如果你学习的时间更长,你的总体分数会不会变得更好?
回答这个问题的一个方法是掌握关于你学习了多长时间以及你得到什么分数的数据。然后我们可以尝试看看这些数据是否有一个模式,如果在这个模式中,当你增加小时数的时候,最终也会增加分数的百分比。
例如,假设你有一个小时分数的数据集,其中包含1.5小时和87.5%的分数等条目。它也可能包含1.61小时、2.32小时和78%、97%的分数。那种可以有任何中间值(或任何级别的 "颗粒度")的数据类型被称为连续数据。
另一种情况是,你有一个小时分数数据集,其中包含基于字母的成绩,而不是基于数字的成绩,比如A、B或C。成绩是可以隔离的明确数值,因为你不可能有A.23、A+++++++++++(和到无穷大)或A * e^12。那种不能被分割或更细化定义的数据类型被称为离散数据。
根据你的数据的模式(形式)--为了弄清楚你根据学习时间会得到什么分数--你要进行回归或分类。
回归是对连续数据进行的,而分类是对离散数据进行的。回归可以是任何东西,从预测某人的年龄,价格的房子,或任何变量的价值。分类包括预测某物属于什么类别(如肿瘤是良性还是恶性)。

**注意:**预测房价和是否有癌症是不小的任务,而且两者通常都包括非线性关系。线性关系的建模相当简单,你一会儿就会看到。
如果你想通过真实世界、例子引导的实际项目来学习,请查看我们的 "实际操作房价预测--Python中的机器学习"和我们的研究级 "用深度学习进行乳腺癌分类--Keras和Tensorflow"!
对于回归和分类--我们将使用数据来预测标签(目标变量的伞状术语)。标签可以是任何东西,从分类任务的 "B"(类)到回归任务的123(数字)。因为我们也在提供标签--这些是监督学习算法。
在这个面向初学者的指南中,我们将利用Scikit-Learn库,在Python中进行线性回归。我们将经历一个端到端的机器学习管道。首先,我们将加载我们要学习的数据并将其可视化,同时进行探索性数据分析。然后,我们将对数据进行预处理,并建立模型来适应它(像手套一样)。然后对这个模型进行评估,如果有利,就用来根据新的输入来预测新的数值。
探索性数据分析
**注:**你可以在这里下载小时分数数据集。
让我们从探索性数据分析开始。你要先了解你的数据--这包括加载数据、可视化特征、探索它们之间的关系以及根据你的观察做出假设。数据集是一个CSV(逗号分隔的数值)文件,它包含了学习的时间和基于这些时间获得的分数。我们将使用Pandas把数据加载到一个DataFrame 。
import pandas as pd
如果你是第一次接触Pandas和DataFrames,请阅读我们的 "Guide to Python with Pandas:数据框架教程与实例"!
让我们读取CSV文件并将其打包成一个DataFrame 。
path_to_file = 'home/projects/datasets/student_scores.csv'
df = pd.read_csv(path_to_file)
一旦数据被加载进来,让我们用head() 方法快速浏览一下前5个值。
df.head()
这样的结果是。
Hours Scores
0 2.5 21
1 5.1 47
2 3.2 27
3 8.5 75
4 3.5 30
我们还可以通过shape 属性检查我们的数据集的形状。
df.shape
了解数据的形状对于分析数据和围绕数据建立模型通常是相当关键的。
(25, 2)
我们有25行和2列--也就是25个包含一对小时和一个分数的条目。我们最初的问题是,如果我们学习的时间更长,我们是否会得到更高的分数。从本质上讲,我们要问的是小时和分数之间的关系。那么,这些变量之间的关系是什么?探索变量之间关系的一个好方法是通过散点图。我们将在X轴上绘制小时数,在Y轴上绘制分数,对于每一对,将根据它们的值来定位一个标记。
df.plot.scatter(x='Hours', y='Scores', title='Scatterplot of hours and scores percentages')
如果你是散点图的新手 - 请阅读我们的 "Matplotlib散点图--教程和实例"!
这就导致了。
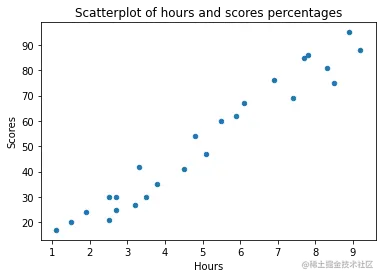
随着时间的增加,分数也会增加。这里有一个相当高的正相关关系!由于这些点所构成的线的形状似乎是直的--我们说,小时数和分数这两个变量之间存在正的线性相关关系。它们的相关性如何?corr() 方法计算并显示数字变量之间的相关性,在DataFrame 。
print(df.corr())
Hours Scores
Hours 1.000000 0.976191
Scores 0.976191 1.000000
在这个表中,小时数与小时数有1.0 (100%)的相关性,就像分数与分数有100%的相关性一样,自然也是如此。任何变量都会与自己有1:1的映射关系!然而,分数和小时之间的相关性是0.97 。任何高于0.8 ,都被认为是强正相关。
如果你想详细了解线性变量之间的相关关系,以及不同的相关系数,请阅读我们的 ! "用Numpy在Python中计算皮尔逊相关系数"!
