对于Python编程语言,Pandas是一个高效和流行的数据分析工具,特别是它的Dataframe,用于操作和显示数据。对于.NET编程语言,我们可以使用NuGet中的Deedle或Microsoft.Data.Analysis包,它也提供了一个用于操作、转换和显示数据的DataFrame类。
这个例子着重于Microsoft.Data.Analysis包,展示了Jupyter Notebook中DataFrame类的一些基本功能。
它还使用了XPlot.Plotly包,它是F#数据可视化包,为Dataframe中的数据绘制图表。源代码可在GitHub上找到。
前提条件
要运行本文中的例子,请参考这篇在Jupyter Notebook中使用.NET Core的文章,以设置Jupyter Notebook来支持.NET编程语言。
安装软件包
Microsoft.Data.Analysis包在Nuget中可用,因此可以使用dotnet-interactive**#r** magic命令从NuGet中安装该包。
运行下面的命令来安装Microsoft.Data.Analysis软件包0.4.0版本。
#r "nuget:Microsoft.available Data.Analysis,0.4.0"
参考命名空间
本文使用了以下四个包的类。因此,它使用using语句来引用这些包:
- XPlot.Plotly。一个用于F#和.NET编程语言的跨平台数据可视化包
- Microsoft.Data.Analysis。一个易于使用和高性能的数据分析和转换库
- System.Linq:支持使用语言集成查询的类和接口。
- Microsoft.AspNetCore.Html:用于操作HTML内容的类型
using XPlot.Plotly;
using Microsoft.Data.Analysis;
using System.Linq;
using Microsoft.AspNetCore.Html;
将一个DataFrame渲染成一个HTML表
默认情况下,一个DataFrame被渲染成一个有一行和两列的HTML表(Columns and Rows)。

这可以通过为DataFrame注册自定义格式器来重写。下面的代码为Dataframe和DataFrameRow注册了自定义格式器,以在HTML表格中呈现数据。
它只显示前100行。这可以通过修改take变量的值来改变。
Formatter<DataFrame>.Register((df, writer) =>
{
var headers = new List<IHtmlContent>();
headers.Add(th(i("index")));
headers.AddRange(df.Columns.Select(c => (IHtmlContent) th(c.Name)));
var rows = new List<List<IHtmlContent>>();
var take = 100;
for (var i = 0; i < Math.Min(take, df.Rows.Count); i++)
{
var cells = new List<IHtmlContent>();
cells.Add(td(i));
foreach (var obj in df.Rows[i])
{
cells.Add(td(obj));
}
rows.Add(cells);
}
var t = table(
thead(
headers),
tbody(
rows.Select(
r => tr(r))));
writer.Write(t);
writer.Write(df.Rows.Count + " x "+df.Columns.Count);
}, "text/html");
Formatter<DataFrameRow>.Register((dataFrameRow, writer) =>
{
var cells = new List<IHtmlContent>();
cells.Add(td(i));
foreach (var obj in dataFrameRow)
{
cells.Add(td(obj));
}
var t = table(
tbody(
cells));
writer.Write(t);
}, "text/html");
创建DataFrame
数据框架列(DataFrameColumn
通过将DataFrameColumn对象的列表传递给DataFrame的构造函数,就可以创建一个DataFrame。
public DataFrame(params DataFrameColumn[] columns);
