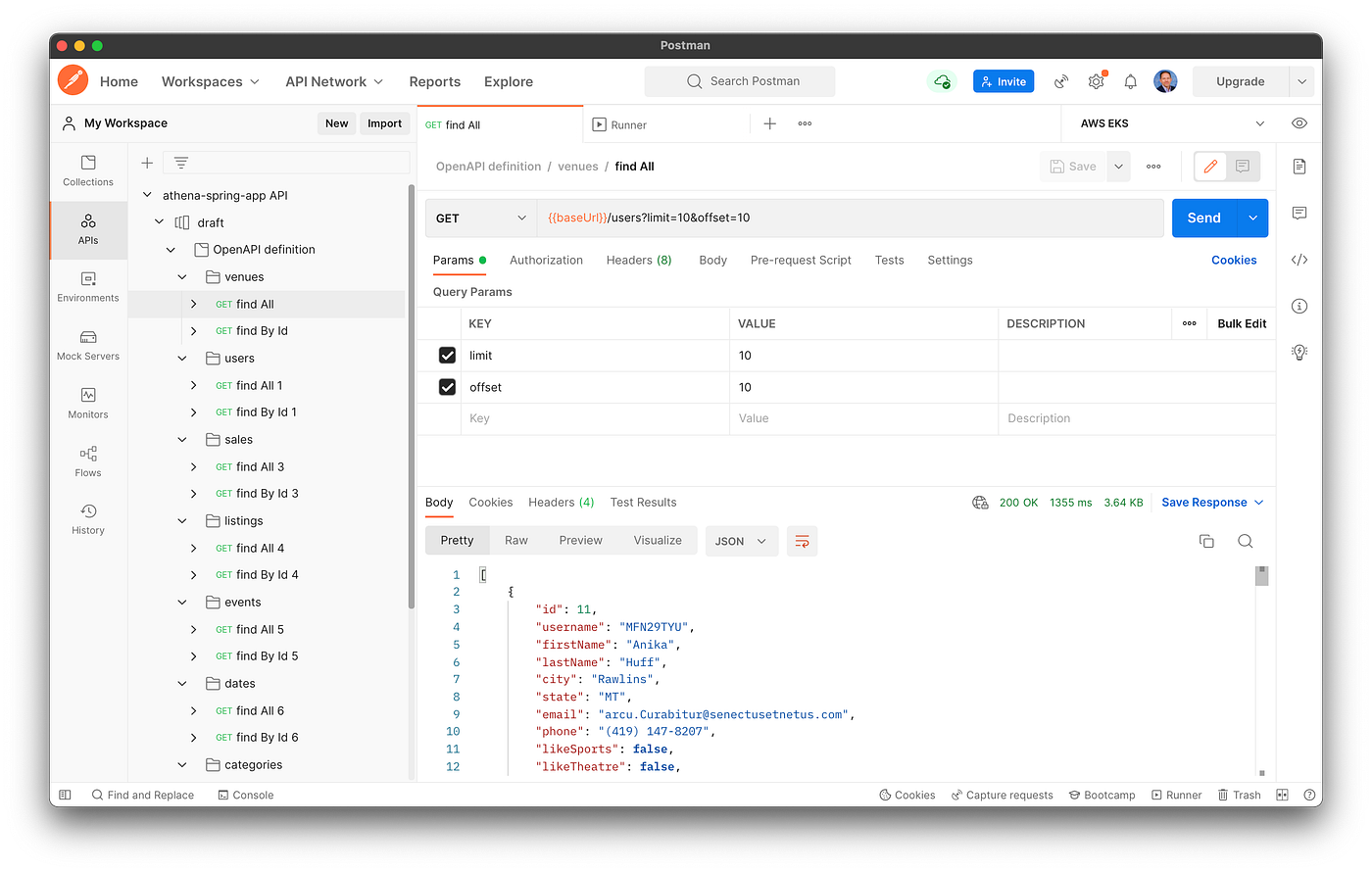
使用Postman调用服务的/users API端点

使用Postman针对Spring Boot服务运行一套集成测试
集成测试
在Spring Boot服务的源代码中,包含了数量有限的集成测试示例,不要与单元测试混淆。每个测试类都使用Spring Framework的 [@SpringBootTest](https://docs.spring.io/spring-boot/docs/current/api/org/springframework/boot/test/context/SpringBootTest.html)注解。