

MySQL Kafka连接器的快速入门指南
[ 数据库和流处理在这里继续存在,而且似乎它们的未来是光明的。虽然像MySQL这样的数据库在高效存储数据和创建数百个实体之间的关系方面给了我们很大的帮助,但它们仍然远远不能帮助企业实时解决数据问题。
这是因为MySQL中的数据是被动的。它只是坐在那里,等待用户采取行动,将其转化为可操作的洞察力(使用商业智能系统)。像Kafka这样的流处理技术使企业能够实时存储和处理来自MySQL等数据库的事件流。这些技术利用异步通信和下一代架构来传输连续的数据源。
在本指南中,我们将准确地教你如何为你的Kafka现代架构配置MySQL Kafka连接器。我们探讨了两种启用MySQL到Kafka连接的方法:一种是使用Kafka Confluent Cloud Console,另一种是使用Confluent CLI工具箱。
目录
- 什么是MySQL?
- 什么是Apache Kafka?
- MySQL Kafka连接器的用途是什么?
- 设置MySQL Kafka连接器的先决条件
- 使用Confluent Cloud控制台设置MySQL到Kafka的连接
- 使用Confluent CLI设置MySQL到Kafka的连接
- 总结
什么是MySQL?
MySQL是世界上最流行的开源关系型数据库管理系统(RDBMS),被所有类型的中小型企业(SMB)和大型企业使用。MySQL最初由MySQL AB(一家瑞典公司)开发、销售和支持,但后来在2010年被Sun Microsoft Systems(目前称为Oracle公司)收购。
就像其他典型的关系型数据库一样,MySQL可以在表中以行和列的形式存储用户/业务/客户信息。它在各种表的行和列之间提供参考完整性,并使用SQL处理用户请求。
MySQL在从事数据库和基于云的数据仓库解决方案的企业中拥有很高的声誉。它具有可扩展性、可靠性和用户友好性。它还可以跨平台工作,这意味着用户可以在Linux和Windows上运行MySQL,并从其他平台上恢复备份。
使用MySQL的商业好处
由于以下原因,MySQL在全世界都很流行,并被领先的科技巨头所使用。
易于安装和部署
企业可以在几分钟内使用MySQL设置和运行其数据的SQL查询。与其他专有数据库相比,MySQL使他们能够更快地提供新的应用程序。
高速度
毋庸置疑,如果你正在处理大型数据集,你不会想花大量时间来处理数据集和表格。与其他数据库不同,MySQL的速度相对较快,可以更快地从大型数据集查询信息,帮助推动更快的商业智能。
在此阅读更多关于10大MySQL ETL工具的信息。
行业标准
无论你是做快速软件开发的开发人员还是寻求数据库工作的自由职业者,MySQL已经使用了20多年,你可以确信使用MySQL是一个完全集成的交易安全、符合ACID的数据库。
可靠性和高可用性
MySQL在其500万用户群中有着良好的可靠性声誉。除了可靠性之外,MySQL集群给你的用户提供了无可比拟的99.999%的可用性。
多平台支持
MySQL可以在20个平台上使用,包括Linux、Solaris、AIX、HP-UX、Windows和MacOS。这为企业提供了完全的灵活性,可以在他们选择的平台上提供一个解决方案。
什么是Apache Kafka?
