

持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第28天,点击查看活动详情
背景
-
问题:Git是什么呢? Git是一个版本控制工具。
-
问题:那我们为什么需要使用呢? 随着社会发展,分工越来越细致了,企业需要专家而不是砖家。我们不需要掌握更多技能,只需要精通一个技术就非常优秀了。
当一个项目非常大的时候,需要许多开发者协同工作。试想,如果没有版本控制工具,在一个工程目录下,怎么才能追踪一个文件,这里的追踪文件,可以理解为文件的日志记录信息或者理解为文件的生命周期。这里用文件的生命周期来描述。文件的创建、修改、删除,是哪个开发者操作的?是什么时候操作的?修改了哪些内容?是否引入了一些不合理的逻辑?假如引入了不合理的逻辑,我们能否回退到指定的某个生命周期呢?
可能,我们会想,大项目是大厂的,大多数还是小项目,一个人也可以完全应对,根本不需要使用Git。
假如,项目已经在生产线上了。用户在使用过程中,项目暴露出了一个bug。这个时候,我们会立即去询问问题的详细信息,充分了解后,去复现,定位问题,寻找问题原因,然后解决。这个时候,我们可能会新打一个jar包,并重新部署到生产环境。但是,在软件领域,解决一个Bug,同时也会引入新的Bug。这个时候,线上也需要运作,我们如何才能回到原来的版本呢?
假如,项目已上线。这个时候客户有了新需求。当我们把新功能完成,并上线了,随后也可能发现一些Bugs。但是,我们不记得自己修改了原来的哪些代码,因为没有日志记录,没有文件的生命周期过程,我们真的不知道文件发生了什么。
如果有一个工具帮助我们管理文件的生命周期就好了。记录一个文件的每个状态:谁在某个时间创建了一个文件;谁在某个时间进行了修改,修改了哪些内容;谁在某个时间把此文件给删除了。Git解决了这些问题。
理解Git
本来辛苦的工作,如果再失去乐趣,那做这份工作还有什么意义?有的认为,刚开始,我们无需关心,Git指令背后发生了什么,只需要熟练使用就行。真的可以,因为人的精力也是有限的,而且又是刚开始,不理解背后的机理,也行。一个技术,第一步是熟练使用,其次,理解她的工作过程,最后就是懂他背后的内因。随着我们对Git的实践多了起来,慢慢地熟悉她,一次又一次的梳理和总结,懂她背后的工作过程。也只有懂了背后的机理,做这份工作才有乐趣和意义。
我们需要熟悉她常用的基本指令及其指令的含义以及她的工作过程。
基本指令
- Repository: 版本库。存东西的地方。对于项目而言就是:工程目录。其实就是代码文件夹。
- head:指针。指向开发者当前的工作分支。
- add: 请求Git追踪一个文件。
- commit: 保存当前状态到Git的本地工作区中(本地仓库)。
- pull: 从远程版本库更新代码。
- push:更新代码到远程版本库。
- merge: 合并不同版本的代码。
- status: 展示当前分支的信息。
工作过程
-
常规操作流程。
add: 告诉Git,C文件需要被追踪。 commit: 告诉Git,请把我修改的内容更新到分支上去。其实就是保存当前状态。 pull: 是本地仓库和远程仓库交互的桥梁。从远程仓库更新代码到本地仓库。 push: 是本地仓库和远程仓库交互的桥梁。把本地仓库的代码更新到远程仓库。
-
什么是工作区呢?
这里的项目的根目录hello-spring-cloud-config就可以理解为一个工作区,或者叫做本地仓库。其实就是我们项目根目录。
-
项目目录下有些什么?
有一个文件:hello-spring-cloud-ereka-dev.yml。 有一个隐藏文件夹:.git
-
.git目录下有些什么?
-
对于Git我们需要理解三个非常核心的概念。工作区,对象存储和暂存区。 工作区:其实就是项目目录,在这个目录下,我们可以新建文件,编辑文件,新建目录。 创建一个文件叫Sanding.txt,然后运行 git status,看看打印了什么内容?