有一个高的线性相关意味着我们通常能够根据另一个特征来判断一个特征的价值。即使不计算,你也可以知道,如果某人学习了5个小时,他们的分数会有50%左右。由于这种关系非常强烈--我们将能够建立一个简单而准确的线性回归算法,在这个数据集上根据学习时间来预测分数。
当我们在两个变量之间有线性关系时,我们将看到一条线。当三个、四个、五个(或更多)变量之间存在线性关系时,我们将看到一个平面的交点。在任何情况下,这种质量在代数中都被定义为线性。
Pandas还附带了一个很好的统计总结的辅助方法,我们可以describe() ,以了解我们的列的平均值、最大值、最小值等的情况。
print(df.describe())
Hours Scores
count 25.000000 25.000000
mean 5.012000 51.480000
std 2.525094 25.286887
min 1.100000 17.000000
25
50
75
max 9.200000 95.000000
线性回归理论
我们的变量表达了一种线性关系。我们可以根据学习的小时数直观地推测出分数百分比。然而,我们可以定义一个更正式的方式来做这件事吗?我们可以在我们的点之间追踪一条线,如果我们从 "小时数 "的给定值中追踪一条垂直线,就可以读出 "分数 "的值。
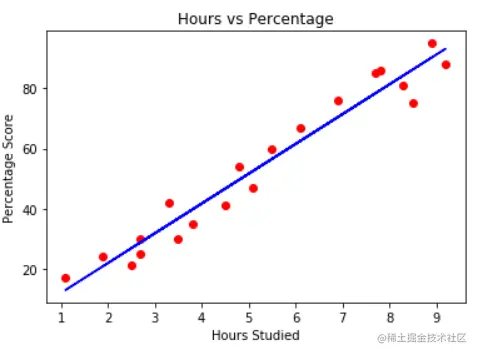
描述任何直线的方程是:
$
y = a*x+b
在这个方程中,`y` 代表分数百分比,`x` 代表学习时间。`b` 是直线在Y轴上的起点,也叫Y轴**截距**,`a` 定义了直线是否会更倾向于图形的上部或下部(直线的角度),所以它被称为直线的**斜率**
。
> 通过调整直线的**斜率**和**截距**,我们可以将其向任何方向移动。因此--通过计算斜率和截距值,我们可以调整一条线来适应我们的数据!
这就是了!这就是线性回归的核心,一个算法实际上只需找出斜率和截距的值。它使用我们已有的`x` 和`y` 的值,并改变`a` 和`b` 的值。通过这样做,它将多条线与数据点进行拟合,并返回更接近所有数据点的线,或**最佳拟合线**。通过对这种线性关系进行建模,我们的回归算法也被称为**模型**。在这个过程中,当我们试图根据小时数来确定,或*预测*百分比时,这意味着我们的`y` 变量取决于我们的`x` 变量的值。

**注:**在**统计学**中,人们习惯于把`y` 称作*因变量*,把`x` 称作*自变量*。在**计算机科学**中,`y` 通常被称为*目标*、*标签*,而`x` *特征*、或*属性*。你会看到这些名称的互换,请记住,通常有一个我们想要预测的变量和另一个用来寻找它的值。在统计学和CS中,使用大写的`X` ,而不是小写的,这也是一种惯例。
### 使用Python的Scikit-learn进行线性回归
有了这些理论,让我们用Python和Scikit-Learn库来实现线性回归算法吧!我们将从一个比较简单的线性回归开始。我们将从一个较简单的线性回归开始,然后用一个新的数据集扩展到*多元线性回归*。
#### 数据预处理
在上一节中,我们已经导入了Pandas,将我们的文件加载到`DataFrame` ,并绘制了一个图形,看看是否有线性关系的迹象。现在,我们可以把我们的数据分成两个数组--一个是因果特征,一个是独立特征,或者说目标特征。由于我们想根据学习的时间来预测分数的百分比,我们的`y` *"分数 "*列,我们的`X` *"小时 "*列。
为了分离目标和特征,我们可以将数据框架的列值归属于我们的`y` 和`X` 变量。
```
y = df['Scores'].values.reshape(-1, 1)
X = df['Hours'].values.reshape(-1, 1)
```

**注意:** `df['Column_Name']` 返回一个pandas`Series` 。一些库可以像对待NumPy数组一样对待`Series` ,但不是所有的库都有这种意识。在某些情况下,你会想提取描述你的数据的底层NumPy数组。这很容易通过`values` 字段的`Series` 来实现。
Scikit-Learn的线性回归模型期望有一个二维输入,如果我们只是提取数值,我们实际上是在提供一个一维数组。
```
print(df['Hours'].values) # [2.5 5.1 3.2 8.5 3.5 1.5 9.2 ... ]
print(df['Hours'].values.shape) # (25,)
```
它期望一个二维输入,因为`LinearRegression()` 类(后面会详细介绍)期望的条目可能包含多个单值(但也可能是一个单值)。无论哪种情况,它都必须是一个二维数组,其中每个元素(小时)实际上是一个1元素的数组。
```
print(X.shape) # (25, 1)
print(X) # [[2.5] [5.1] [3.2] ... ]
```
我们已经可以将我们的`X` 和`y` 数据直接送入我们的线性回归模型,但是如果我们一次性使用所有的数据,我们怎么能知道我们的结果是否好呢?就像在学习中一样,我们要做的是,用一部分数据来**训练**我们的模型,用另一部分来**测试**它。
> 如果你想了解更多关于经验法则、分割集的重要性、验证集和`train_test_split()` 辅助方法的信息,请阅读我们的详细指南: [*"Scikit-Learn的train\_test\_split() - 训练、测试和验证集"*](https://stackabuse.com/scikit-learns-traintestsplit-training-testing-and-validation-sets/)!