根据文档,这个注解可以在运行基于Spring Boot的测试的测试类上指定。它提供了几个超越常规SpringTestContext 框架的功能。
集成测试使用Rest Assured的 "给定-何时-何时 "测试模式,该模式作为行为驱动开发(BDD)的一部分而大受欢迎。此外,每个测试都使用JUnit的@Test 注释。根据文档,这个注解表明被注解的方法是一个测试方法。使用这个注解的方法不能是私有或静态的,也不能返回一个值。
集成测试可以使用Gradle从项目的根部使用./gradlew clean build test 。在项目的build 目录中,会产生一个详细的测试总结,以HTML的形式,方便查阅。
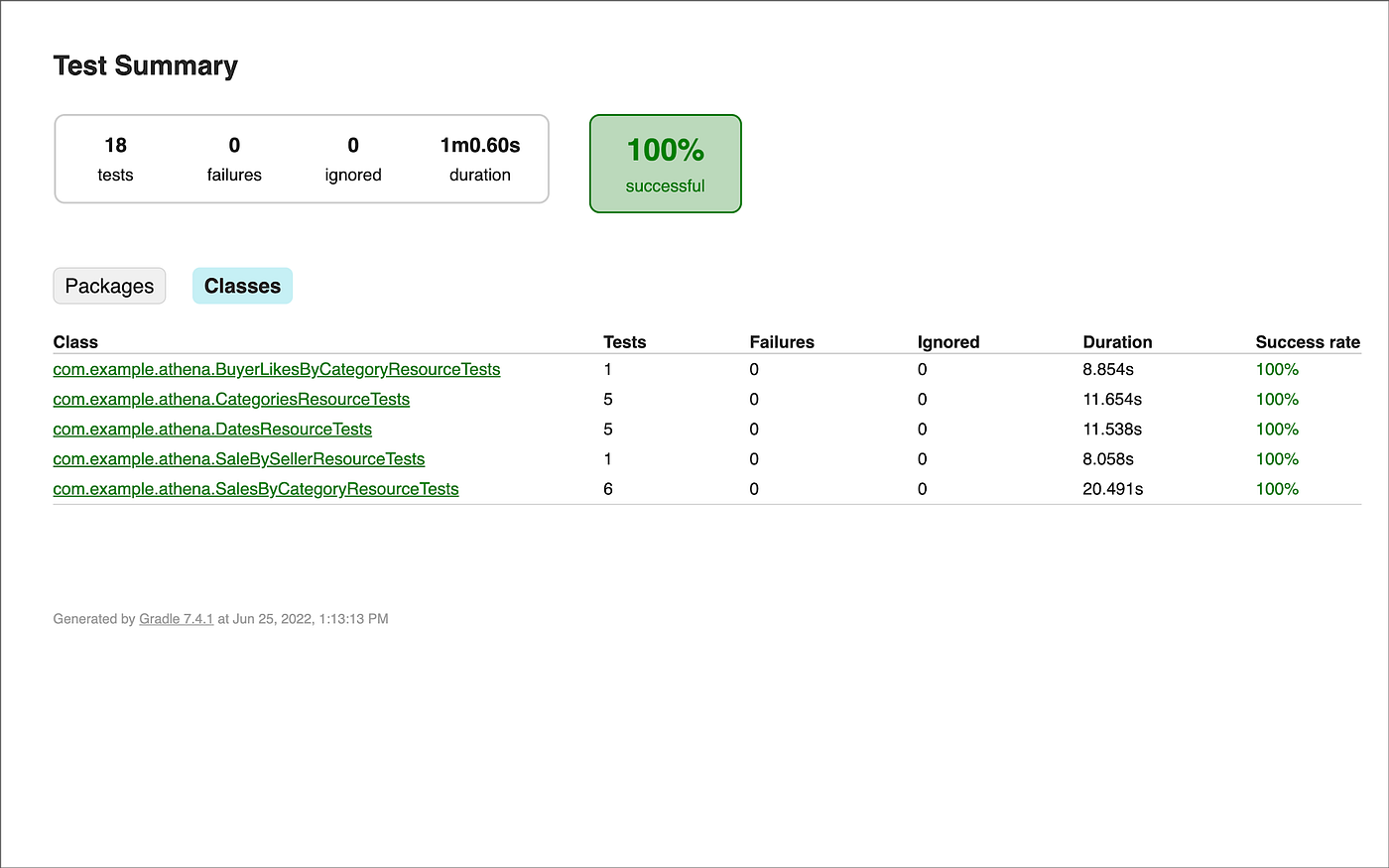
测试总结概述

测试总结的细节
负载测试服务
在生产中,Spring Boot服务需要处理多个并发用户对Amazon Athena执行查询。
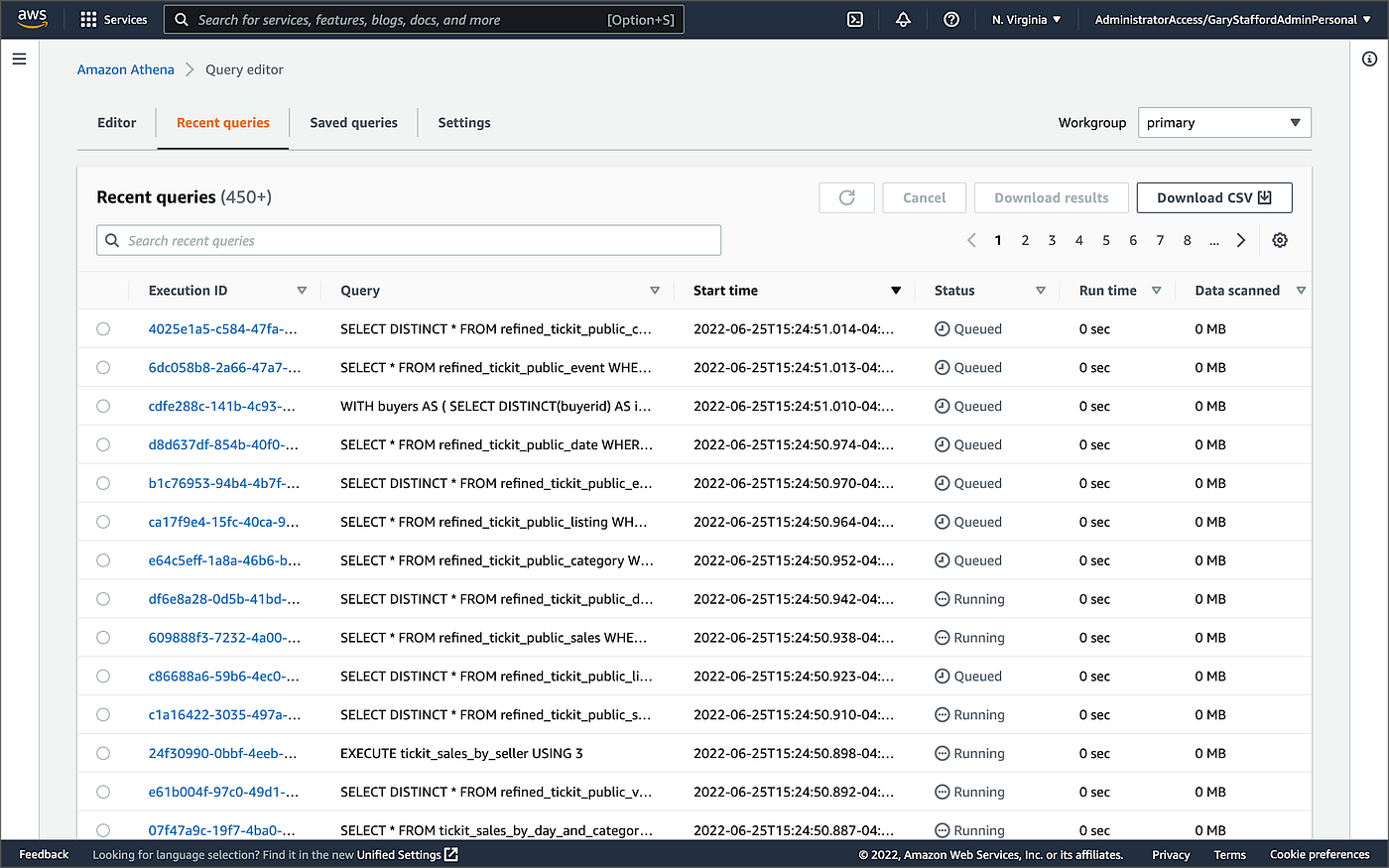
Athena的Recent Queries控制台显示了正在排队和执行的多并发查询。
我们可以使用各种负载测试工具来评估服务处理多个并发用户的能力。其中一个最简单的是我最喜欢的基于go的工具。 [hey](https://github.com/rakyll/hey),它在所提供的并发级别中使用所提供的请求数向一个URL发送负载,并打印出统计数据。它还支持HTTP2端点。因此,例如,我们可以使用hey ,对Spring Boot服务的/users 端点执行500个HTTP请求,并发级别为25。这篇文章中的测试是针对部署在Amazon EKS上的一组三个Kubernetes服务副本pod运行的。
hey -n 500 -c 25 -T "application/json;charset=UTF-8" \ -h2 https://athena.example-api.com/v1/users
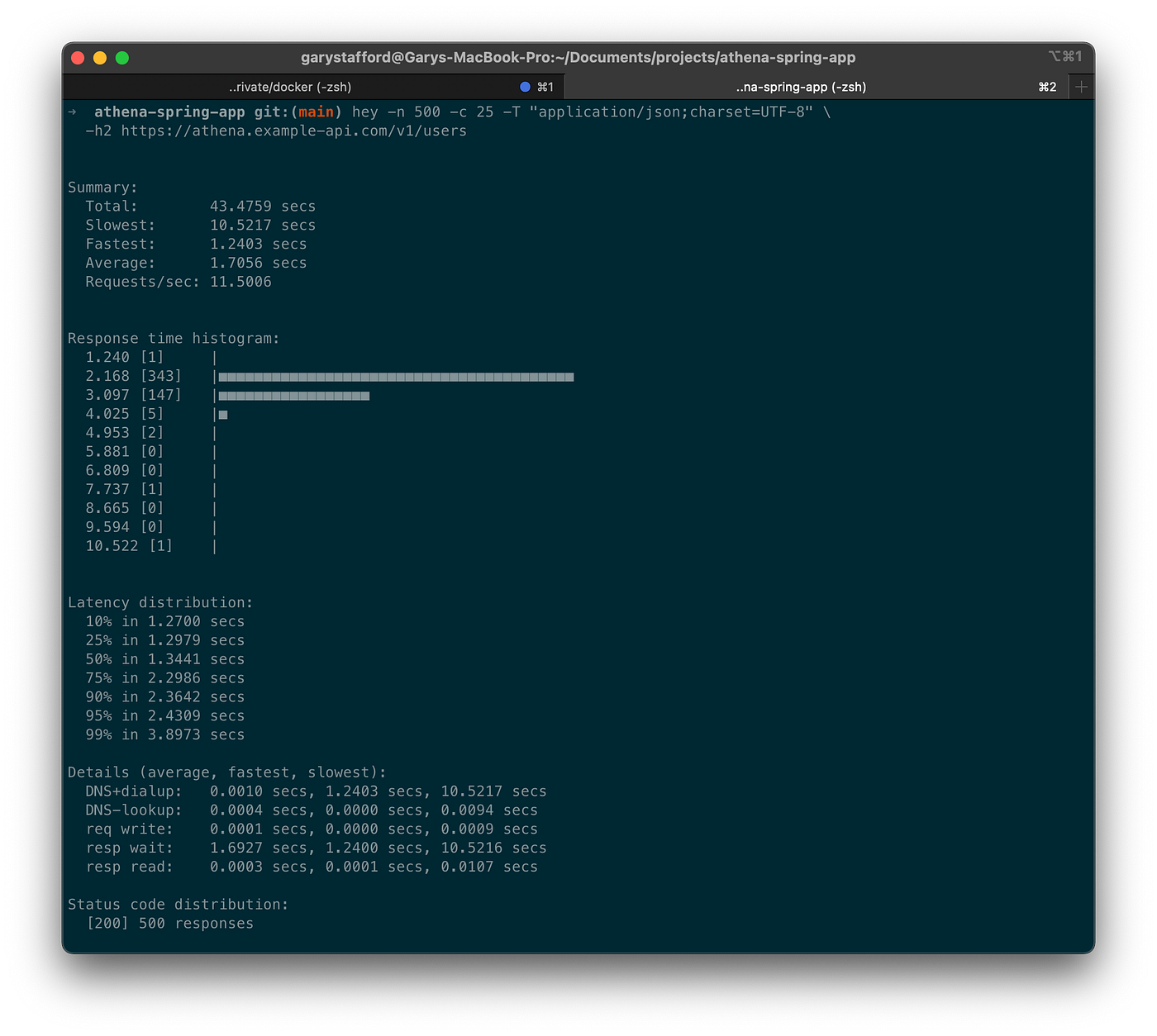
从Athena的Recent Queries控制台,我们看到许多并发的查询正在排队,并由一个hey ,通过Spring Boot服务的端点执行。
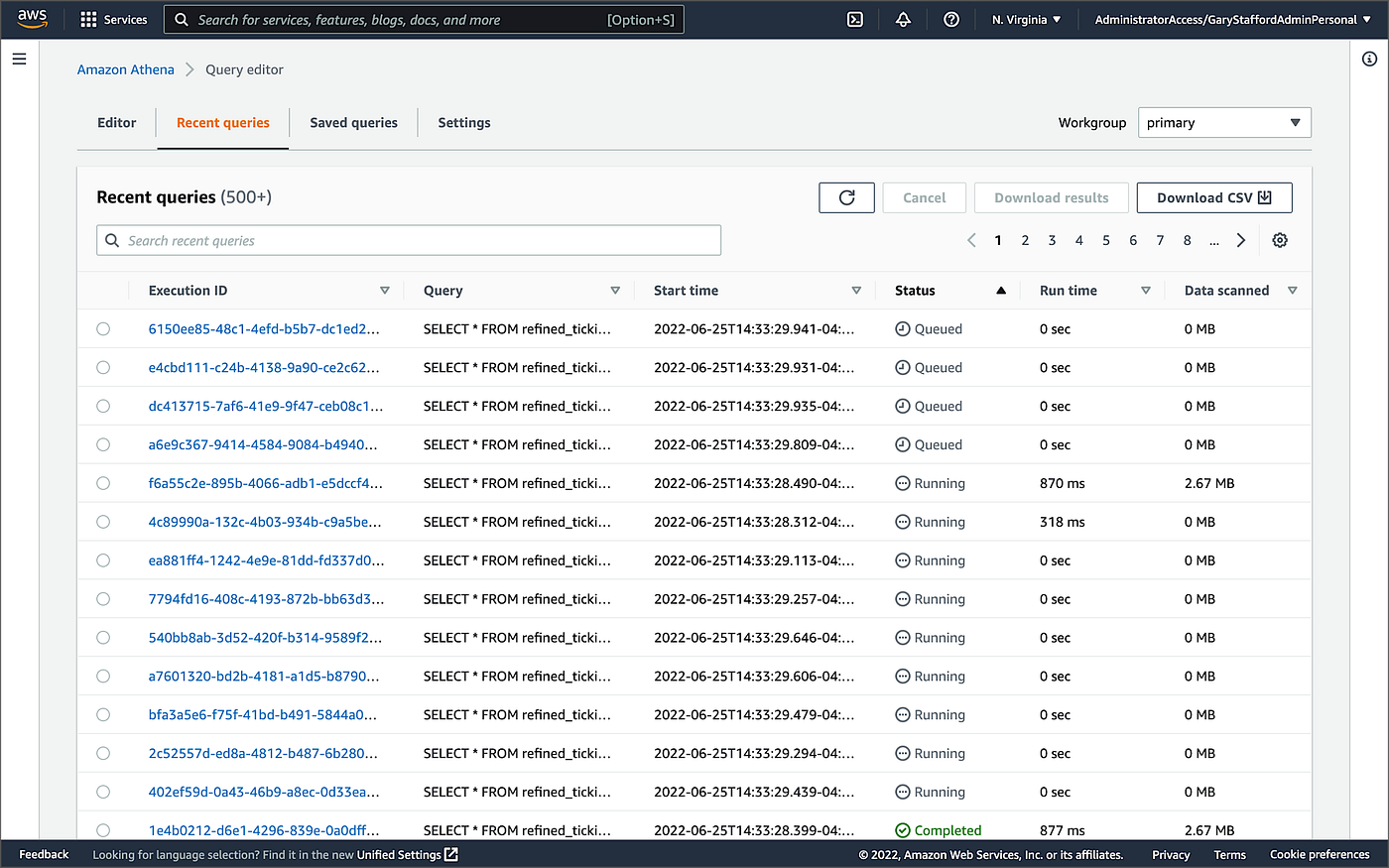
Athena的最近查询控制台显示正在排队并执行的查询。
衡量标准
Spring Boot服务实现了 [micrometer-registry-prometheus](https://quarkus.io/guides/micrometer)扩展。