

如何将Redshift连接到Marketo?2个简单的方法
在今天的数字环境中,一切都可以在线访问和管理。由于这个过程中产生的数据量很大,很难进行实时分析,发展洞察力,识别欺诈和异常,提醒用户,以及执行其他职责。
Marketo 是一个营销自动化平台,通过融合行为数据和内置智能,为你的团队提高线索和客户参与度。这些计算机化的营销技术可以帮助公司将消费者的满意度转化为销售。
AWS(亚马逊网络服务)提供亚马逊Redshift,一个PB级的、完全管理的数据仓库,以协助企业存储和分析他们的数据。数据查询的快速响应时间使亚马逊Redshift数据仓库与众不同。为了迅速提供查询答复,它利用了列式数据存储和大规模并行处理(MPP)等方法。
这篇博文旨在讨论营销传播平台Marketo和云托管的数据仓库Redshift。你还会知道如何将 Redshift连接 到Marketo。
目录
什么是Redshift?
![]()
亚马逊Redshift创建于2012年,是一个很受欢迎的、完全可扩展的、可靠的数据仓库。通过一个被称为亚马逊集群的节点集合,企业可以开始使用亚马逊Redshift。Redshift控制台或亚马逊命令行界面可用于管理亚马逊集群。亚马逊Redshift中包含的面向列的数据库使企业能够通过连接基于SQL的客户端(如BI工具)快速分析数据。企业不必担心内存管理、资源分配、配置管理等管理职责,因为Amazon Redshift是一个完全可扩展的数据仓库。
企业可以使用AWS软件开发工具包或亚马逊Redshift查询API,用亚马逊Redshift以编程方式管理集群。
Redshift的主要特点
- 强大的安全性。 用户可以使用Amazon Redshift确保数据仓库的安全,不需要额外的费用。亚马逊Redshift的用户可以设置防火墙来规范对特定数据仓库集群的网络访问。为了确保只有获得授权的人才能查看数据,Amazon Redshift的用户可以训练列级和行级安全控制。
- 结果缓存:对于重复查询,Amazon Redshift的结果缓存功能可以提供亚秒级的响应时间。在Amazon Redshift中,一个查询可以通过搜索缓存来获得早期查询的任何搜索结果。
- 快速的性能。由于其独特的功能,包括大规模并行处理、列式数据存储、结果缓存、查询优化器、数据压缩、生成代码等,Amazon Redshift提供了快速的性能。
- **ANSI-SQL。**您可以利用您当前的SQL客户端和商业智能工具,因为Amazon Redshift是基于ANSI-SQL的,它采用了行业标准的ODBC和JDBC连接。通过ANSI-SQL,您可以轻松查询CSV、JSON、ORC、Avro、Parquet等文件。
- **AQUA(高级查询加速器)。**AQUA是一个分布式的、硬件加速的缓存,是Amazon Redshift的一部分。与竞争对手的企业云数据仓库相比,Amazon Redshift的速度是10倍。
什么是Marketo?