这很容易通过助手`train_test_split()` 方法实现,该方法接受我们的`X` 和`y` 数组(也适用于`DataFrame`s,并将单个`DataFrame` 分成训练和测试集),以及一个`test_size` 。`test_size` 是我们将用于测试的整个数据的百分比。
```
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
```
该方法在尊重我们定义的百分比的情况下随机抽取样本,但要尊重X-Y对,以免抽样会完全搅乱这种关系。一些常见的训练-测试分割是*80/20*和*70/30*。
由于抽样过程本身是*随机*的,所以我们在运行该方法时总会有不同的结果。为了能够有相同的结果,或者说*可重复的*结果,我们可以定义一个叫做`SEED` 的常数,其数值为生命的意义(42)。
```
SEED = 42
```

**注意:**种子可以是任何整数,作为随机采样器的种子。种子通常是随机的,可以获得不同的结果。然而,如果你手动设置它,采样器将返回相同的结果。按照惯例,使用`42` 作为种子,是对流行小说系列*"银河系的搭车指南 "*的一种参考。
然后我们可以把这个`SEED`传递给我们的`train_test_split` 方法的`random_state` 参数。
```
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = SEED)
```
现在,如果你打印你的`X_train` 数组--你会发现学习时间,而`y_train` 包含分数的百分比。
```
print(X_train) # [[2.7] [3.3] [5.1] [3.8] ... ]
print(y_train) # [[25] [42] [47] [35] ... ]
```
#### 训练一个线性回归模型
我们已经准备好我们的训练集和测试集。Scikit-Learn有大量的模型类型,我们可以轻松地导入和训练,`LinearRegression` 就是其中之一。
```
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
```
现在,我们需要对我们的数据进行拟合,我们将通过使用`.fit()` 方法和我们的`X_train` 和`y_train` 数据来实现。
```
regressor.fit(X_train, y_train)
```
如果没有抛出错误--回归器找到了最佳拟合线!这条线是由我们的特征和截距/斜率定义的。事实上,我们可以通过打印`regressor.intecept_` 和`regressor.coef_` 属性分别检查截距和斜率。
```
print(regressor.intercept_)
```
```
2.82689235
```
用于检索斜率(也是x的**系数**)。
```
print(regressor.coef_)
```
其结果应该是。
```
[9.68207815]
```
这可以很好地插入我们之前的公式中。
score = 9.68207815*hours+2.82689235
让我们快速检查一下这是否与我们的猜测一致。
h o u r s \= 5 s c o r e 9.68207815 ∗ h o u r s + 2.82689235 s c o r e 51.2672831
通过5小时的学习,你可以期待51%左右的分数!另一种解释截距值的方法是--如果一个学生在考试中比以前多学了一个小时,考虑到他们以前取得的分数百分比,他们可以预期增加*9.68%*。
> 换句话说,斜率值显示了当*自变量* *增加(或减少)* *一个单位*时,*因变量会发生什么变化*。
#### 进行预测
为了避免自己进行计算,我们可以编写自己的公式来计算这个值。
```
def calc(slope, intercept, hours):
return slope*hours+intercept
score = calc(regressor.coef_, regressor.intercept_, 9.5)
print(score) # [[94.80663482]]
```
然而--使用我们的模型*预测*新值的一个更方便的方法是调用`predict()` 函数。
```
# Passing 9.5 in double brackets to have a 2 dimensional array
score = regressor.predict([[9.5]])
print(score) # 94.80663482
```
我们的结果是`94.80663482` ,或大约*95%*。现在,我们对我们能想到的每一个小时都有一个分数百分比估计。但是我们能相信这些估计吗?这个问题的答案就是我们首先将数据分成训练和测试的原因。现在我们可以使用我们的测试数据进行预测,并将预测结果与我们的实际结果--*地面真相*结果进行比较。
为了对测试数据进行预测,我们将`X_test` 值传递给`predict()` 方法。我们可以将结果分配给变量`y_pred` 。
```
y_pred = regressor.predict(X_test)
```
`y_pred` 变量现在包含了`X_test` 中输入值的所有预测值。我们现在可以将`X_test` 的实际输出值与预测值进行比较,将它们并排排列在一个数据帧结构中。
```
df_preds = pd.DataFrame({'Actual': y_test.squeeze(), 'Predicted': y_pred.squeeze()})
print(df_preds
```
输出结果看起来是这样的。
```
Actual Predicted
0 81 83.188141
1 30 27.032088
2 21 27.032088
3 76 69.633232
4 62 59.951153
