


语音命令不仅适用于谷歌或Alexa等助手。它们也可以被添加到你的移动和桌面应用程序中,为你的终端用户提供额外的功能甚至乐趣。而且,在你的应用程序中添加语音命令或语音搜索可以非常容易实现。在这篇文章中,我们将使用Web Speech API来构建一个语音控制的图书搜索应用。
我们要构建的完整代码可以在GitHub上找到。对于没有耐心的人来说,在文章的结尾处有一个我们将建立的工作演示。
网络语音API简介
在我们开始之前,需要注意的是,Web Speech API目前对浏览器的支持有限。要跟上这篇文章,你需要使用一个支持的浏览器。
各大浏览器对mdn-api__SpeechRecognition功能的支持数据
首先,让我们看看启动和运行网络语音API有多容易。(你可能还想阅读SitePoint对网络语音API的介绍,并查看一些其他的网络语音API的实验)。要开始使用语音API,我们只需要实例化一个新的SpeechRecognition 类,以使我们能够监听用户的声音。
const SpeechRecognition = webkitSpeechRecognition;
const speech = new SpeechRecognition();
speech.onresult = event => {
console.log(event);
};
speech.start();
我们首先创建一个SpeechRecognition 常数,它等于全局浏览器厂商前缀webkitSpeechRecognition 。在此之后,我们就可以创建一个语音变量,它将是我们的SpeechRecognition 类的新实例。这将使我们能够开始聆听用户的讲话。为了能够处理来自用户语音的结果,我们需要创建一个事件监听器,当用户停止说话时就会触发。最后,我们在我们的类实例上调用start 函数。
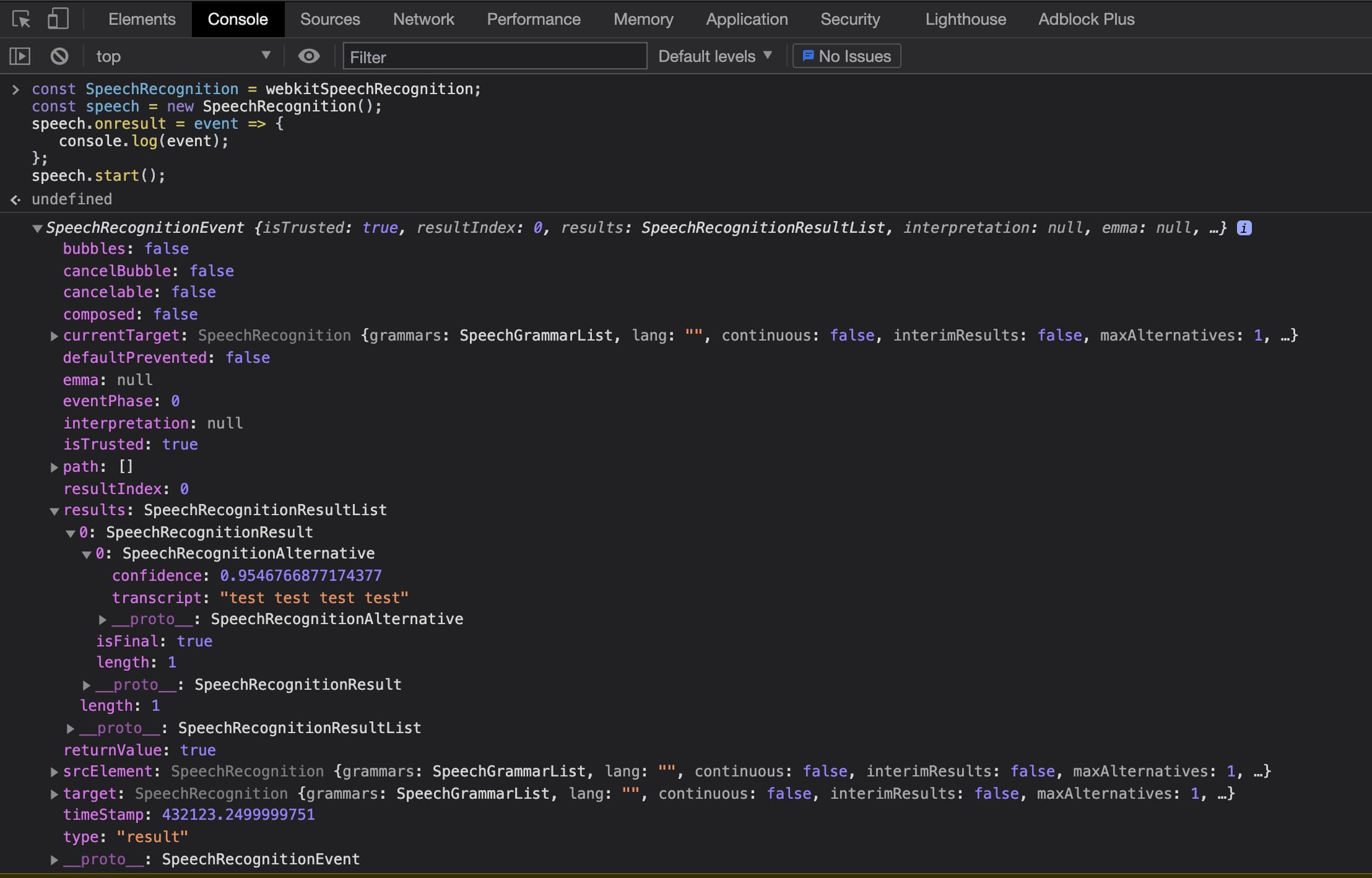
当第一次运行这段代码时,用户将被提示允许访问麦克风。这是浏览器为防止不必要的窥探而设置的安全检查。一旦用户接受了,他们就可以开始说话了,而且不会再被要求在该领域获得许可。在用户停止说话后,onresult 事件处理函数将被触发。
onresult 事件被传递给一个SpeechRecognitionEvent 对象,该对象是由一个SpeechRecognitionResultList 结果数组组成的。SpeechRecognitionResultList 对象包含SpeechRecognitionResult 对象。数组中的第一项返回一个SpeechRecognitionResult 对象,其中又包含一个数组。这个数组中的第一项包含了用户所讲内容的记录。
上述代码可以从Chrome DevTools或普通的JavaScript文件中运行。现在我们已经了解了基础知识,让我们来看看如何将其构建为一个React应用程序。我们可以看到下面通过Chrome DevTools控制台运行时的结果。
在React中使用网络语音
利用我们已经学到的知识,将Web Speech API添加到React应用程序中是一个简单的过程。我们要处理的唯一问题是React组件的生命周期。首先,让我们用Create React App创建一个新的项目,遵循其入门指南。这假定你的机器上已经安装了Node。
npx create-react-app book-voice-search
cd book-voice-search
npm start
接下来,我们用下面的代码替换App 文件,以定义一个基本的React组件。然后我们可以给它添加一些语音逻辑。
// App.js
import React from 'react';
const App = () => {
return (
<div>
Example component
</div>
);
};
export default App;
这个简单的组件渲染了一个里面有一些文字的div。现在我们可以开始向该组件添加我们的语音逻辑。我们要建立一个组件来创建语音实例,然后在React生命周期中使用这个实例。当React组件第一次渲染时,我们要创建语音实例,开始聆听结果,并为用户提供一种开始语音识别的方式。我们首先需要导入一些React钩子(你可以在这里了解更多关于React核心钩子的信息),一些CSS样式,以及一个供用户点击的麦克风图片。
// App.js
import { useState, useEffect } from "react";
import "./index.css";