对于跟踪和管理营销过程,Marketo 是一个很受欢迎的SaaS工具。它提供与营销有关的各种服务。Marketo是全球领先的商业解决方案,将规模和复杂程序放在首位。它采用模块化设计,每个模块独立销售和使用。为了提供全面的营销自动化体验,这些模块可以单独或捆绑使用。 电子邮件营销、线索管理、收入归属、基于客户的营销、基于账户的营销等是Marketo提供的一些模块。
客户关系管理(CRM)是Marketo本身不具备的功能,但它可以通过Salesforce、Microsoft Dynamics和SAP等知名CRM进行互动。Marketo的工具使其能够在各种渠道(包括电子邮件、网络、移动设备和其他渠道)自动进行数字广告的几个阶段。因此,可以实时发现、开发和观察线索。
Marketo的主要特点
Marketo提供了一系列的服务,可以帮助企业和个人增加收入和客户满意度。Marketo具有很多值得注意的特点,例如。
- 基于账户的营销(ABM)。 这项技术使企业能够确定他们想要的目标人物,开发一个描述这些人物的智能字符列表,增强这些信息的网站体验,并通过多种渠道(包括电子邮件、网络广告和网站)吸引这些信息。
- **用于SEO的工具。**成功营销的最关键因素之一是搜索引擎优化。为了帮助您提高营销标准,Marketo在一个地方整合了许多SEO工具。
- **A/B测试。**Marketo提供电子邮件测试等服务,协助您选择在电子邮件中投放的内容和发送的最佳时间,以提高转换率。
- **潜在客户培养。**Marketo让企业能够根据营销角色、目标行业或其互动的性质,将他们的线索分成若干组。此外,它使你能够加强与客户的联系,提高转换率。
- 参与引擎: 你可以进行研究,了解你的消费者的行为,并为他们开发可适应的、特定行业的电子邮件活动。
将Redshift连接到Marketo的好处
Marketo是一个营销自动化工具,它结合了行为数据和内置的智能,为你的团队提高线索和客户参与度。这些自动化营销策略可以协助企业将客户满意度转化为销售额。
- 通过整合Redshift和Marketo,你可以快速同步所有关于你的潜在线索的重要信息。你可以立即将你的联系人与你的线索和潜在客户的更具体数据结合起来,这将有助于提高你的营销活动的有效性。
- 利用你的线索信息,你可以在Redshift中快速运行SQL查询,并将结果反馈给你的Marketo订户信息。除了节省你的时间,这样做还会大大增加你的生产力。
- 由于Redshift是你的单一真实来源,你的组织的所有数据将被保存在一个地方。此外,你不需要在每次希望输入Marketo数据时创建全新的数据库或表格。相反,你可以对你保存在Redshift中的汇总数据运行查询,以删除那些实际上不需要的数据。同时,可以用Marketo来加载这些数据。
连接Redshift和Marketo的方法
方法1:使用Hevo Activate将Redshift连接到Marketo