Micrometer指标库暴露了运行时和应用程序的指标。Micrometer定义了一个核心库,为度量和核心度量类型提供注册机制。这些度量标准由服务的/v1/actuator/prometheus 端点公开。
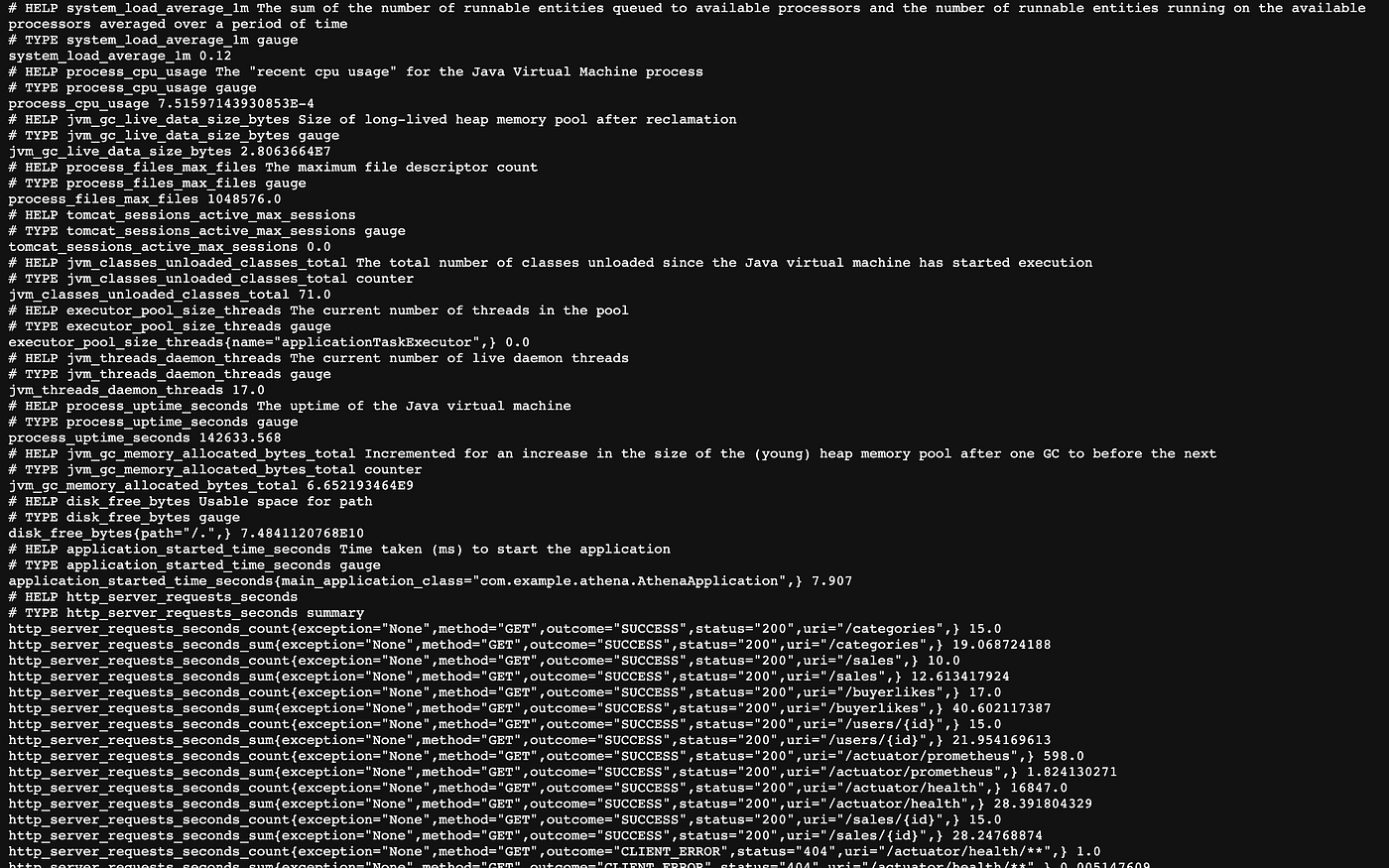
使用Prometheus端点暴露的指标
使用Micrometer扩展,/v1/actuator/prometheus 端点暴露的指标可以被Prometheus等工具刮取和可视化。方便的是,AWS提供了完全管理的Amazon Managed Service for Prometheus(AMP),它可以轻松地与Amazon EKS集成。

