


图片由作者提供。
贝叶斯统计学的美丽,同时也是它最令人讨厌的特征之一:我们经常得到的答案是 "嗯,这个数字介于...... "之间的形式。
如果一方面,这可能会让寻求直接指导的商业战略家或政策制定者感到沮丧,那么它也是了解你可能犯错的绝佳方式。
从一个简单的例子开始,假设我们得到的任务是找到一个高中教室里学生的身高分布。也许这所学校需要校服,而校服公司希望对每种尺寸的校服生产数量有一定的了解,而了解身高分布就能知道要生产什么尺寸的校服。
贝叶斯推理基础知识
假设我们有一个变量,h,表示这些学生的身高。如果我们想知道h是如何分布的呢?也就是说,我们可能已经知道了分布的样子(身高通常是正态分布),但所述分布的参数是什么?我们为什么要关心这个问题呢?嗯,我们关心是因为知道一个变量是如何分布的有助于我们预测新的数据会是什么样子。例如,如果我们知道身高是正态分布,我们就知道一个新的数据点可能会接近平均值(如果平均值是1.75米,那么我们预计一个新加入班级的学生的身高会接近这个平均值)。知道分布的参数还可以让我们从中取样(所以我们可以创建一个 "假 "学生的样本,从而了解我们可能期望有多少身高的学生)。因此,找到一个变量的分布有助于我们解决预测问题。
贝叶斯推理是一种找出变量分布的方法(如身高h的分布)。贝叶斯推理的有趣特点是,由统计学家(或数据科学家)利用他们的先验知识作为手段,来改进我们对分布情况的猜测。
贝叶斯推断依赖于贝叶斯统计学的主要公式。贝叶斯定理。贝叶斯定理吸收了我们对分布情况的假设,一个新的数据,并输出一个更新的分布。对于数据科学来说,贝叶斯定理通常是这样表述的。
统计学家也给这个定理的每个组成部分起了名字。
让我们复习一下,以便更好地理解它们。
先验
从贝叶斯定理中我们可以看到,先验是一个概率。P(θ)。θ通常表示为我们对最能描述我们所要研究的变量的模型的假设。让我们回到身高的例子。我们从背景知识和常识中推断,身高在一个班级中呈正态分布。从形式上看。
h∼N(μ,σ)
其中N表示正态分布,μ表示平均值,σ表示标准差。
现在,我们的先验不完全是上面的表达式。相反,它是我们对每个参数、μ和σ的分布方式的假设。请注意,这就是贝叶斯统计的决定性特征出现的地方:我们如何找到这些参数的分布?好吧,有趣的是,我们根据我们的先验知识来 "编造 "它们。如果我们的先验知识非常少,我们可以选择一个非常无信息的先验,这样就不会在过程中出现偏差。例如,我们可以定义μ,平均高度,在1.65米和1.8米之间。如果我们想选择一个无信息的先验,我们可以说μ是沿着这个区间均匀分布的。相反,如果我们认为平均高度在某种程度上偏向于接近1.65米而不是1.8米,我们可以定义μ是用β分布,由 "超 "参数α和β定义。
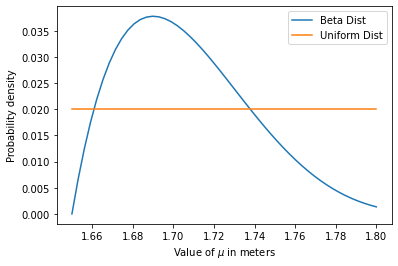
图片由作者提供。
注意Y轴是如何给我们提供 "概率密度 "的,也就是说,我们认为真实的μ是X轴上的那个的可能性是多少。另外,请注意,β分布和均匀分布在我们认为μ的值可能是什么方面导致了不同的结论。如果我们选择均匀分布,我们就是在说,我们对μ是否接近我们范围内的任何数值没有倾向性,我们只是认为它在那里的某个地方。如果我们选择β分布,我们就相当肯定μ的 "真实 "值是在1.68米和1.72米之间,正如沿蓝线的峰值所示。
请注意,我们讨论的是μ的先验,但我们的模型实际上有两个参数。N(μ,σ)。一般来说,我们也可以对σ定义一个先验。然而,如果我们对我们的σ猜测感到幸运,或者我们想为了一个例子而简化过程,我们可以把σ设定为一个固定值,比如0.1m。
可能性