public DataFrame(IEnumerable columns);
下面的代码创建了一个有200行和2列的DataFrame。第一列包含日期,第二列包含随机整数。它调用PrimitiveDataFrameColumn构造函数来创建DataFrameColumn实例。
var start = new DateTime(2009,1,1);
Random rand = new Random();
var numDataPoint = 200;
PrimitiveDataFrameColumn<DateTime> date = new PrimitiveDataFrameColumn<DateTime>("Date",
Enumerable.Range(0, numDataPoint)
.Select(offset => start.AddDays(offset))
.ToList());
PrimitiveDataFrameColumn<int> data = new PrimitiveDataFrameColumn<int>("Data",
Enumerable.Range(0, numDataPoint)
.Select(r => rand.Next(100))
.ToList());
var df = new DataFrame(date, data);
df

CSV文件
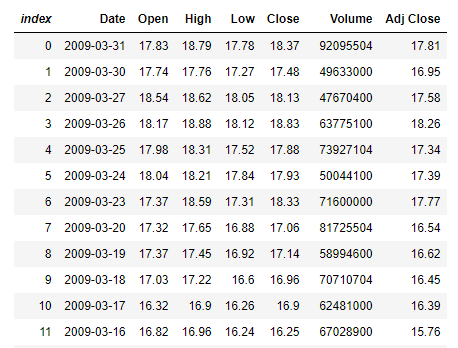
DataFrame也可以通过调用DataFrame.LoadCsv静态方法从CSV文件创建。
下面的代码从ohcldata.csv文件创建一个DataFrame。这个文件是从5.30下载的。例子--基本OHLC(开盘价、最高价、最低价、收盘价)金融图谱网站。这个文件包含每天的开盘价、最高价、最低价、收盘价的金融数据。
var df1 = DataFrame.LoadCsv("ohlcdata.csv");
df1

然后,可以使用Info方法来生成DataFrame中每一列的摘要。

访问DataFrame
通过索引访问数据
可以使用行索引和列索引来访问DataFrame中的具体数据。索引是基于零的编号。
下面的代码访问第一行和第二列的数据。
![Out[7]: 11; First Row, Second Column](https://dzone.com/storage/temp/14769905-result4.png)
之后,可以给DataFrame分配一个新的值。
下面的代码将第一行和第二列的数据增加了10。
df[0,1] = int.Parse(df[0,1].ToString()) + 10;
df.Head(10)
![Out[8]: Chart; Increase Data by 10](https://dzone.com/storage/temp/14769908-result5.png)
访问行数据
可以通过使用行索引来访问整个行。该索引是基于零的编号。
下面的代码访问了DataFrame中的第10行。

列索引也可以用来访问该行中的特定列。
下面的代码访问了第十行中的第四列。
然后,新的值也可以被分配给该列。
下面的代码将50000000分配给了第六列。
df1.Rows[9][5] = 50000000f;
df1.Head(10)
![Out[11]: Chart; Access Row Data](https://dzone.com/storage/temp/14769988-result8.png)
访问列的数据
可以通过使用列名或索引来访问整个列。索引是基于零的编号。
下面的代码访问了DataFrame中名为Data的列(第二列)。
//df.Columns["Data"] or df.Columns[1]
df.Columns["Data"]
![Out[12]: Chart; Access Column Data](https://dzone.com/storage/temp/14769990-result9.png)
该列中的数据可以通过使用DataFrame的重载操作符来改变。
下面的代码将该列中的所有数据增加10。
df.Columns["Data"]= df.Columns["Data"]+10;
df
![Out[13]: Chart; Increase All Data By 10](https://dzone.com/storage/temp/14769994-result10.png)
插入数据
添加一个新列
DataFrame在DataFrameColumnCollection中维护了一个DataFrameColumns的列表。可以向DataFrameColumnCollection添加一个新的列。