import Mic from "./microphone-black-shape.svg";
在这之后,我们将创建我们的语音实例。我们可以使用我们之前在看网络语音API的基础知识时学到的东西。我们必须对我们粘贴在浏览器开发工具中的原始代码做一些修改。首先,我们通过添加浏览器支持检测,使代码更加健壮。我们可以通过检查窗口对象上是否存在webkitSpeechRecognition 类来做到这一点。这将告诉我们浏览器是否知道我们要使用的API。
然后我们将continuous 设置改为true。这样就可以将语音识别API配置为持续监听。在我们的第一个例子中,这被默认为假,意味着当用户停止说话时,onresult 事件处理程序将被触发。但由于我们允许用户控制他们希望网站停止监听的时间,我们使用continuous ,让用户想说多久就说多久。
// App.js
let speech;
if (window.webkitSpeechRecognition) {
// eslint-disable-next-line
const SpeechRecognition = webkitSpeechRecognition;
speech = new SpeechRecognition();
speech.continuous = true;
} else {
speech = null;
}
const App = () => { ... };
现在我们已经设置了语音识别代码,我们可以开始在React组件内使用它。正如我们之前看到的,我们导入了两个React钩子--useState 和useEffect 钩子。这些将允许我们添加onresult 事件监听器,并将用户的成绩单存储为状态,这样我们就可以在用户界面上显示它。
// App.js
const App = () => {
const [isListening, setIsListening] = useState(false);
const [text, setText] = useState("");
const listen = () => {
setIsListening(!isListening);
if (isListening) {
speech.stop();
} else {
speech.start();
}
};
useEffect(() => {
//handle if the browser does not support the Speech API
if (!speech) {
return;
}
speech.onresult = event => {
setText(event.results[event.results.length - 1][0].transcript);
};
}, []);
return (
<>
<div className="app">
<h2>Book Voice Search</h2>
<h3>Click the Mic and say an author's name</h3>
<div>
<img
className={`microphone ${isListening && "isListening"}`}
src={Mic}
alt="microphone"
onClick={listen}
/>
</div>
<p>{text}</p>
</div>
</>
);
}
export default App;
在我们的组件中,我们首先声明两个状态变量--一个用来保存用户讲话的记录文本,另一个用来确定我们的应用程序是否在听用户讲话。我们调用React的useState 钩子,为isListening ,传递默认值false ,为文本传递一个空字符串。这些值将在以后的组件中根据用户的交互进行更新。
在我们设置好状态后,我们创建一个函数,当用户点击麦克风图像时,该函数将被触发。这将检查应用程序当前是否正在收听。如果是,我们就停止语音识别;否则,我们就启动它。这个函数后来被添加到麦克风图像的onclick 。
然后,我们需要添加我们的事件监听器来捕获来自用户的结果。我们只需要创建一次这个事件监听器,而且我们只需要在用户界面渲染后才需要它。因此,我们可以使用useEffect 钩子来捕获组件的安装时间,并创建我们的onresult 事件。我们还向useEffect 函数传递一个空数组,这样它就只运行一次。
最后,我们可以渲染出所需的UI元素,让用户开始说话并看到文本结果。
继续阅读在SitePoint上为React应用程序添加语音搜索。