Apache Kafka是一个开源的分布式流平台,允许开发实时事件驱动的应用程序。它使开发者能够依靠消息代理,创建能够持续产生和消费数据记录流的应用程序。这个消息代理将消息从 "发布者"(将数据转换为数据生产者所需要的格式的系统)转发到 "订阅者"(操作或分析数据的系统,以便找到警报和洞察力,并将它们交付给数据消费者)。
Apache Kafka速度超快,并对所有数据记录保持高度的准确性。这些数据记录是按照它们在 "集群 "中出现的顺序维护的,这些集群可以跨越多个服务器甚至多个数据中心。Apache Kafka复制这些记录,并以这样的方式对它们进行分区,以允许大量用户同时使用该应用程序。
因此,Apache Kafka有一个容错和弹性的架构。Kafka将分区从当选的Broker(领导者)复制到其他Broker(也称为副本)以确保稳健性。Broker是一个工作的服务器或节点;就像数据生产者和数据消费者群体之间的促进者。对一个主题的所有写入和读出都是通过领导者进行的,他负责组织用新数据更新副本。
使用Apache Kafka的商业好处
低延迟的发布-订阅消息服务
对于庞大的数据量,Apache Kafka的端到端延迟非常低,最高可达10毫秒。这意味着产生到Kafka的数据记录被消费者检索的时间是相当快的。这是因为它对消息进行了解耦,允许消费者在任何时候都能检索到它。
无缝的消息传递和流媒体功能
Apache Kafka提供了一种独特的能力,可以实时发布、订阅、存储和处理数据记录,这要归功于它对消息进行解耦并以高效的方式存储的特殊能力。
有了这种无缝的消息传递功能,处理大量的数据变得简单而容易,使商业通信比传统的通信方式具有相当的优势。
对消费者友好
Kafka可用于与广泛的消费者整合。Kafka最棒的地方在于,它可能会根据与之连接的消费者而表现出不同的行为或行动,因为每个消费者都有不同的能力来管理从Kafka出来的消息。此外,Kafka可以很好地与用各种语言编写的消费者整合。
使用Hevo的无代码数据管道在几分钟内复制MySQL和Kafka数据
Hevo数据,一个完全管理的数据管道平台,可以帮助你在几次点击中自动化,简化和丰富你的数据复制过程。通过Hevo的各种连接器和快速的数据管道,你可以从100多个数据源(如**MySQL和Kafka**)提取和加载数据,直接进入你的数据仓库或任何数据库。为了进一步简化和准备你的数据分析,你可以使用Hevo强大的内置转换层来处理和丰富原始的颗粒数据,而不需要写一行代码。
Hevo是最快,最简单,最可靠的数据复制平台,将为你的工程带宽和时间节省数倍。今天就来试试我们的14天免费试用版,体验一下完全自动化的无障碍数据复制吧!
MySQL Kafka连接器的用途是什么?
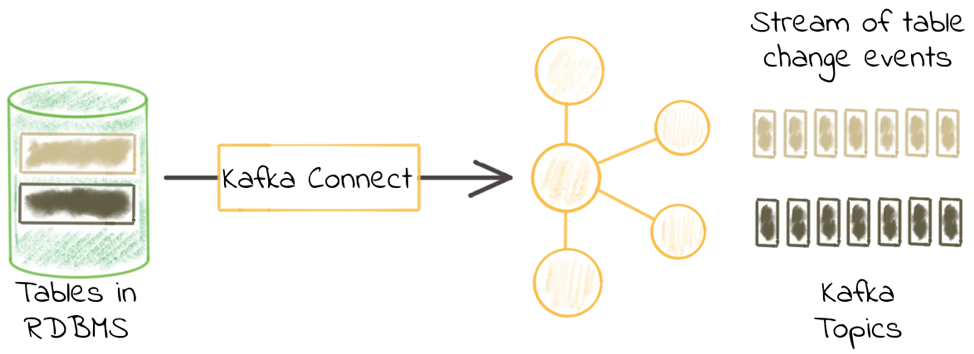
图片来源。Confluent
MySQL Kafka连接器是一个有用的工具,用于将数据从外部数据库(如MySQL)流到Kafka主题。这个工具允许你从MySQL关系型数据库表中提取数据,并记录所有对数据进行的行级更改。这个连接器可以在Confluent网站上找到,叫做Confluent JDBC MySQL源连接器。它在云中运行。
MySQL Kafka连接器支持多种数据格式,如Avro、JSON Schema、Protobuf或JSON,以将每个数据库表的所有数据库事件同步为单独的Kafka主题。使用MySQL到Kafka连接器,你可以传输驻留在MySQL数据库表中的重要数据,如客户信息和利益相关者数据,并使用Kafka的内置功能对这些数据进行流处理。
设置MySQL Kafka连接器的先决条件
将你的关系表从MySQL数据库连接并配置到Kafka主题需要以下前提条件。
- 你有对亚马逊网络服务(AWS)、Azure或谷歌云平台(GCP)上的Confluent云集群的授权访问。
- 您已经为您的Confluent云集群安装并配置了Confluent CLI。