下面的代码向DataFrame添加了一个新的整数列。
df.Columns.Add(new PrimitiveDataFrameColumn<int>("Data1", df.Rows.Count()));
df
![Out [14]: Chart; Add a New Column](https://dzone.com/storage/temp/14769997-result11.png)
新列中的数据被设置为null。
下面的代码将新列(Data1)中的空值填充为10。
df.Columns["Data1"].FillNulls(10, true);
df
![Out[15]: Chart; Fill Null Values](https://dzone.com/storage/temp/14769999-result12.png)
附加一个新行
Append方法可以用来向DataFrame追加新行。
下面的代码创建了一个KeyValuePair实例的列表,然后将其添加到DataFrame中。
df.Append(new List<KeyValuePair<string, object>>() {
new KeyValuePair<string, object>("Date", DateTime.Now),
new KeyValuePair<string, object>("Data", 12),
new KeyValuePair<string, object>("Data1", 50)
}, true);
df.Tail(10)
![Out [16]: Chart; Append a New Row](https://dzone.com/storage/temp/14770002-result13.png)
操纵数据框架
对数据框架进行排序
OrderBy或OrderByDescending方法可用于按指定列对DataFrame进行排序。
下面的代码按照名为Data的列对DataFrame进行排序。
![Out [17]:Chart; Sort DataFrame](https://dzone.com/storage/temp/14770005-result14.png)
对DataFrame进行分组
GroupBy方法可用于按列中的唯一值对DataFrame的行进行分组。
下面的代码通过名为Data的列对DataFrame进行分组,然后计算每组中的值的数量。
var groupByData = df.GroupBy("Data");
groupByData.Count().OrderBy("Data")
![Out[18]: Chart; Group the DataFrame](https://dzone.com/storage/temp/14770010-result15.png)
过滤DataFrame
过滤器方法可以用来通过行索引或布尔值来过滤DataFrame。
下面的代码通过返回那些在名为Data的列中的值大于50的行来过滤DataFrame。
df.Filter(df.Columns["Data"].ElementwiseGreaterThan(50))
![Out[19]: Chart; Filter the DataFrame](https://dzone.com/storage/temp/14770011-result16.png)
合并DataFrame
Merge方法可以用来以数据库式的连接方式合并两个DataFrames。
下面的代码通过使用两个DataFrame中包含的Date列来连接两个DataFrame。首先,它将df1的Date列中的数据类型从字符串类型转换为DataTime类型。然后,它调用Merge方法来连接DataFrames。
df1.Columns["Date"] = new PrimitiveDataFrameColumn<DateTime>("Date",
df1.Columns["Date"]
.Cast<object>()
.ToList()
.Select(x => DateTime.ParseExact(x.ToString(), "yyyy-MM-dd", System.Globalization.CultureInfo.InvariantCulture))
.Cast<DateTime>());
df1.Merge<DateTime>(df, "Date", "Date")
![Out[20]: Chart; Merge the DataFrame](https://dzone.com/storage/temp/14770017-result17.png)