```
尽管我们的模型似乎不是很精确,但预测的百分比与实际的百分比很接近。让我们对实际值和预测值之间的差异进行量化,以获得对其实际表现的客观看法。
#### 评估该模型
在看完数据,看到线性关系,训练和测试我们的模型后,我们可以通过一些*指标*来了解它的预测效果如何。对于回归模型,主要使用三个*评价指标*。
1. **平均绝对误差(MAE)**。当我们从实际值中减去预测值,得到误差,将这些误差的绝对值相加,得到其平均值。这个指标给出了模型每次预测的总体误差的概念,越小(越接近0)越好。
mae = (frac{1}{n})/sum_{i=1}^{n}\left | Actual - Predicted \right |
∗∗注意:∗∗你可能还会在方程中遇到‘y‘和‘y^‘的符号。‘y‘是指实际值,‘y^‘是指预测值。2.∗∗平均平方误差(MSE)∗∗。它与MAE指标类似,但它是对误差的绝对值进行平方。另外,与MAE一样,越小,或越接近0,越好。MSE值的平方是为了使大的误差变得更大。需要注意的是,由于其数值的大小和它们不在数据的同一尺度上,它通常是一个难以解释的指标。
mse = sum_{i=1}^{D}(实际-预测)^2
3.∗∗均方根误差(RMSE)∗∗。试图通过获取其最终值的平方根来解决与MSE有关的解释问题,以便将其缩回到数据的相同单位。当我们需要展示或显示数据的实际值与误差时,它更容易解释,也很好。它显示了数据的变化程度,因此,如果我们的RMSE为4.35,我们的模型可能会出现错误,因为它在实际值上增加了4.35,或者需要4.35才能达到实际值。越接近于0,也就越好。
rmse = sqrt{ `sum_{i=1}^{D}(实际 - 预测)^2}
我们可以使用这三个指标中的任何一个来*比较*模型(如果我们需要选择一个)。我们也可以用不同的参数值或不同的数据来比较同一个回归模型,然后再考虑评价指标。这就是所谓的*超参数调整*\--调整影响学习算法的超参数并观察结果。
在模型之间进行选择时,误差最小的模型,通常表现更好。在监测模型时,如果指标变差了,那么以前版本的模型就会更好,或者数据有一些明显的改变,使模型的表现比原来差。
幸运的是,我们不需要手动进行任何指标计算。Scikit-Learn包已经提供了一些函数,可以用来为我们找出这些指标的值。让我们用我们的测试数据找出这些指标的值。首先,我们将导入必要的模块来计算MAE和MSE误差。分别是`mean_absolute_error` 和`mean_squared_error` 。
```
from sklearn.metrics import mean_absolute_error, mean_squared_error
```
现在,我们可以通过将`y_test` (实际)和`y_pred` (预测)传递给方法来计算MAE和MSE。RMSE可以通过取MSE的平方根来计算,为此,我们将使用NumPy的`sqrt()` 方法。
```
import numpy as np
```
用于度量衡的计算。
```
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
```
我们还将使用`f` 字符串和逗号后的2位数精度来打印度量结果,`:.2f` 。
```
print(f'Mean absolute error: {mae:.2f}')
print(f'Mean squared error: {mse:.2f}')
print(f'Root mean squared error: {rmse:.2f}')
```
衡量标准的结果将看起来像这样。
```
Mean absolute error: 3.92
Mean squared error: 18.94
Root mean squared error: 4.35
```
我们所有的误差都很低--而且我们最多只与实际值相差4.35(更低或更高),考虑到我们的数据,这是一个相当小的范围。
### 多重线性回归
到此为止,我们只用一个变量用线性回归预测了一个值。我们可以考虑一种不同的情况,即我们可以使用*许多变量*而不是一个*变量*进行预测,这也是现实生活中更常见的情况,许多事情都会影响一些结果。
例如,如果我们想预测美国各州的汽油消耗量,只使用一个变量,例如汽油税,是有局限性的,因为不仅仅是汽油税会影响消耗量。除了汽油税之外,还有更多的东西涉及到汽油消费,比如某个地区人们的人均收入,铺设的高速公路的延伸,拥有驾驶执照的人口比例,以及许多其他因素。有些因素对消费的影响比其他因素更大--而这正是相关系数真正发挥作用的地方!"。
在这样的情况下,当使用多个变量有意义时,线性回归就变成了**多元线性回归**。

**注**:另一种对有一个自变量的线性回归的命名法是*单变量*线性回归。而对于有许多独立变量的多元线性回归,则是*多元*线性回归。
通常,现实世界的数据,由于有更多的变量,有更大的数值范围,或更多的**变异性**,以及变量之间的复杂关系--将涉及多元线性回归而不是简单的线性回归。
> 也就是说,在日常工作中,如果你的数据存在线性关系,你可能会对你的数据进行多元线性回归。
#### 探索性数据分析
为了获得对多元线性回归的实际感受,让我们继续使用我们的天然气消费例子,并使用一个拥有美国48个州的天然气消费数据的数据集。

**注:**你可以在[Kaggle](https://www.kaggle.com/datasets/harinir/petrol-consumption)上下载天然气消费数据集。你可以 [在这里](http://people.sc.fsu.edu/~jburkardt/datasets/regression/x16.txt)了解更多关于该数据集的细节。
按照我们在线性回归中的做法,在应用多元线性回归之前,我们也要了解我们的数据。首先,我们可以用pandas`read_csv()` 方法导入数据。