Hevo Activate提供了一个无忧无虑的解决方案,帮助你直接将数据从**Amazon Redshift、Snowflake、Google BigQuery、Facebook等转移到Marketo**、Intercom、Google Sheets、Salesforce、HubSpot、Zendesk等,无需任何干预的方式。Hevo Activate是完全管理和完全自动化的过程,不仅从你想要的来源加载数据,而且还丰富了数据,并将其转化为可分析的形式,而无需编写一行代码。
Hevo与Redshift和CRM Sources的预建集成将完全负责数据传输过程,让你专注于关键业务活动。Hevo还提供 Marketo和Redshift作为一个Destination,以便将数据无缝加载到它。
方法2:使用CSV文件手动连接Redshift和Marketo
这种方法实施起来很费时,而且有些繁琐。你必须首先以CSV格式从RedShift手动导出数据,然后再次使用CSV文件将数据导入Marketo。
连接Redshift和Marketo的方法
方法1:使用Hevo Activate将Redshift连接到Marketo
Hevo Activate帮助你直接将数据从**Redshift、Snowflake等以及其他各种来源转移到CRM,如Marketo**、Intercom、HubSpot、各种SaaS应用等,完全无忧无虑,自动化程度高,免费。
Hevo Activate处理你所有的数据准备要求,让你专注于基本的业务操作,并对如何创造更多的线索,保持客户,并将你的公司推向新的盈利高度有更强大的理解。 它为实时管理数据提供了一个一致的解决方案,并确保你在你的首选目的地始终拥有可供分析的数据。
看看是什么让Hevo Activate如此特别。
- 实时数据同步:凭借其与多个数据源的良好整合,Hevo Activate使你能够快速有效地传输数据。这保证了两端的带宽得到有效利用。
- 数据转换:它提供了一个直接的界面来完善,改变和充实你希望传输的数据。
- 安全:Hevo Activate具有容错设计,确保数据得到安全和稳定的处理,没有数据损失。
- 海量的连接器:Hevo Activate有大量的连接,允许你从各种数据仓库带来的数据,并以整合和分析的格式加载到营销和SaaS应用程序,如Salesforce, HubSpot, Zendesk, Intercom等。
- 简单性:使用Hevo Activate是简单和直接的,保证你的数据在几秒钟内被导出。
- 完全的管理平台:Hevo Activate是一个完全管理的平台。你不需要花时间或精力去维护或监控代码执行中需要的基础设施。
- 实时协助:Hevo Activate团队每周7天,每天24小时都可以通过聊天、电子邮件和支持电话为客户提供出色的支持。
使用Hevo Activate将Marketo连接到Redshift的步骤。
