

引
本文将简单介绍一下数组的基本概念、数组的创建方式、数组的遍历、数组的拷贝等
什么是数组?
数组其实就是一组相同数据类型的数据的集合
eg:T[] 数组名 = new T[N];
形如上面这个例子就是一个数组:
- T[] 代表的是数组的类型
- N 则代表数组的容量大小(即数组的长度)
- new 关键字实例化一个对象~
- T 代表数组中每个元素的类型
数组的特点
- 数组中存放的元素类型是相同的
- 数组的空间是连在一起的(即在内存上是连续的)
- 每一段内存空间都有自己的编号(即下标),其起始位置的编号为 0 ,从 0 开始往后顺延~
- 数组是支持随机访问的,因为其内存空间是连续的
#数组的创建和初始化
方式一
使用 new 关键字创建一个数组
- 这种创建方式必须指定数组的大小
- 普通类型默认数组中的元素值为 0
- 引用类型默认数组中的元素值为 null
// 使用 new 实例化一个对象,该对象就是数组
// 创建一个可以容纳 10 个int类型元素的数组
int[] array = new int[10];
方式二
不使用 new 关键字直接初始化数组
- 这种方式本质上其实是省略了 new T[],虽然省去了new T[],但是编译器编译代码时还是会还原
- {} 中数据类型必须与[]前数据类型一致
- 这里虽然没有指定数组的长度,编译器在编译时会根据{}中元素个数来确定数组的长度
// 不使用 new 关键字直接初始化数组
// 创建了一个空数组
int[] array1 = {};
// 创建了有五个元素并且值为 1 2 3 4 5 的数组
int[] array2 = {1,2,3,4,5};
各种类型默认的值
| 类型 | 默认值 |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0 |
| float | 0.0f |
| double | 0.0 |
| char | /u0000 |
| boolean | false |
| String | null |
数组的遍历
所谓 "遍历" 其实就是将数组中的所有元素都访问一遍
方式一
使用 for 循环来遍历
代码
int[] arr = new int[]{1,2,3,4,5};
// 使用 for 循环来遍历数组
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
// 输出 1 2 3 4 5
方式二
使用 foreach 来遍历数组
代码
int[] arr = new int[]{1,2,3,4,5};
// 使用 foreach 来遍历数组
for (int num : arr) {
System.out.println(num);
}
for循环 和 for each循环的区别
for是可以拿到下标
for each 拿不到下标,但可以拿到里面的元素
为什么数组是引用类型?
什么是引用?
- 这个引用(arr)指向这个对象(数组) 引用是指向一个对象 引用存储的是变量的地址
- int[] arr = NULL;(这个引用不指向任何对象)
- 引用指向引用。这句话是错的,引用只能指向对象
- 一个引用 只能保存 一个对象的地址
什么是 null?
null 在 Java 中表示 "空引用" , 也就是一个不指向对象的引用
- null 的作用类似于 C 语言中的 NULL (空指针), 都是表示一个无效的内存位置. 因此不能对这个内存进行任何读写操作.一旦尝试读写, 就会抛出 NullPointerException
- null 的作用类似于 C 语言中的 NULL (空指针), 都是表示一个无效的内存位置. 因此不能对这个内存进行任何读写操作.一旦尝试读写, 就会抛出 NullPointerException
什么是内存?