```
path_to_file = 'home/projects/datasets/petrol_consumption.csv'
df = pd.read_csv(path_to_file)
```
我们现在可以用`df.head()` ,看一下前五行。
```
df.head()
```
这样做的结果是。
```
Petrol_tax Average_income Paved_Highways Population_Driver_licence(%) Petrol_Consumption
0 9.0 3571 1976 0.525 541
1 9.0 4092 1250 0.572 524
2 9.0 3865 1586 0.580 561
3 7.5 4870 2351 0.529 414
4 8.0 4399 431 0.544 410
```
我们可以用`shape` 来查看我们的数据有多少行和多少列。
```
df.shape
```
它显示。
```
(48, 5)
```
在这个数据集中,我们有48行和5列。在对数据集的大小进行分类时,统计学和计算机科学之间也存在着差异。
> 在统计学中,一个超过30或超过100行(或**观测值**)的数据集已经被认为是大的,而在计算机科学中,一个数据集通常至少要有1000-3000行才能被认为是 "大 "的。"大 "也是非常主观的--有些人认为3,000大,而有些人认为3,000,000大。
对于我们的数据集的大小,目前还没有共识。让我们继续探索,看一看这个新数据的描述性统计。这一次,我们将通过用`round()` 方法将数值四舍五入到两位小数,以及用`T` 属性对表格进行转置,来促进统计数据的比较。
```
print(df.describe().round(2).T)
```
我们的表格现在是列宽,而不是行宽。
```
count mean std min 25% 50% 75% max
Petrol_tax 48.0 7.67 0.95 5.00 7.00 7.50 8.12 10.00
Average_income 48.0 4241.83 573.62 3063.00 3739.00 4298.00 4578.75 5342.00
Paved_Highways 48.0 5565.42 3491.51 431.00 3110.25 4735.50 7156.00 17782.00
Population_Driver_licence(%) 48.0 0.57 0.06 0.45 0.53 0.56 0.60 0.72
Petrol_Consumption 48.0 576.77 111.89 344.00 509.50 568.50 632.75 968.00
```

**注意:**如果我们想在统计数字之间进行比较,转置后的表格会更好,如果我们想在变量之间进行比较,原始表格会更好。
通过观察描述表的*最小*和*最大*列,我们看到我们数据中的最小值是`0.45` ,最大值是`17,782` 。这意味着我们的数据范围是`17,781.55` (17,782 - 0.45 = 17,781.55),非常宽--这意味着我们的数据可变性也很高。
另外,通过比较*平均值*和*std*列的值,如`7.67` 和`0.95` ,`4241.83` 和`573.62` ,等等,我们可以看到平均值确实离标准差很远。这意味着我们的数据离平均值很远,是*分散的*\--这也增加了变化性。
我们已经有两个迹象表明我们的数据是分散的,这对我们不利,因为这使得我们更难有一条可以从0.45到17,782的线--在统计学上,*解释这种变异*。
不管怎么说,我们绘制数据总是很重要的。具有不同形状(关系)的数据可以有相同的描述性统计。因此,让我们继续下去,在图表中看看我们的点。

**注:**具有不同形状的数据具有相同的描述性统计的问题被定义**为安斯康伯的四重奏**。你可以[在这里](https://www.autodesk.com/research/publications/same-stats-different-graphs)看到它的例子。
不同关系之间系数相同的另一个例子是皮尔逊相关(检查**线性相关**)。
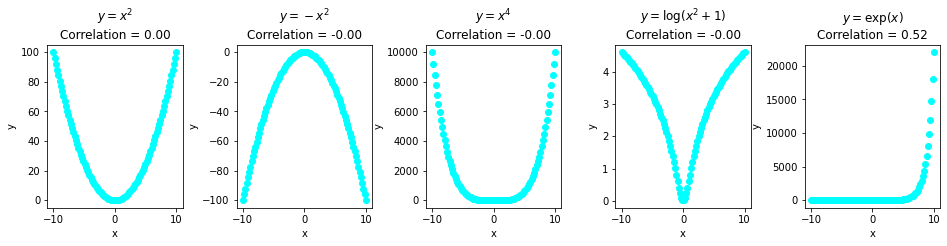
这个数据显然有一个模式!虽然,它是非线性的,而且数据没有线性相关,因此,皮尔逊系数对大多数人来说是`0` 。对于随机噪声,它也会是`0` 。
> 同样,如果你有兴趣阅读更多关于皮尔逊系数的信息,请阅读深入的 [*"用Numpy在Python中计算皮尔逊相关系数"*](https://stackabuse.com/calculating-pearson-correlation-coefficient-in-python-with-numpy/)!
在我们的简单回归方案中,我们已经使用了因变量和自变量的散点图来观察这些点的形状是否接近一条线。在目前的情况下,我们有四个自变量和一个因变量。如果用所有的变量做散点图,每个变量需要一个维度,结果就是5D图。
我们可以用所有的变量创建一个5D图,这需要花费一些时间,而且有点难以阅读--或者我们可以为每个自变量和因变量绘制一个散点图,看看它们之间是否存在线性关系。
按照*奥卡姆剃刀*(又称奥卡姆剃刀)和Python的[PEP20](https://peps.python.org/pep-0020/)\--*"简单的比复杂的好"*\--我们将为每个变量创建一个带有绘图的for循环。

**注:**奥卡姆/奥卡姆剃刀是一个哲学和科学原则,它指出在复杂的理论或解释方面,应首选最简单的理论或解释。
这一次,我们将使用**Seaborn**,这是Matplotlib的一个扩展,Pandas在绘图时在引擎盖下使用。
```
import seaborn as sns # Convention alias for Seaborn