第1步:将Redshift配置为您的仓库
- 步骤1.1:在资产调色板中,点击ACTIVATE,然后: 在ACTIVATIONS标签中选择+CREATE ACTIVATION 。

- 在 "选择仓库 "页面点击**+"添加仓库"(ADD WAREHOUSE)

-
从选择仓库类型页面的下拉菜单中选择 Redshift。
-
第1.2步:在资产调色板中,点击DESTINATIONS,然后。
- 在 目的地列表视图中,点击**+ CREATE**。
- 在 " 添加目的地"页面上选择Redshift 作为目的地类型。
-
第1.3步:在 Configure your Redshift Warehouse页面上设置以下参数。仓库名称、账户名称、区域、数据库用户、数据库密码、数据库名称、模式名称和仓库。
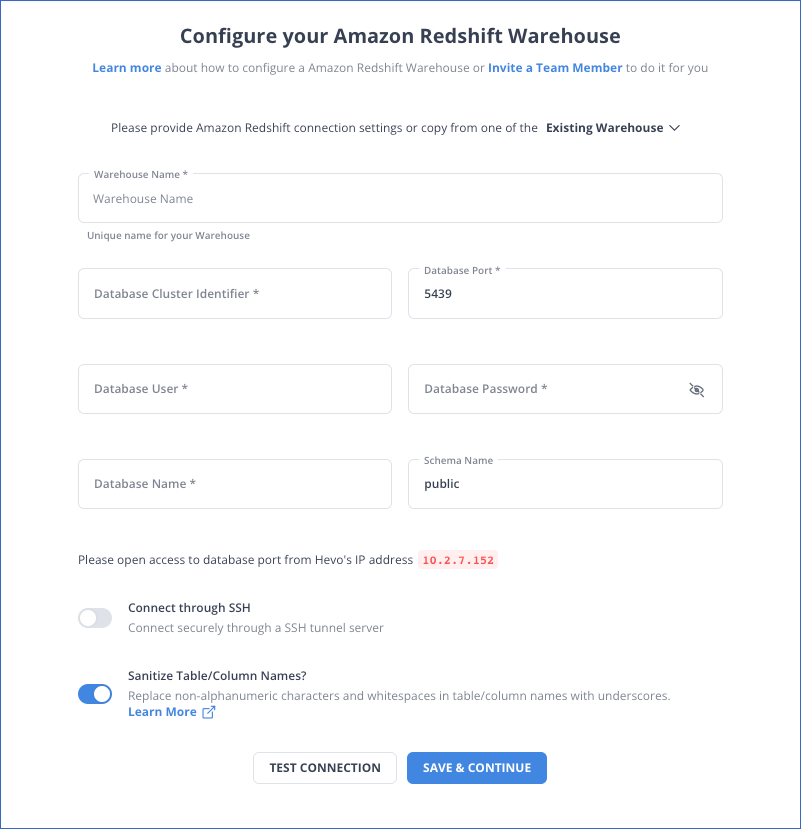
- 步骤1.4:要测试与Redshift仓库的连接,请点击TEST CONNECTION。
- 第1.5步:当测试成功完成后,点击SAVE & CONTINUE。
第2步:将Marketo配置为你的目标目的地
要将Marketo设置为你的目标目的地,你可以按照下面的简单步骤进行。

- 在激活列表视图中选择ACTIVATIONS 标签,并点击 +CREATE ACTIVATION。

- 在选择仓库页面,选择你的激活仓库,或者点击+ ADD WAREHOUSE来添加一个新仓库。阅读 "激活仓库",配置所选仓库类型。
- 在 "选择目标"页面,点击"+ ADD TARGET"。
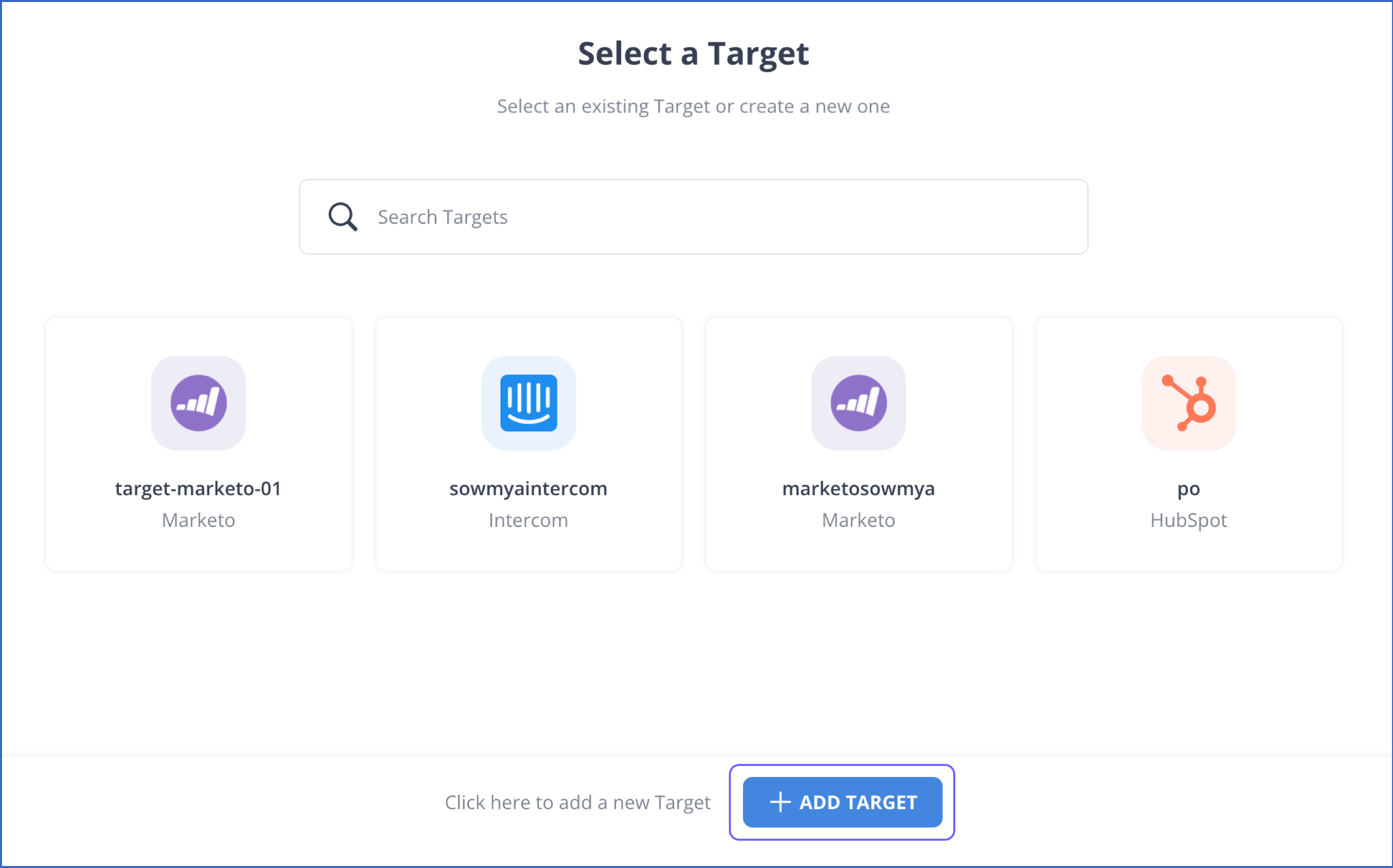
- 第1.3步: 在选择目标类型页面中,点击Marketo。
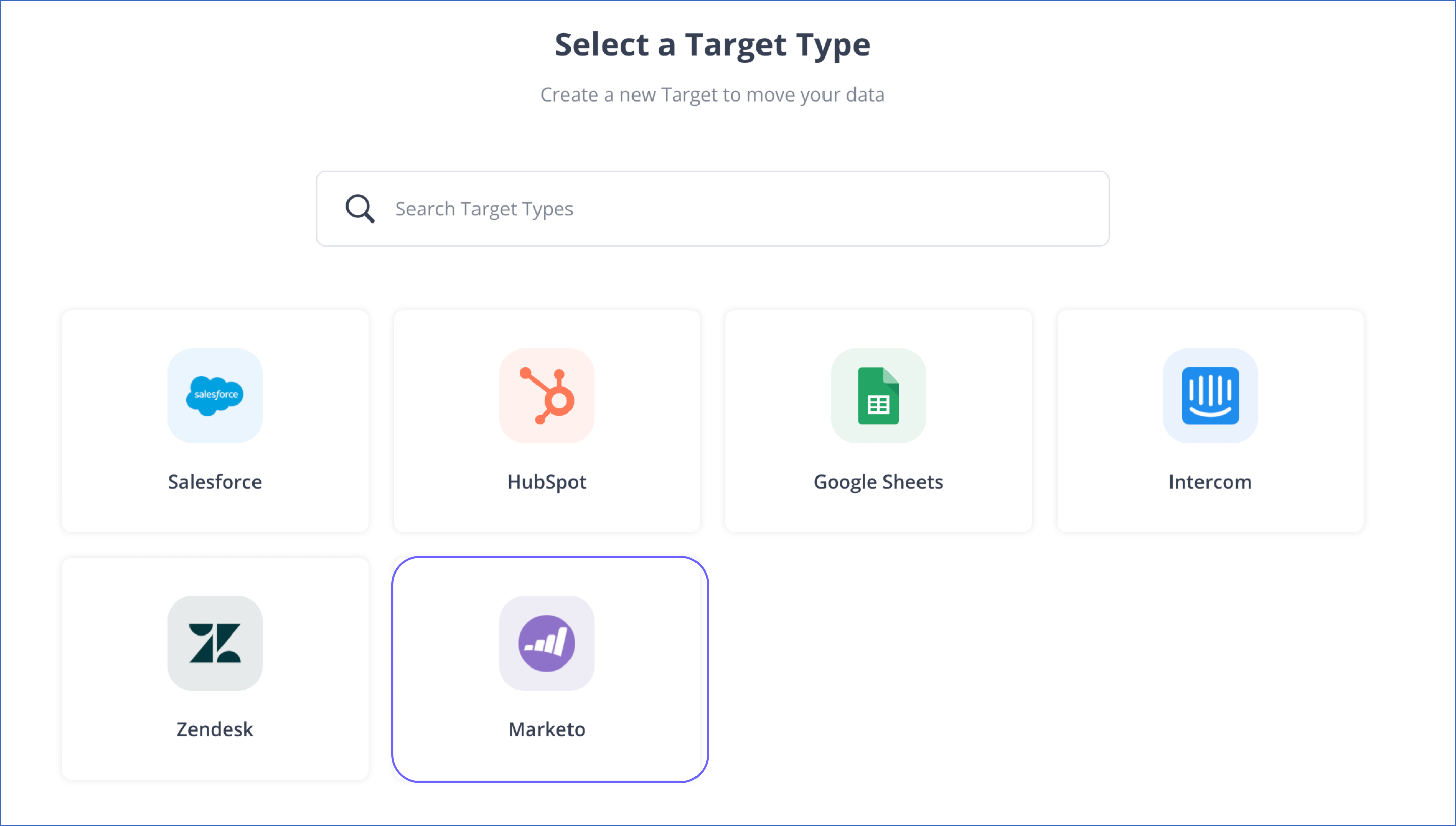
- 第1.4步:在配置你的Marketo目标页面,指定以下信息。
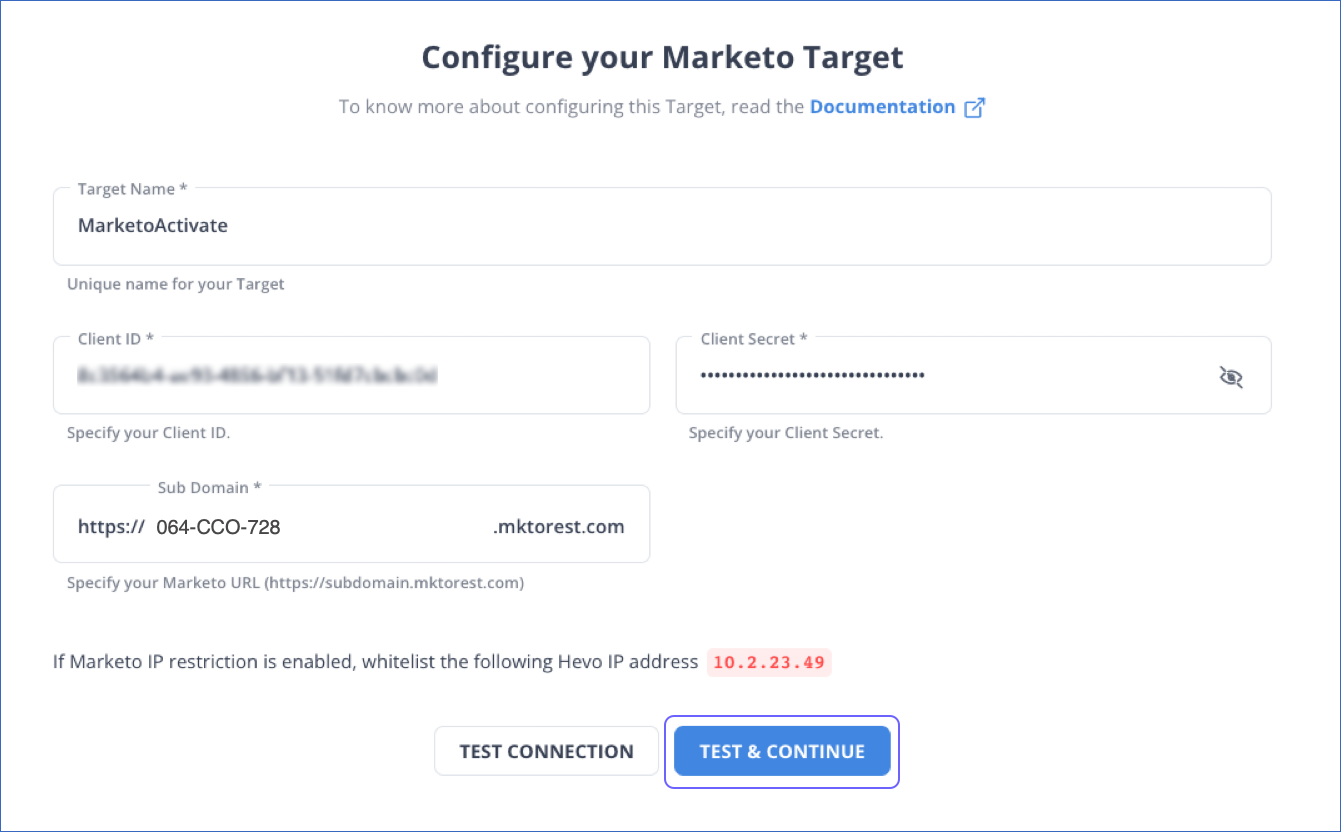
- 第1.5步:点击TEST & CONTINUE。你可以在目标列表视图中查看新的目标。如果您正在创建一个激活,您将返回到 "选择要同步的数据"页面。要完成创建激活,你必须将仓库字段映射到目标字段。请参阅 "Marketo中的字段映射"部分。
方法2:使用CSV文件手动连接Redshift和Marketo
你不能直接将数据从Redshift导出到Marketo。要从Redshift导出数据到Marketo,首先你必须将数据从Redshift导出为CSV文件,然后将CSV文件加载到Marketo。
步骤1:将数据从Redshift导出为CSV文件
将数据从Redshift导出到Marketo的第一步是将数据从Redshift导出为CSV文件。有不同的方法可以做到这一点。
1) 使用UNLOAD命令