内存其实就是存储数据的~ 内存是一段连续的存储空间,主要用来存储程序运行时数据的
内存的作用
- 程序运行时代码需要加载到内存
- 程序运行产生的中间数据要存放在内存
- 程序中的常量也要保存
- 有些数据可能需要长时间存储,而有些数据当方法运行结束后就要被销毁
JVM 的内存分布
JVM 的内存分布就是 JVM 按照功能对内存进行了规划~
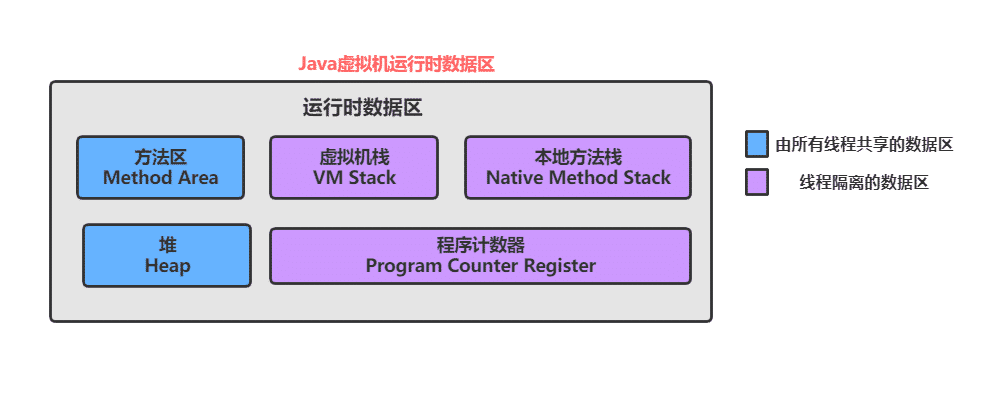
- 程序计数器 (PC Register): 只是一个很小的空间, 保存下一条执行的指令的地址
- 虚拟机栈(JVM Stack): 与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧,栈帧中包含有:局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一些信息。比如:局部变量。当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了
- 本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似,只不过保存的内容是 Native 方法的局部变量。在有些版本的 JVM 实现中(例如HotSpot),本地方法栈和虚拟机栈是一起的
- 堆(Heap): JVM所管理的最大内存区域。使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]{1, 2,3} ),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销毁。
- 方法区(Method Area): 用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,方法编译出的字节码就是保存在这个区域
基本类型变量与引用类型变量的区别
- 基本数据类型创建的变量,称为基本变量,该变量空间中直接存放的是其所对应的值
- 引用数据类型创建的变量,一般称为对象的引用,其空间中存储的是对象所在空间的地址
设置为引用类型的意义是什么?
所谓的 "引用" 本质上只是存了一个地址。Java 将数组设定成引用类型, 这样的话后续进行数组参数传参, 其实只是将数组的地址传入到函数形参中,这样可以避免对整个数组的拷贝(数组可能比较长, 那么拷贝开销就会很大)
数组的拷贝
方式一
使用 Arrays 中 copyOf 方法完成数组的拷贝
代码
int[] arr = new int[]{1,2,3,4,5};
// 把 arr 中所有元素都拷贝到新数组 newArray 中
int[] newArray = Arrays.copyOf(arr, arr.length);
方式二
使用 Arrays 中 copyOfRange 方法拷贝某个范围
代码
int[] arr = new int[]{1,2,3,4,5};
// 指定范围拷贝, 这里是从下标 1 开始拷贝, 拷贝到下标 2
// 这里的拷贝范围是左闭右开 [1,3)
int[] newArray1 = Arrays.copyOfRange(arr, 1,3);
for (int num : newArray1) {
// 输出 2 3
System.out.println(num);
}
方式三
使用 System 中 arraycopy 方法完成数组的拷贝
arraycopy 方法的各个参数说明:
第一个参数 scr: 表示源数组, 你要从那个数组拷贝 第二个参数 scrPos: 表示目标数组的下标, 即你要从源数组的哪个下标开始拷贝 第三个参数 dest: 表示目标数组, 即你要拷贝到哪个数组里 第四个参数 destPos: 表示目标数组的下标, 即你要从目标数组的哪个下标开始 第五个参数 length: 表示你要拷贝的长度
代码
int[] arr = new int[]{1,2,3,4,5};
int[] newArray2 = new int[5]; // 数组初始化大小为 5
// 第一个参数 scr: 表示源数组, 你要从那个数组拷贝
// 第二个参数 scrPos: 表示目标数组的下标, 即你要从源数组的哪个下标开始拷贝
// 第三个参数 dest: 表示目标数组, 即你要拷贝到哪个数组里
// 第四个参数 destPos: 表示目标数组的下标, 即你要从目标数组的哪个下标开始
// 第五个参数 length: 表示你要拷贝的长度
System.arraycopy(arr, 2, newArray2, 2, 2);
// 使用 foreach 来遍历数组
for (int num : newArray2) {
// 打印 0 0 3 4 0
System.out.println(num);
}
深拷贝和浅拷贝
- 深拷贝:如果拷贝完成之后,通过引用去访问或修改它的时候,不会影响原来的东西
- 浅拷贝:如果拷贝完成之后,通过引用去访问或修改它的时候,会影响原来的东西。换句话说,浅拷贝就是拷贝指向对象的
关于深拷贝和浅拷贝具体说明可以见下面这篇文章~