variables = ['Petrol_tax', 'Average_income', 'Paved_Highways','Population_Driver_licence(%)']
for var in variables:
plt.figure() # Creating a rectangle (figure) for each plot
# Regression Plot also by default includes
# best-fitting regression line
# which can be turned off via `fit_reg=False`
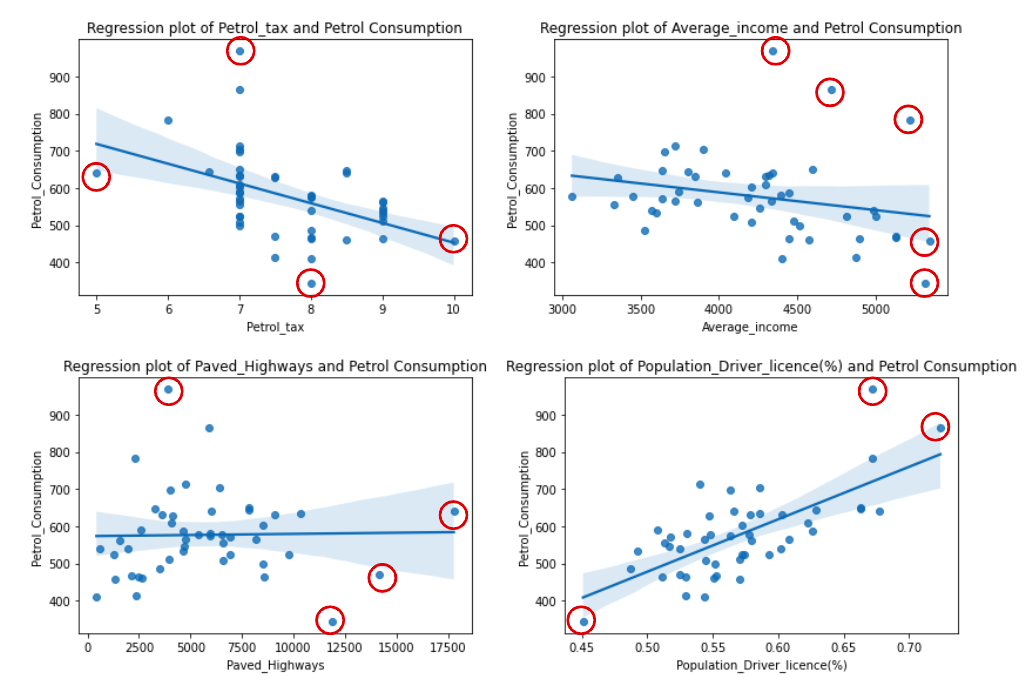
sns.regplot(x=var, y='Petrol_Consumption', data=df).set(title=f'Regression plot of {var} and Petrol Consumption');
```
请注意,在上面的代码中,我们正在导入Seaborn,创建一个我们想要绘制的变量列表,并通过该列表循环绘制每个自变量和我们的因变量。
我们使用的Seaborn图是`regplot` ,它是**回归图**的简称。它是一个散点图,已经将分散的数据与回归线一起绘制出来。如果你想看一个没有回归线的散点图,可以用`sns.scatteplot` 来代替。
这就是我们的四张图。
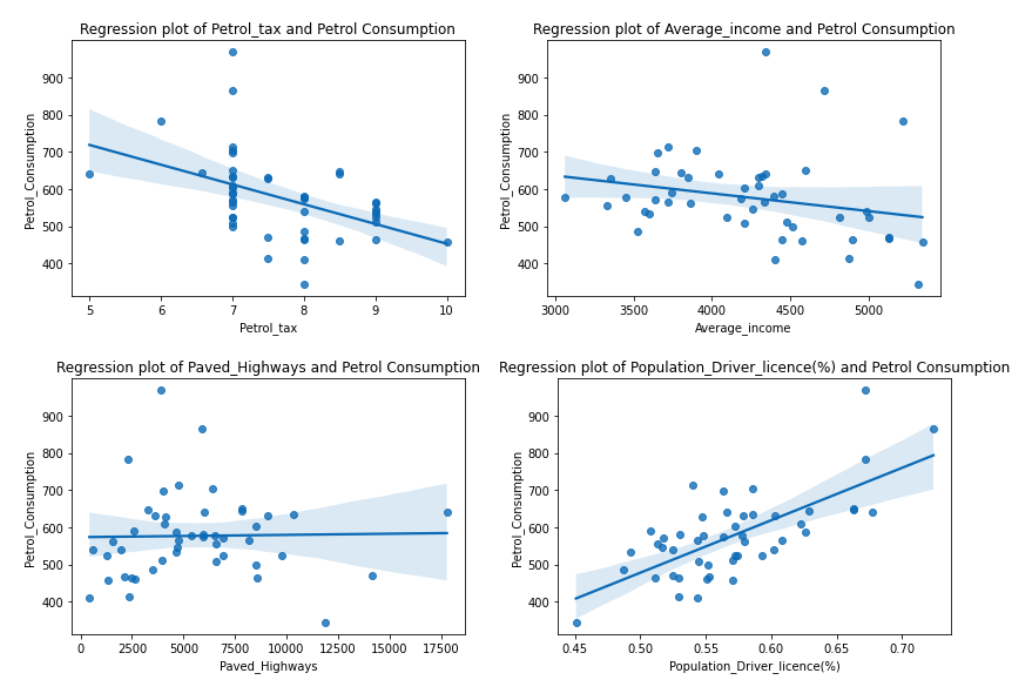
在看回归图时,似乎`Petrol_tax` 和`Average_income` 与`Petrol_Consumption` 有弱的负线性关系。也似乎`Population_Driver_license(%)` 与`Petrol_Consumption` 有强的正线性关系,而`Paved_Highways` 变量与`Petrol_Consumption` 没有关系。
我们还可以计算新变量的相关性,这次使用Seaborn的`heatmap()` ,以帮助我们发现基于较暖(红色)和较冷(蓝色)色调的最强和较弱的相关性。
```
correlations = df.corr()
# annot=True displays the correlation values
sns.heatmap(correlations, annot=True).set(title='Heatmap of Consumption Data - Pearson Correlations');
```
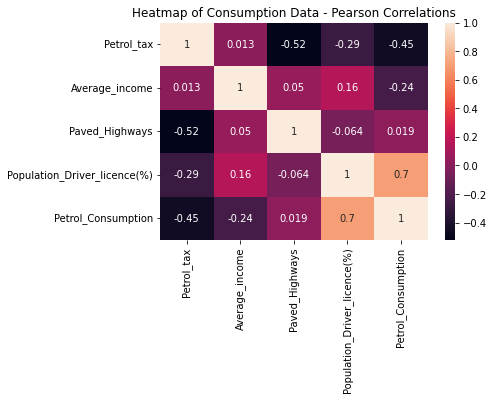
`Petrol_Consumption` `Petrol_Consumption`看来热图证实了我们之前的分析!`Petrol_tax` 和`Average_income` 分别与`-0.45` 和`-0.24` 有弱的负线性关系。`Population_Driver_license(%)` 与`0.7` 有强的正线性关系,而`Paved_Highways` 的相关性是`0.019` - 这表明与`Petrol_Consumption` 没有关系。
> 相关性并不意味着因果关系,但如果我们能用回归模型成功地解释这些现象,我们可能会发现因果关系。
在回归图中需要注意的另一件重要事情是,有一些点与大多数点集中的地方相距甚远,在平均数和std列之间的巨大差异之后,我们已经预料到了这样的事情--这些点可能是数据**离群**值和**极端值**。

**注意:**离群值和极值有不同的定义。虽然离群值不遵循数据的自然方向,并偏离它的形状--但极端值与其他点处于同一方向,但在该方向上过高或过低,远远偏离图形中的极值。
线性回归模型,无论是单变量还是多变量,在确定回归线的斜率和系数时都会将这些离群值和极端值考虑在内。考虑到已经知道的线性回归公式。
分数=9.68207815*小时+2.82689235
如果我们有一个200小时的离群点,那可能是一个打字错误−−它仍然会被用来计算最后的分数。
score = 9.68207815*200+2.82689235 (
分数 = 1939.24252235
)
仅仅一个离群点就可以使我们的斜率值扩大200倍。多重线性回归的情况也是如此。多元线性回归公式基本上是线性回归公式的延伸,有更多的斜率值。
y = b_0 + b_1 * x_1 + b_2 * x_2 + b_3 * x_3 + /ldots + b_n * x_n
这个公式与我们之前的公式的主要区别是,它描述的是一个∗∗平面∗∗,而不是描述一条直线。我们知道有bn\*xn个系数,而不是只有a\*x。∗∗注意:∗∗在多元线性回归公式的末尾有一个误差,这是预测值和实际值之间的误差−−或称∗∗残差误差∗∗。这个误差通常非常小,所以在大多数公式中被省略了。
y = b_0 + b_1 * x_1 + b_2 * x_2 + b_3 * x_3 + \ldots + b_n * x_n + \epsilon
同样,如果我们有一个17,000的极值,最终会使我们的斜率增大17,000。
y = b_0 + 17,000 * x_1 + b_2 * x_2 + b_3 * x_3 + \ldots + b_n * x_n
> 换句话说,单变量和多变量线性模型对离群值和极端数据值都*很敏感*。

**注意**:这超出了本指南的范围,但你可以通过查看boxplots、处理离群值和极端值,在数据分析和模型的数据准备方面更进一步。
> 如果你想了解更多关于Violin Plots和Box Plots的知识--请阅读我们的[Box Plot](https://stackabuse.com/seaborn-box-plot-tutorial-and-examples/)和[Violin Plot](https://stackabuse.com/seaborn-violin-plot-tutorial-and-examples/)指南!