可能性表示为P(数据|θ)。本例中的 "数据 "是一个身高的观察值。假设我们随机挑选了一个学生,他们的身高是1.7米。考虑到有了这个数据,我们现在就可以知道每个选项的θ有多好。我们要做的是问:如果θ的某个选项,称为θ1,是真正的选项,我们观察到1.7米的身高的 "可能性 "有多大?θ2呢:如果θ2是 "正确 "的模型,观察到1.7米高度的可能性有多大?
事实上,我们在这个阶段想要的是一个函数,它将系统地查看模型θ的每一种可能性,并找到这个模型会 "产生 "或 "预测 "观察到的值的概率。请记住,在这种情况下,我们的模型θ被定义为N(μ,σ),即一个具有平均数μ和标准差σ的正态分布。我们还保持σ不变以简化过程。因此,我们的函数将把μ的可能值作为我们的 "自变量",我们观察到的1.7m的数据点,它将输出每个模型是正确模型的概率作为我们的 "因变量"。请注意,我们在这里遇到了一个小插曲:从技术上讲,某个特定模型是正确模型的 "概率 "为零,因为从理论上讲,θ的可能性是无穷的。出于这个原因,我对θ的可能性进行了离散化处理,使其在1.65米和1.8米之间有50个θ的选项。然后,我们使用每个建议的模型的概率密度函数来评估特定模型的观察基准的概率密度。概率密度并不等同于概率,它只是给我们一个相对的衡量标准,即在每个模型选项下,观察到该点的可能性有多大。为了得到真正的概率,我们必须对概率密度进行 "标准化",使其与所有的值相加得到1。
然而,这并不是一个大问题,因为我们仍然可以比较每个模型的可能性。这就好像我们在问:把可能性限制在这个离散的模型集上,这些模型在某种程度上全面覆盖了合理的可能性,哪个模型是最好的?尽管如此,我们也要对概率密度进行归一化处理,你会在下面看到。
这个函数被称为 "似然 "函数,我们通常用我们提出的模型的概率 "密度 "函数(PDF)来定义它,在新的数据点进行评估。因此,我们希望得到数据点1.7m的分布N(μ, 0.1m)的 "PDF"。
请注意,对于那些以前使用过PDF的人来说,这似乎有点落后了。对于PDF,我们通常有一个固定的模型,例如N(1.8,0.1),我们用它来评估我们的变量h的不同值的概率。这意味着我们会把变量h放在X轴上,把概率密度放在Y轴上。
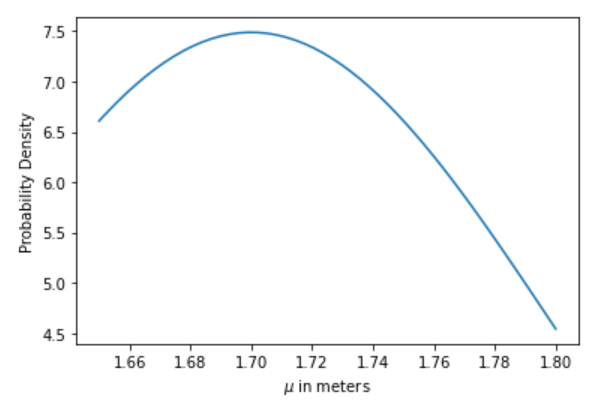
然而,对于我们目前的目的,我们正在改变分布/模型本身。这意味着我们的x轴实际上有变量μ的不同可能性,而我们的y轴将有这些可能性的概率密度。请看下面的代码,它表示我们的似然函数和可视化。
图片由作者提供。
看看我们的函数是如何简单地告诉我们哪些μ的值是最有可能的?看看这如何让我们对概率有一个相对的了解,统计学家更愿意把它称为每个可能的μ的 "可能性"?有了这种可能性的评估,我们就可以先入为主地倾向于μ的 "最佳 "值是什么。然而,我们必须将其与先验结合起来,以得到我们对μ的最佳值的最终 "猜测"。
证据
一些统计学家把P*(数据*)称为 "证据"。这个变量的含义非常直接:它是产生数据值的概率。然而,这是很难直接计算的。值得庆幸的是,我们有一个很好的技巧。
考虑一下下面的表达式。
你能明白为什么它有意义吗?直观地说,我们的意思是,如果我们把每一个假设θ的概率评估相加,我们会用尽所有的假设概率,我们应该只剩下P(Data)。请注意,P(θ)是一个概率分布,如果我们把它对每个θ的所有输出加在一起,就会变成等于1。请注意,∫P(Data|θ)∗P(θ)dθ相当于找到以P(Data|θ)∗P(θ)为y轴、θ为x轴的图形的曲线下面积,我们下一步正是要这样做。
后验
贝叶斯定理的右手边,P(θ|Data),被称为 "后验"。它是我们对数据如何分布的后验理解,因为我们目睹了数据,而且我们对它有一个先验。
我们如何得到后验?回到方程上来。
那么,第一步是将似然(P(数据|θ))和先验(P(θ))相乘。