Prometheus从Spring Boot服务中抓取的HTTP服务器请求图
使用Prometheus作为数据源,我们可以在Grafana中建立仪表盘来观察服务的指标。与AMP一样,AWS也提供了完全管理的Amazon Managed Grafana(AMG)。
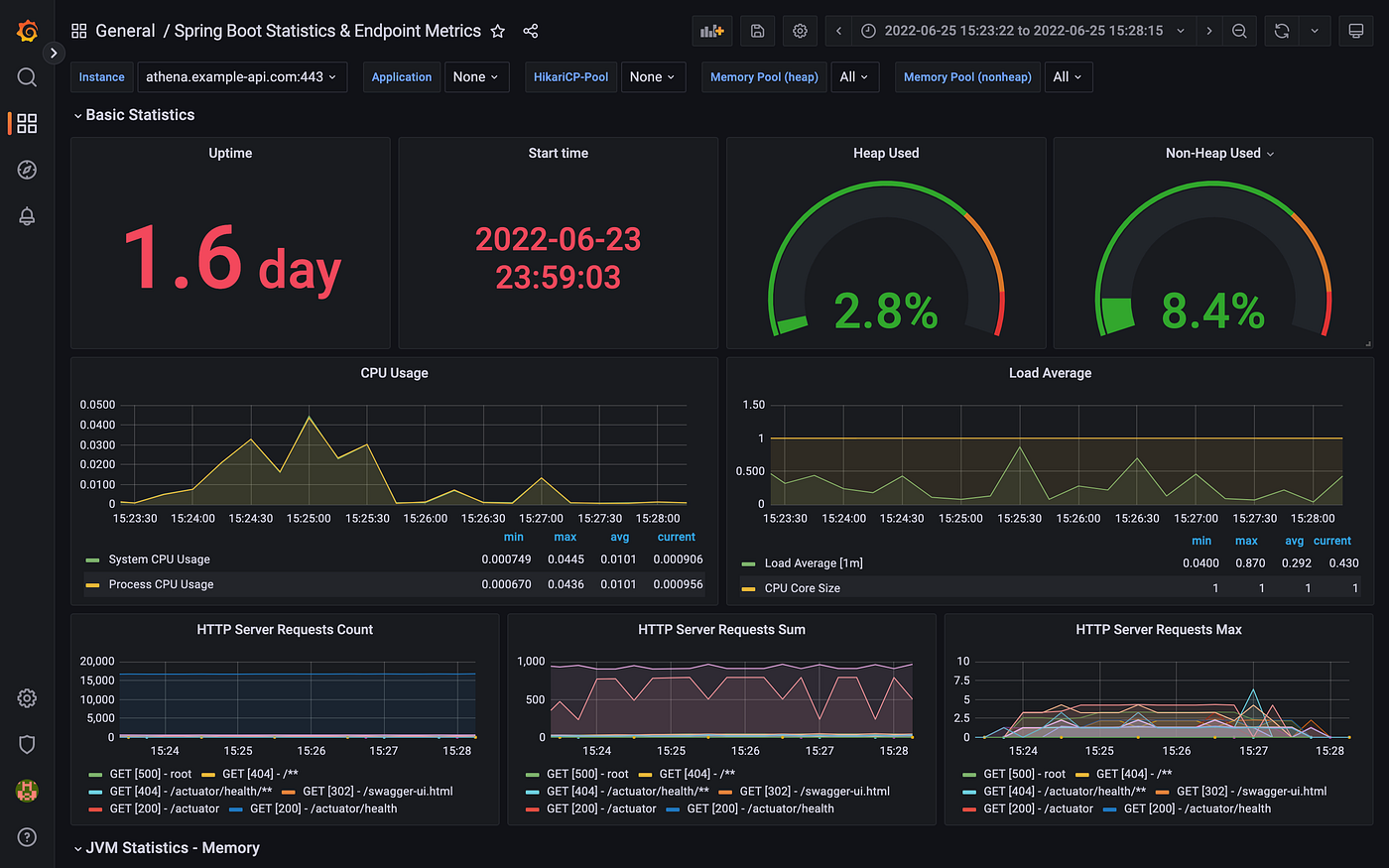
Grafana仪表盘显示部署在亚马逊EKS的Spring Boot服务的Prom Prometheus的指标

Grafana仪表盘显示部署在Amazon EKS上的Spring Boot服务的Prom Prometheus的JVM指标。
总结
这篇文章告诉我们如何创建一个Spring Boot RESTful Web服务,使最终用户的应用程序能够安全地查询存储在AWS上的数据湖中的数据。该服务使用AWS SDK for Java,通过使用Amazon Athena的AWS Glue Data Catalog访问存储在Amazon S3的数据。
本博客代表我自己的观点,而不是我的雇主亚马逊网络服务(AWS)的观点。所有产品名称、标识和品牌都是其各自所有者的财产。除非另有说明,所有图表和插图都是作者的财产。
