

批量数据很糟糕--它是缓慢的、手动的、麻烦的,而且经常是陈旧的。我们知道,因为我们自己已经处理过这些问题。任何企业都需要跟踪指标,从客户活动到公司的内部运作。但是,我们如何才能保持这些指标的更新,以提取最大的商业价值?
在Cockroach Labs,我们建立了CockroachDB,这是一个分布式的数据库,目的是在任何地方都能生存,并在任何地方都能发展。CockroachDB主要是针对事务性数据--"OLTP"--进行优化,有时将这些数据流向分析仓库以运行频繁的大型查询是非常有利的。这就是我们对 "遥测数据 "的处理方式--我们在内部收集的产品使用数据。
遥测数据是匿名的,只从那些没有选择退出的用户那里收集,帮助我们跟踪功能的使用,并做出产品决策。遥测数据帮助我们决定将分布式备份和恢复转移到CockroachDB核心。它也为我们在蟑螂大学课程中使用CockroachCloud专用集群的免费试用代码提供了依据。我们是一家快速发展的初创公司,拥有最新的数据并方便地提供给利益相关者,是我们为用户做出最佳产品决策的关键。这就是为什么我们从批量上传遥测数据转变为使用变化反馈来流传这些数据。
我们原来的方法。每周cron作业,批量更新,和Snowflake
我们将遥测数据托管在一个内部生产系统中,该系统运行在CockroachCloud,即我们的管理数据库即服务。为了避免每天从多TB大小的表中提取最新的数据而使集群瘫痪,我们以前在本地存储了一个额外的副本,并每周批量上传至Snowflake。
这种方法有很多缺点。首先,它依赖于每周的cron工作或 "嘿Piyush,你能为我更新数据吗?"的提示,以保持数据的更新。这个过程被证明是脆弱的,不可靠的,并且花费了更多的时间和精力。数据也没有像我们希望的那样保持最新。由于对这一过程感到沮丧,我们转向使用我们的本地数据库功能之一,为我们提供更快、更容易和更可靠的数据更新:变化反馈。
使用变化数据捕获(CDC)将数据从CockroachCloud中流出来
CockroachDB的变化数据捕获(CDC)过程观察一个表或一组表,捕捉到任何底层数据的变化,并通过变化反馈发布这些变化。变化反馈以近乎实时的方式将更新的行从数据库中流向外部汇(即Kafka 或云存储)。
例如,我们的产品团队使用表FEATURES来跟踪功能的使用频率。当有一行被添加到记录使用SQL命令INSERT的FEATURES表中时,changefeed会接收到添加的行并将其发送到外部系统。该信息看起来像这样。
{
{
"__crdb__":{
"updated":
},
"feature":"sql.insert.count.internal",
"internal":false,
"node":1,
"timestamp":,
"uptime":2106051,
"uses":100,
"version":"v19.1.2"
}
}
这是一个简单的概念,但允许我们建立强大的应用程序。一个应用程序可以利用CockroachDB的事务性保证,同时确保其他依赖信息的应用程序能够保持近乎实时的更新。变更数据采集可以成为微服务架构的一个关键组成部分;它也可以用来保存可审计的数据日志。
CockroachDB原生的变化反馈允许我们自动地、近乎实时地将数据从CockroachCloud流向云存储汇,然后流向Snowflake。通过使用变化馈送将数据流转到分析工具,我们可以利用专门为内部分析提供的解决方案,同时保持基础数据库的高性能。
转而使用变化馈送为我们的流程增加了稳健性和可靠性:数据流不会因休假、 病假或家庭互联网连接问题而中断。它使我们能够从每周到每天或接近实时的指标,使我们能够更早地诊断出问题。
例如,有两次我们注意到,由于CockroachDB的陈旧版本被作为最新版本发布给Homebrew或Docker等工具,导致我们的净促销员得分(NPS)下降。有了流式分析,我们现在可以对NPS得分发出警报,并立即看到版本故障,而不是一周之后。我们可以迅速解决这样的问题。最终,这一变化释放了时间,使我们可以专注于真正重要的事情:为我们的用户创造价值。
我们是如何做到的
我们的数据之旅看起来是这样的。