我们已经学到了很多关于线性模型和探索性数据分析的知识,现在是时候使用`Average_income`,`Paved_Highways`,`Population_Driver_license(%)` 和`Petrol_tax` 作为我们模型的独立变量,看看会发生什么。
#### 准备数据
按照简单线性回归的做法,在加载和探索数据后,我们可以将其分为特征和目标。主要的区别是,现在我们的特征有4列,而不是一列。
我们可以使用双括号`[[ ]]` ,从数据框架中选择它们。
```
y = df['Petrol_Consumption']
X = df[['Average_income', 'Paved_Highways',
'Population_Driver_licence(%)', 'Petrol_tax']]
```
在设置了我们的`X` 和`y` 集之后,我们可以将我们的数据分为训练集和测试集。我们将使用相同的种子和20%的数据进行训练。
```
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=SEED)
```
#### 训练多变量模型
分割数据后,我们可以训练我们的多元回归模型。请注意,现在不需要重新塑造我们的`X` ,一旦它已经有一个以上的维度。
```
X.shape # (48, 4)
```
为了训练我们的模型,我们可以执行与之前相同的代码,并使用`LinearRegression` 类的`fit()` 方法。
```
regressor = LinearRegression()
regressor.fit(X_train, y_train)
```
拟合模型并找到我们的最佳解决方案后,我们还可以看一下截距。
```
regressor.intercept_
```
```
361.45087906668397
```
以及特征的系数
```
regressor.coef_
```
```
[-5.65355145e-02, -4.38217137e-03, 1.34686930e+03, -3.69937459e+01]
```
这四个值是我们每个特征的系数,其顺序与我们的`X` 数据中的相同。要看一个带有它们名字的列表,我们可以使用数据框架`columns` 属性。
```
feature_names = X.columns
```
这段代码将输出。
```
['Average_income', 'Paved_Highways', 'Population_Driver_licence(%)', 'Petrol_tax']
```
考虑到像这样将特征和系数放在一起看有点困难,我们可以用表格的形式更好地组织它们。
要做到这一点,我们可以将我们的列名分配到一个`feature_names` 变量,将我们的系数分配到一个`model_coefficients` 变量。之后,我们可以创建一个数据框架,将我们的特征作为索引,将我们的系数作为列值,称为`coefficients_df` 。
```
feature_names = X.columns
model_coefficients = regressor.coef_
coefficients_df = pd.DataFrame(data = model_coefficients,
index = feature_names,
columns = ['Coefficient value'])
print(coefficients_df)
```
最后的`DataFrame` 应该是这样的。
```
Coefficient value
Average_income -0.056536
Paved_Highways -0.004382
Population_Driver_licence(%) 1346.869298
Petrol_tax -36.993746
```
如果在线性回归模型中,我们有一个变量和一个系数,现在在多元线性回归模型中,我们有4个变量和4个系数。这些系数能代表什么?按照线性回归系数的相同解释,这意味着平均收入增加一个单位,天然气消费就会减少0.06美元。
同样,铺设的公路增加一个单位,天然气消费的里程数就会减少0.004;拥有驾驶执照的人口比例增加一个单位,天然气消费就会增加13.46亿加仑。
最后,汽油税增加一个单位,汽油消费就会减少369.93亿加仑。
通过查看系数数据框架,我们还可以看到,根据我们的模型,`Average_income` 和`Paved_Highways` 的特征是比较接近于 0 的,这意味着它们对天然气消费的**影响最小**。而`Population_Driver_license(%)` 和`Petrol_tax` ,其系数分别为1346.86和-36.99,对我们的目标预测**影响最大**。
换句话说,汽油消耗量主要是由拥有驾驶执照的人口比例和汽油税额来**解释**的,这足以令人惊讶(或不令人惊讶)。
我们可以看到这个结果与我们在相关热图中看到的有关联。驾照百分比具有最强的相关性,所以预计它可以帮助解释汽油消费,而汽油税具有微弱的负相关性--但是,当与同样具有微弱负相关性的平均收入相比较时,是最接近-1的负相关性,最终解释了模型。
当所有的数值被添加到多元回归公式中时,铺设的高速公路和平均收入的斜率最终变得更接近于0,而驾驶执照百分比和税收收入则离0更远。

**注意:**在数据科学中,我们主要处理的是假设和不确定性。没有100%的确定性,总是有误差的。*如果你有0个错误或100%的分数,就要怀疑了。*我们只用一个数据样本训练了一个模型,假设我们有一个最终结果还为时过早。为了更进一步,你可以进行残差分析,使用**交叉验证**技术用不同的样本训练模型。你还可以获得更多的数据和更多的变量来探索和插入模型来比较结果。
到目前为止,我们的分析似乎是有意义的。现在是时候确定我们目前的模型是否容易出错。