图片由作者提供。
我们可以看到,如果我们将未归一化的后验中的概率密度相加,我们会得到一个不同于1的值。

请注意,我们仍然有 "P(Data) "需要处理,因此我把它称为 "未归一化的后验"。
请记住上面的内容。
我们可以简单地计算这个积分并进行最后的除法,然后我们就得到了后验。既然如此,我们不妨多想想为什么我们要除以P(Data)。请注意,计算P(Data)与找到未归一化的后验与上图中X轴之间的面积是一样的。同样,因为后验是一个概率分布,所以必须是后验pdf所约束的面积之和为1。为了确保这一点,我们必须找出当前的曲线下面积,然后用每个数据点除以这个数字。这就给了我们一个归一化的版本!
另外,请注意,用分析法计算积分将是非常具有挑战性的。相反,我们可以使用scipy和'梯形'方法进行近似计算,只需要x轴和y轴的值就可以估算出面积。这是我在下面使用的实现方法。
图片由作者提供。
我们能否验证这个新的图形代表一个有效的PDF?请记住,要做到这一点,图形下的面积之和必须为1。我们可以快速计算出这个值来检查。
改进模型
请注意,到目前为止,我们的贝叶斯推理经历了以下步骤。
- 定义我们的先验(s)
- 定义我们的似然函数
- 观察一个数据
- 使用贝叶斯定理找到后验分布(并使用梯形规则对后验进行标准化)。
在实践中,我们不会止步于此:观察一个数据可能还不足以让我们对我们的模型有高度的信心!这就是贝叶斯推理。贝叶斯推断背后的理念是,它是迭代的,每一个新的观察都使我们更好地了解我们感兴趣的变量的 "真实 "分布。
那么,我们如何继续前进呢?接下来的步骤是。
- 观察一个新的数据点。
- 把我们刚刚发现的后验,变成我们的新先验
- 使用同样的老的似然函数,在这个新观察到的数据点上评估我们不同假设的似然性。
- 将我们的新先验值和似然值相乘,得到未归一化的后验。使用 "梯形 "规则来归一化后验。
然后,我们对我们所拥有的多少个数据点重复步骤1到4。为了展示这个过程,让我首先生成1000个新的数据点。

图片由作者提供。
看到了吗,随着我们得到越来越多的数据,我们的模型越来越接近 "真相"?换句话说,我们模型的平均值趋近于μ的真实值,其真实值为1.7m,而我们猜测的不确定性(即我们分布的标准差)也在缩小这意味着,更多的数据=更准确和精确的猜测。
下面,我们可以看到数据数量的增加是如何导致预测的平均值μ越来越接近μ的 "真实 "值1.7m的。
图片由作者提供。
从代码中注意到,我使用了一个累积梯形函数来寻找我们后验输出的分布的平均值。我把它留给读者,让他们重新创建代码,并研究为什么以及如何使之合理化
在这个阶段,我们要做的就是得到我们模型的最终预测均值(有最多数据的那个),并将其作为我们的 "真实 "模型。在观察了1000名学生的数据后,我们取最后的平均值,并将其作为我们模型的平均值。此外,我们还可以得到99%的置信区间,这有助于我们了解我们预测的平均值可能有多大的 "错误"。
图片由作者提供。
使用完成的模型
现在我们有了改进后的模型,我们可以用它来进行预测了!基于我们得出的最终模型,我们的模型被指定为。
- N(μ,σ)
- μ=1.699m
- σ=0.1m
我们现在可以用这个模型来回答潜在的有趣的商业相关问题比如说。
在一个由100名学生组成的班级中,我们可以预期有多少学生超过1.75米?
利用我们的分布,我们可以用两种方式回答这个问题:第一种是分析性方式。我们可以用正态分布的累积密度函数来求出1.75米以下的密度有多少,然后用1减去这个值,得到1.75米以上的密度。
这表明,有大约30%的机会,一个学生的身高会超过1.75米。在一个有100名学生的班级里,这意味着我们预计有30名学生的身高超过1.75米。我们可能回答这个问题的另一种方式是通过模拟。我们可以用我们的模型对100名学生进行抽样,并计算有多少人身高超过1.75米。
然而,真正的贝叶斯统计学家很少对任何事物只进行一次模拟。我们希望能够捕捉到我们的不确定性和方差。因此,我们可以进行上述模拟一百次,并绘制该分布图。
图片由作者提供。
我们还可以根据模拟结果找到我们断言的99%置信区间,这是该方法的一个重要优势。

图片由作者提供。
有了我们的模拟平均值以及我们的界限,我们现在可以很好地了解有多少学生可能会超过1.75米。例如,如果我们需要知道这些信息以便生产校服进行销售,我们可以采取保守的方法,生产40件大尺寸的校服,我们预计99%的情况下我们会有足够的校服可以销售。这有助于我们知道我们可能想要多少冗余。而生产30件大号制服可能没有任何误差空间,一个更有趣的问题是:我们应该留下多少误差空间?在贝叶斯统计学和贝叶斯推理的帮助下,我们可以为这种类型的问题找到一个非常有说服力的答案!
如何在Python中使用贝叶斯推理进行预测》最初发表在《走向数据科学》杂志上,人们通过强调和回应这个故事来继续对话。