通过使用XPlot.Ploty绘制图表
XPlot.Ploty是一个用于F#和.NET编程语言的跨平台数据可视化包。它的基础是Plotly,它是流行的JavaScript图表库。
下面的例子演示了如何使用XPlot.Ploty通过使用DataFrame中的数据来绘制图表。
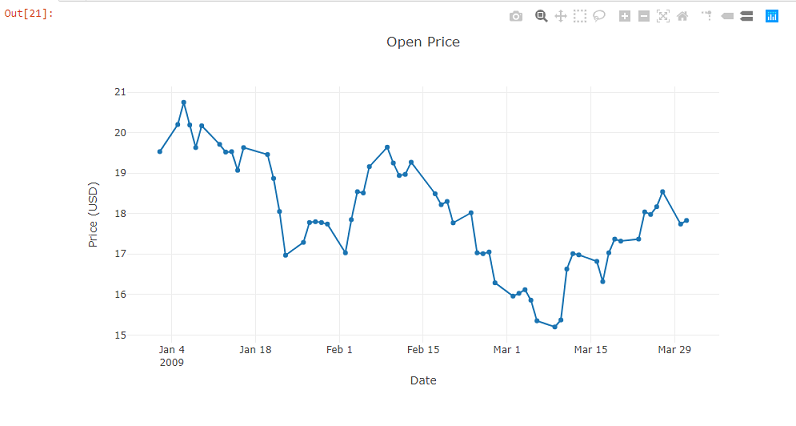
线形图
下面的代码从DataFrame中的Open列绘制了一个线形图。
var chart1 = Chart.Plot(
new Graph.Scatter
{
x = df1.Columns["Date"],
y = df1.Columns["Open"],
mode = "lines+markers"
}
);
var chart1_layout = new Layout.Layout{
title="Open Price",
xaxis =new Graph.Xaxis{
title = "Date"
},
yaxis =new Graph.Yaxis{
title = "Price (USD)"
}
};
chart1.WithLayout(chart1_layout);
chart1
有多条线的折线图
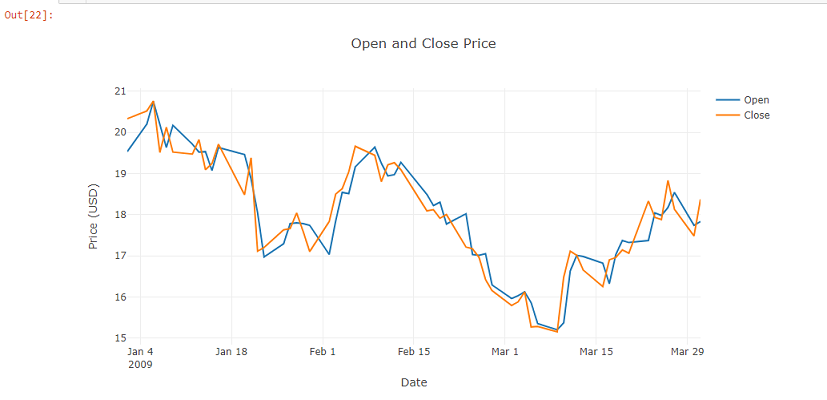
下面的代码在一个折线图中绘制了开盘列和收盘列。
var chart2_list = new List<Graph.Scatter>
{
new Graph.Scatter
{
x = df1.Columns["Date"],
y = df1.Columns["Open"],
name="Open",
mode = "lines"
},
new Graph.Scatter
{
x = df1.Columns["Date"],
y = df1.Columns["Close"],
name="Close",
mode = "lines"
}
};
var chart2 = Chart.Plot(
chart2_list
);
var chart2_layout = new Layout.Layout{
title="Open and Close Price",
xaxis =new Graph.Xaxis{
title = "Date"
},
yaxis =new Graph.Yaxis{
title = "Price (USD)"
}
};
chart2.WithLayout(chart2_layout);
chart2
柱状图
下面的代码从DataFrame中的Volume列绘制了一个条形图。
var chart3 = Chart.Plot(
new Graph.Bar
{
x = df1.Columns["Date"],
y = df1.Columns["Volume"],
marker = new Graph.Marker{color = "rgb(0, 0, 109)"}
}
);
var chart3_layout = new Layout.Layout{
title="Volume",
xaxis =new Graph.Xaxis{
title = "Date"
},
yaxis =new Graph.Yaxis{
title = "Unit"
}
};
chart3.WithLayout(chart3_layout);
chart3

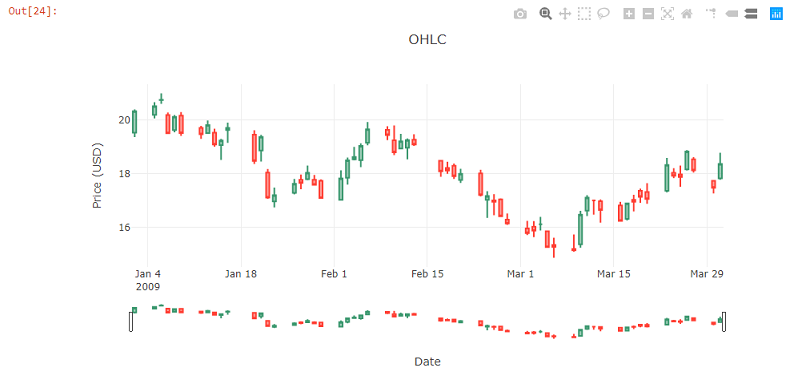
烛台图
下面的代码从DataFrame中的Open,High,Low,Close列绘制了一个蜡烛图。
var chart4 = Chart.Candlestick(df1.OrderBy("Date").Rows.Select(row => new Tuple<string, double, double, double, double>(
((DateTime)row[0]).ToString("yyyy-MM-dd"),
double.Parse(row[1].ToString()),
double.Parse(row[2].ToString()),
double.Parse(row[3].ToString()),
double.Parse(row[4].ToString())
)));
chart4.WithLayout(new Layout.Layout{
title="OHLC",
xaxis =new Graph.Xaxis{
title = "Date"
},
yaxis =new Graph.Yaxis{
title = "Price (USD)"
}
});
chart4