通过一些相当直接的SQL,你可以迅速将数据从Redshift导出到CSV。在登录Redshift界面后,可以在左边的菜单中找到编辑按钮。要连接到一个数据库,将鼠标悬停在它上面,然后进入查询编辑器。一旦你连接好了,你就可以开始运行SQL查询。你的数据可以通过以下简单的语法导出。
你在第一行查询你想要导出的数据。Redshift只允许在内部SELECT 语句中使用LIMIT 子句,因此要注意这点。
UNLOAD ('SELECT * FROM your_table')
TO 's3://object-path/name-prefix'
IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>'
CSV;
在第二行看到的TO 子句,是你指定目标S3桶路径的地方。为了能够执行查询,你必须有写权限。
你可以批准的各种方式之一是在第三行,这是你的授权。如果你选择使用上述方法,你可以通过点击导航栏中的账户名称,并在那里找到你的12位数字的账户ID,来访问支持中心。
第四行的最后一条指令是指示Redshift将你的数据保存为CSV,这不是默认的。
你可以通过加入各种其他选项来修改上述查询以满足你的需求。其中有几个特别的选项可能会有帮助。
- HEADER:这将增加你的输出文件顶行(s)的列数。几乎在所有情况下,你都应该采取这个措施。
- **使用DELIMITER作为 "字符"。**逗号是CSV文件的标准字符。逗号在你的数据中可以提供令人惊讶的后果。例如,在这种情况下,你可以使用管道(|)。
- ADDQUOTES。另一个确保数据中的逗号不会带来意想不到的结果的技巧是在每个字段周围添加引号,方法是这样的。
- ZSTD、GZIP或BZIP2:通过使用这些压缩选项之一,你的文件的大小将大大减少,使其更容易通过电子邮件或下载。
2) 使用AWS SDK
AWS的SDK之一,有多种计算机语言,如JavaScript、Python、Node.js 和Ruby,允许你通过编程与服务沟通。在SDK的帮助下,你可以执行SQL查询,将数据存储在代码中的一个变量中,然后你可以将其保存为CSV文件。
在这个例子中,你将使用Python。这个例子应该足以帮助你理解,即使你打算使用不同的语言,你也可以这样做。你必须安装boto3,它是用于Python的AWS SDK。
pip install boto3
安装该库,导入它,然后声明一个客户端。当签入Redshift控制台时,你可以在URL的开头识别区域,你应该使用区域名称,因为这是你的资源已经位于那里。以亚马逊的Redshift V2为例**:us-east-2.console.aws.com/home。
import boto3
client = boto3.client('redshift-data', region_name='us-east-2',
aws_access_key_id='your-public-key', aws_secret_access_key='your-secret-key')