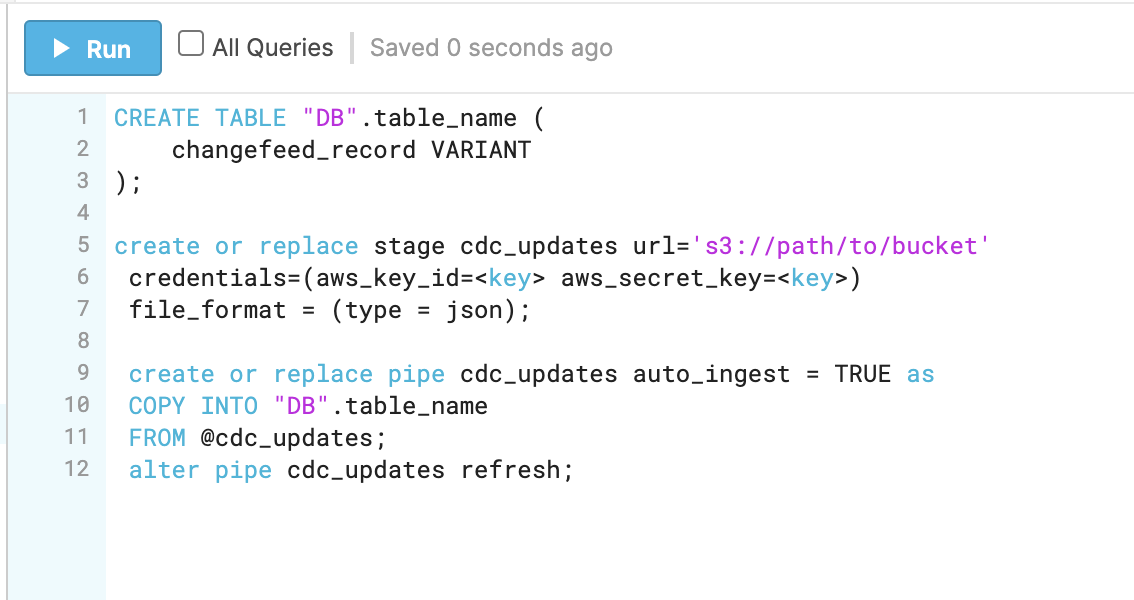
我们首先使用AWS的S3桶作为一个通用的数据转储。Cockroach支持S3作为变化反馈的本地汇。S3 桶也支持数据的自动嵌套到 Snowflake,使 S3 在这种情况下成为变化反馈数据的理想转储。

然后,我们使用 Snowpipe 将数据加载到 Snowflake。Snowflake 自动捕捉数据的差异,并自动测试变化。如果你的工作负载有大量的更新(相对于附加),你需要在发送数据到Snowflake之前对数据进行一些预处理。虽然我们使用 Snowflake,你可以使用你选择的 OLAP 数据库。
我们的 Looker 实例从 Snowflake 读取数据源,聚合数据并显示在仪表盘上。Looker是一个专门设计的商业智能工具,可以很容易地从复杂的数据查询中建立漂亮的仪表盘。

来自Looker文档的仪表盘示例
将这些工具串联起来有助于我们从每个应用程序中获得最佳效果,并使我们的整体数据栈更加强大。使用changefeeds来串联数据更新,可以得到更细化、最新的仪表盘,我们用它来推动产品决策。作为一家初创公司,我们需要数据来快速移动和创新。此外,快速识别和修复问题的能力是非常有价值的,因为负面的印象会对一个新生的公司造成致命的打击。当CockroachDB的陈旧版本被发布到软件包管理工具中时,它给人的印象是我们的产品表现不佳,可能不如预期的稳定。错误会发生。减少类似错误的成本是我们长期成功的关键。
教程/资源
要探索在你的CockroachDB集群中做类似的事情,最好的地方是我们的教程,即把变化反馈流到Snowflake。你将一步一步地通过自动测试数据库的变化到Snowflake的过程。
从那里你可以连接Snowflake到Looker,Tableau,或你选择的商业智能软件。
注意:本教程使用企业变化反馈流到一个可配置的云存储槽。核心的变化馈送将不能自然地连接到云存储汇。
