

构建DOM树
为什么要构建DOM树?
💡 浏览器无法直接理解和使用 HTML,需要使用 HTML Parser 转换成浏览器能够理解的DOM树。输入: HTML 文档
输出:DOM 树
处理过程:
- 读取 HTML 原始字节流,根据文件指定的编码(UTF-8)将他们转换成字符;
- 分词器(状态机)将字符流转换成 Token,分为 Tag Token 和文件 Token,Tag Token 分为 startTage 和 endTag;
- html 解析器利用栈结构维护 DOM 树之前的父子关系。
我们将整体流程梳理如下:
下载不同资源的处理
1)CSS、Imag:HTML 解析继续
2)JavaScript(未设置 async、defer):由于 JavaScript 拥有修改 DOM 结构的权限,会停止解析直至脚本下载完成。通过预加载扫描器,我们不必等到解析器找到对应的外部资源的引用来请求资源,通过后台检索资源提前下载,这种优化减少了阻塞。
async 与 defer 区别如下:
样式计算(Recalculate Style)
输入:样式表
输出:DOM 节点的样式,最终计算样式在 Devtools 中查看 Computed
处理过程:遵循 CSS 继承和层叠原则,计算 DOM 节点中每个节点的具体样式
CSS 转换成 styleSheets(document.styleSheets)
CSS 样式来源的三种方式:
- 通过 link 引用外部 CSS 样式文件
- style 标签内的 CSS 样式
- 元素的 style 属性内嵌的 CSS
标准化样式表中的属性值
计算 DOM 树中每个节点的具体样式(继承与层叠),构建过程与 DOM 类似
Bytes → Characters → Tokens → Nodes → CSSOM
布局阶段
输入:DOM 树、CSSOM 树
输出:布局树
处理过程:将 DOM 和 CSSOM 合并成一个渲染树
从 DOM 树的根节点开始遍历每个可见节点
- head,script 元素不会渲染输出,所以这些节点会被忽略。
- 通过 CSS 隐藏的节点也会被渲染树忽略。display: none 将节点从渲染树中移除导致节点不可见;visibility: hidden 节点仍占据布局空间,将节点渲染成空框让节点不可见。
对于每个可见节点,找到对应的 CSSOM 规则并应用
分层
为什么需要分层?
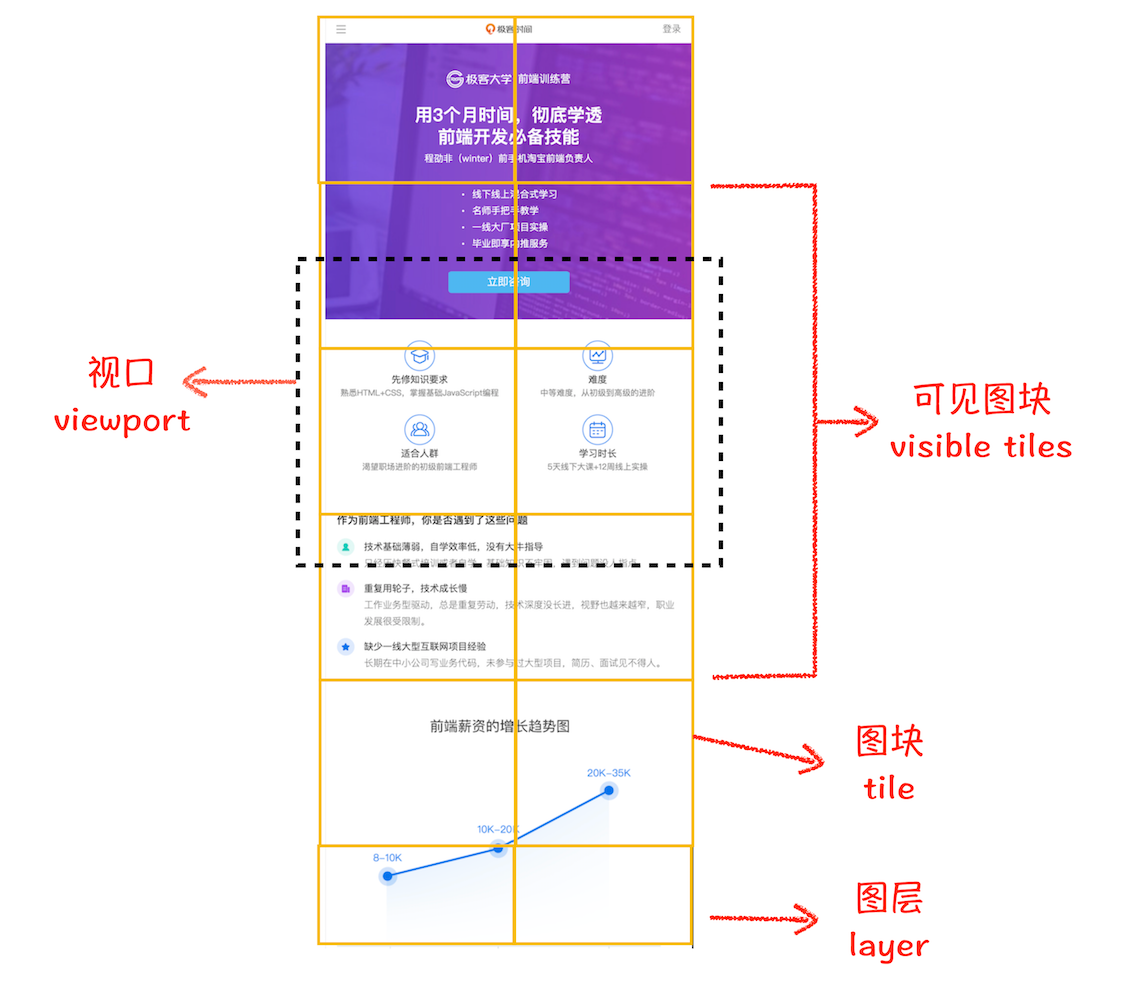
💡 为了处理复杂的效果,如页面滚动,z-index,需要为特定的节点生成专用图层。页面是二维平面,为了让页面具有三维效果,引入了 z 轴。输入:布局树
输出:图层树(Layer Tree)
处理过程:页面被分成了许多都图层,图层叠加形成最后的页面,每个节点间接或直接属于一个图层
什么情况下会被提升为单独的图层?
- 拥有层叠上下文属性的元素(position、opacity)
- 需要剪裁的地方(scroll)
图层绘制
输入:图层树
输出:绘制列表(记录绘制顺序和绘制指令的列表)
处理过程:
栅格化(Raster)
图块、位图(二进制)
输入:图块
输出:位图
处理过程:绘制列表只是用来记录绘制顺序和绘制指令的列表,实际的图层绘制操作由合成线程来完成。主线程提交绘制列表给合成线程。绘制所有的图层内容会产生不必要的开销,所以合成线程会将图层划分为图块(256256,512512),按照视口附近的图块优先生成位图。栅格化指图块转换成位图的过程。
合成与展示(Compositor)
输入:位图
输出:页面
处理流程:合成线程收集位图的信息构建合成帧,通过 IPC 向浏览器进程提交合成帧和绘制指令,浏览器进程将页面内容绘制到内存中,最终展示在页面上。
重排、重绘、合成
- 重排指由于页面布局,几何属性等发生变化导致的重新渲染
- 重绘指元素的风格,外观等不会影响布局的属性发生变化时,导致的重新渲染
- 合成