现在你已经准备好运行一个查询来获取你的数据。
response = client.execute_statement(
ClusterIdentifier='your-cluster',
Database='your-database',
DbUser='your-user',
Sql='SELECT * FROM users;' # Insert your SQL query here
)
一个包含你最近一次请求的细节的字典就是响应。你的查询的通用唯一ID,Id,是其中一个键。
{'ClusterIdentifier': 'your-cluster',
'CreatedAt': datetime.datetime(2021, 9, 9, 21, 29, 29, 521000, tzinfo=tzlocal()),
'Database': 'your-database',
'DbUser': 'your-user',
'Id': 'query-id', # You'll need this
'ResponseMetadata': {'RequestId': '4af####-########',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amzn-requestid': '4af####-#######',
'content-type': 'application/x-amz-json-1.1',
'content-length': '150',
'date': 'Thu, 09 Sep 2021 19:29:29 GMT'},
'RetryAttempts': 0}}
{'ClusterIdentifier': 'your-cluster',
'CreatedAt': datetime.datetime(2021, 9, 9, 21, 29, 29, 521000, tzinfo=tzlocal()),
'Database': 'your-database',
'DbUser': 'your-user',
'Id': 'query-id', # You'll need this
'ResponseMetadata': {'RequestId': '4af####-########',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amzn-requestid': '4af####-#######',
'content-type': 'application/x-amz-json-1.1',
'content-length': '150',
'date': 'Thu, 09 Sep 2021 19:29:29 GMT'},
'RetryAttempts': 0}}
{'ClusterIdentifier': 'your-cluster',