#### 用多变量回归模型进行预测
为了了解我们的模型是否犯错以及如何犯错,我们可以使用我们的测试数据预测气体消耗量,然后查看我们的指标,以便能够知道我们的模型表现得如何。
按照我们对简单回归模型所做的同样方法,让我们用测试数据进行预测。
```
y_pred = regressor.predict(X_test)
```
`X_test` 现在,我们有了我们的测试预测,我们可以通过把它们整理成`DataFrame`,更好地与实际的输出值进行比较。
```
results = pd.DataFrame({'Actual': y_test, 'Predicted': y_pred})
print(results)
```
输出应该是这样的。
```
Actual Predicted
27 631 606.692665
40 587 673.779442
26 577 584.991490
43 591 563.536910
24 460 519.058672
37 704 643.461003
12 525 572.897614
19 640 687.077036
4 410 547.609366
25 566 530.037630
```
这里,我们有每个测试数据的行的索引,一列是其实际值,另一列是其预测值。当我们看实际值和预测值之间的差异时,如631和607之间,是24,或587和674之间,是-87,似乎两个值之间有一些距离,但这个距离是否太大了?
#### 评估多变量模型
在探索、训练和查看我们的模型预测之后,我们的最后一步是评估我们的多元线性回归的性能。我们想了解我们的预测值是否与我们的实际值相差太远。我们将用之前的方法来做,通过计算MAE、MSE和RMSE指标。
因此,让我们执行以下代码。
```
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
print(f'Mean absolute error: {mae:.2f}')
print(f'Mean squared error: {mse:.2f}')
print(f'Root mean squared error: {rmse:.2f}')
```
我们指标的输出应该是。
```
Mean absolute error: 53.47
Mean squared error: 4083.26
Root mean squared error: 63.90
```
我们可以看到,RMSE的值是63.90,这意味着我们的模型可能会在实际值的基础上增加或减少63.90,从而使其预测出错。这个误差最好能接近0,而63.90是一个很大的数字--这表明我们的模型可能预测得不是很好。
我们的MAE也离0很远。与之前的简单回归相比,我们可以看到幅度上的显著差异,在那里我们有一个更好的结果。
为了进一步了解我们的模型发生了什么,我们可以看一下以不同方式衡量模型的指标,它不考虑我们的个别数据值,如MSE、RMSE和MAE,而是采取一种更普遍的方法来衡量误差,即R2。
R^2 = 1 - frac{\sum(Actual - Predicted)^2}{sum(Actual - Actual Mean)^2}
R2并不告诉我们每个预测值离真实数据有多远或多近--它告诉我们,我们的目标有多少被我们的模型所捕获。
> 换句话说,R2量化了因变量的方差有多少被模型所解释。
R2指标从0%到100%不等。越接近100%,就越好。如果R2值为负数,意味着它根本不能解释目标。
我们可以在Python中计算R2,以更好地了解它的工作原理。
```
actual_minus_predicted = sum((y_test - y_pred)**2)
actual_minus_actual_mean = sum((y_test - y_test.mean())**2)
r2 = 1 - actual_minus_predicted/actual_minus_actual_mean
print('R²:', r2)
```
```
R²: 0.39136640014305457
```
R2也默认实现在Scikit-Learn的线性回归器类的`score` 方法中。我们可以这样来计算它。
```
regressor.score(X_test, y_test)
```
这样的结果是。
```
0.39136640014305457
```
到目前为止,我们目前的模型似乎只能解释39%的测试数据,这不是一个好结果,这意味着它留下了61%的测试数据没有被解释。
我们也来了解一下我们的模型对训练数据的解释程度。
```
regressor.score(X_train, y_train)
```
哪些输出。
```
0.7068781342155135
```
我们发现我们的模型有一个问题。它解释了70%的训练数据,但只解释了39%的测试数据,这比训练数据更重要。它对训练数据的拟合非常好,而对测试数据却无法拟合--这意味着,我们有一个**过度拟合的**多元线性回归模型。
有很多因素可能导致了这一点,其中有几个因素可能是。
1. 需要更多的数据:我们只有一年的数据(而且只有48行),这并不算多,而如果有多年的数据,可能对改善预测结果有相当大的帮助。
2. 克服过度拟合:我们可以使用交叉验证,将我们的模型拟合到数据集的不同洗牌样本上,试图结束过度拟合。
3. 假设不成立:我们做了一个假设,即数据具有线性关系,但情况可能并非如此。使用boxplots对数据进行可视化,了解数据分布,处理异常值,并对其进行归一化处理,这可能有助于解决这个问题。
4. 可怜的特征:我们可能需要其他或更多的特征,与我们试图预测的数值有最强的关系。
### 总结
在这篇文章中,我们研究了最基本的机器学习算法之一,即线性回归。我们在Scikit-learn机器学习库的帮助下实现了简单线性回归和多元线性回归。