从打印的信息,知道文件Sanding.txt未被Git追踪。
对象存储:
执行 git add Sanding.txt,然后执行git status
然后cd .git目录下,执行tree
可以得到结论:当执行git add操作后,会把文件Sanding.txt进行hash,得到一个hash字符串并放在目录objects下。
我们执行 git hash-object Sanding.txt
hash串一样。为什么在objects目录下取hash串前两位呢?遍历速度快。
看看Sanding.txt文件中是否有内容?没有任何内容。
git cat-file e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 -p
暂存区
执行 git commit -m "Add Sanding"
在.git目录下,执行tree命令
从图中,可以看见又多了两个新的对象存储(25xxx, a9xxx)。
执行: git cat-file a9805fdf11a4401de9ab4a7e3be44783b5b4e998 -p
这个对象id(hash串),其实是有关tree的信息和元数据,比如谁提交的,注释是什么。
执行: git cat-file 25f6cadf2a3590d4e27bc972f645e1a8fcc623bf -p
这个对象id(hash串),其实是包含了文件内容(blob)。
- 分支
执行: cat refs/heads/master
创建分支: git branch test, 并查看分支:git branch
其中 * 代码当前工作的分支。
看看目录变化情况:tree
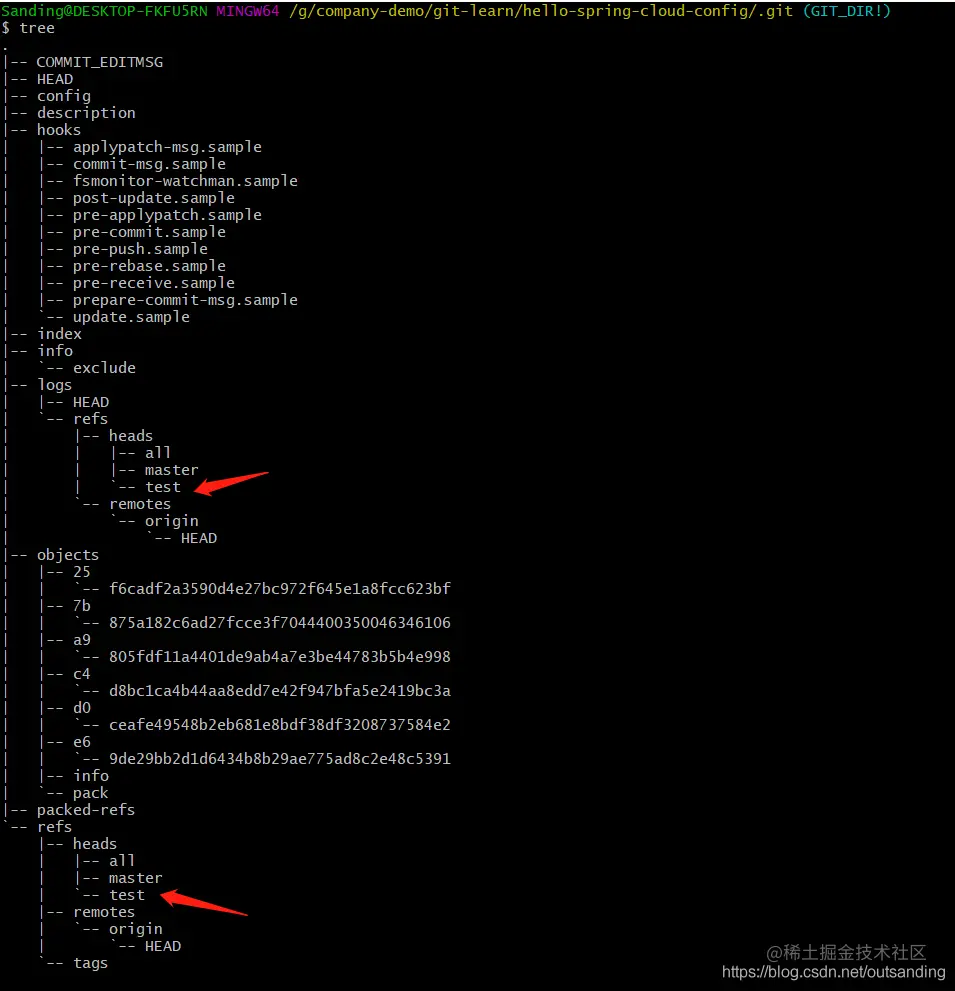
结果
我们可以通过操作git指令,然后观察目录的变化,就会明白,操作命令背后完成了哪些操作。了解了什么是Git以及为什么需要使用她。理解常规操作和背后大致的工作过程。
小结
-
当我们执行git add命令时候,是为了告诉git,具体某个文件需要被追踪。并且每次她都会为此文件生成一个hash串,并放到objects目录下,所以她是以对象的方式进行存储的。并且,objects目录下,取hash串前两位作为文件目录,这样加快遍历速度。这个时候其实是:把文件添加到暂存区中。
-
当我们执行git commit的时候,希望git把此文件的当前状态更新到本地分支上。并且会在objects目录生成两个新的对象。一个是元信息(谁提交的以及注释信息),另一个是真实的文件对象(blob类型),即是文件的内容。这个时候其实也可以理解为把文件提交本地仓库中。
-
所有的分支都存入:.git/refs/heads 目录下。