'CreatedAt': datetime.datetime(2021, 9, 9, 21, 29, 29, 521000, tzinfo=tzlocal()),
'Database': 'your-database',
'DbUser': 'your-user',
'Id': 'query-id', # You'll need this
'ResponseMetadata': {'RequestId': '4af####-########',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amzn-requestid': '4af####-#######',
'content-type': 'application/x-amz-json-1.1',
'content-length': '150',
'date': 'Thu, 09 Sep 2021 19:29:29 GMT'},
'RetryAttempts': 0}}
query_id = response['Id']
要检查你的查询的当前状态,在description_statement中输入这个查询ID。如果键Status还不等于FINISHED,那么尝试访问你的数据就没有用了。
print(client.describe_statement(Id=query_id)['Status'])
使用get_statement_result 获取信息,并在状态显示你的查询完成后将其保存到一个变量中。
data = client.get_statement_result(Id=query_id)
为了确保你的数据没有丢失,总是仔细检查NextToken 键。你的数据已经被分页了,如果有NextToken,就必须检索更多的数据。
next_token = data['NextToken']
more_data = client.get_statement_result(Id=query_id, NextToken=next_token)
你可能想创建一个for循环来迭代你的数据,并将其全部追加到一个变量中,这取决于你查询了多少数据。假设你现在有了所有的数据,你会发现它是以一种非常笨拙的风格呈现的。这里的方便指的是你不能立即将其转换为pandas DataFrame,至少不是一个有意义的。这里有一个函数可以帮助你完成这个任务。
def redshift_to_dataframe(data):
df_labels = []
for i in data['ColumnMetadata']:
df_labels.append(i['label'])
df_data = []
for i in data['Records']:
object_data = []
for j in i:
object_data.append(list(j.values())[0])
df_data.append(object_data)
df = pd.DataFrame(columns=df_labels, data=df_data)
return df
它为你处理了困难的工作。现在必须调用生成DataFrame并将其保存为CSV的函数。
df = redshift_to_dataframe(data)
df.to_csv('your-file.csv')
之后,你就有了一个具有良好布局的CSV,你可以为你的使用情况加以利用。
3) 使用SQL客户端
最后,你可以在你的本地PC上使用SQL客户端连接到Redshift。只有当你想更频繁地查询Redshift时才会选择这种途径,因为它可能需要一些时间来设置你的工具和连接。有很多程序可以处理这项工作,比如MySQL Workbench。要按的精确按钮和要输入的方向会根据工具的不同而改变,但步骤总是相同的。
- 连接到你想要的数据库。
- 查询数据。
- 将输出结果导出为CSV。
然而,如果你只是有时需要从Redshift导出一个CSV文件,上述方法会更快。
将数据从RedShift转移到Marketo的第一步是将数据导出为CSV文件。
第2步:将CSV数据加载到Marketo中
从RedShift导出数据到Marketo的第二步是将CSV数据导入Marketo。
- 步骤A:可以导入自动报名参加某项计划的个人名单。以下是要做的事情。在电子表格中,创建一个类似于下图的典型CSV 文件。

- 步骤B: 导航到你的计划的成员区。点击导入会员。选择CSV后,点击下一步 。

- 步骤C。将列表中的数据值映射到适当的Marketo字段后,点击下一步。对于你的列表,选择会员状态 为已访问或已参与 ,然后点击导入。

- 步骤D。 在Marketo完成导入后,关闭确认对话。你导入的新会员应该是可见的。

手动连接Redshift和Marketo的局限性
- 数据只能以一种方式从Redshift传送到Marketo。双向同步是必要的,以保持两个工具的更新。
- 因为记录需要经常更新,手动程序需要时间。原本可以用于更重要的业务任务的时间和资源被浪费在这上面了。
- 当需要工程带宽来维持许多平台上的工作流程并更新当前数据时,会让一些消费者感到厌烦。
- 数据传输不允许进行任何转换。那些想在从Redshift转移到Marketo之前修改数据的企业可能会发现这是一个很大的缺点。
总结
在这篇文章中,你已经学会了如何使用2种不同的方法来有效连接Redshift和Marketo。第二种方法是使用CSV文件来连接Redshift和Marketo。
然而,在Redshift、Marketo和你业务中的所有应用程序之间创建和管理多个连接是一项耗时和资源密集的任务。使用第一种方法,你可以选择一种更经济、更轻松的方法,通过 基于云的反向ETL工具(如Hevo Activate)实现工作流程自动化。