- 您已经启用了对您的MySQL数据库的公共访问。
- 您已启用模式注册表,以使用基于模式注册表的格式,如Avro、JSON_SR(JSON模式)或Protobuf。
- 你拥有Kafka Cluster凭证来创建一个新的MySQL到Kafka的连接。
使用Confluent Cloud Console设置MySQL到Kafka的连接
要设置从MySQL数据库表到Kafka主题的连接,你可以通过以下步骤在Confluent Cloud Console中配置MySQL到Kafka连接器。
步骤1:启动Confluent云集群
在我们将数据从MySQL数据库摄取到Kafka之前,我们建议你检查你的数据库是否已经正确设置了数据。这一步可以确保你的MySQL关系表中的数据是正确的,可以传输到你的Kafka主题。
对于驻留在MySQL表中的数据,我们需要一个Kafka Topic,我们的记录将被写入其中。
要创建一个新的Kafka集群,请访问添加集群>创建集群,从基本、标准或专用中选择。
要创建一个新的Kafka主题,请将鼠标移到Confluent Cloud仪表盘左侧面板的主题部分,然后点击主题>创建主题。 在这里,你可以输入一个主题名称,并指定分区的数量。
要改变默认设置,比如你想为实体数据(如客户的电话号码或电子邮件地址的变化)设置清理策略,你可以点击显示高级设置并指定相同的内容。
第2步:添加MySQL Kafka连接器
从左边的导航菜单,访问连接器部分,搜索MySQL源连接器卡。
点击连接器后,Confluent会把你带到MySQL Kafka连接器配置页面。接下来的步骤说明了在MySQL Kafka连接器中要做哪些数据条目。
第3步:设置MySQL到Kafka的连接
Kafka Confluent Cloud将要求你在MySQL Kafka连接器配置页面上输入以下细节。
- 连接器的名称。
- Kafka集群凭证。你可以使用服务账户资源ID或输入API密钥来提供这些。
- 主题 前缀。MySQL Kafka连接器自动创建Kafka主题为:<topic.prefix>,以及具有topic.create.default.partitions=1 和topic.create.default.replication.factor=4等属性的表。如果你想用特定设置创建主题,请在运行MySQL Kafka Connector之前创建Kafka主题。
- 连接 **细节,**其中包括主机地址和SSL连接模式的细节。
- 数据库细节,包括时间戳列名,以启用时间戳模式并检测新的和修改的行,增量列名,以启用增量模式。
- Schema 模式,从数据库中获取表元数据。
- Kafka 输出记录值,以带来多种格式的数据,如AVRO、JSON_SR(JSON模式)、PROTOBUF,或JSON(无模式)。你必须在你的模式注册表中定义一个有效的模式以启用同样的功能。
- MySQL Kafka连接器要使用的任务数。
- 支持单一消息转换(SMT)的转换和谓词 。
第4步:验证并启动MySQL Kafka Connector
一旦你输入了所需的细节,你可以从预览页面验证你的连接细节,然后启动你的MySQL Kafka连接。
这些连接属性是以JSON文件格式提供的。 根据你在Confluent Web UI中输入的内容查看JSON配置,然后点击启动,启动你的MySQL到Kafka连接。
就像其他的数据生成器连接器一样,你需要等待几分钟,一旦连接上线,你可以在连接器标签下查看连接器的状态从供应到运行。
第5步:验证你的Kafka主题
在你的MySQL到Kafka连接器上线运行后,你可以验证从MySQL数据库填充到Kafka主题的消息,并检查正确的数据条目是否被同步到Kafka主题。
是什么让Hevo的ETL流程成为同类中最好的?
如果你有大量的数据,提供一个高质量的ETL解决方案可能是一个困难的任务。Hevo的 自动化,无代码平台使你拥有顺利的数据复制经验所需的一切。
看看是什么让Hevo如此神奇。
- 完全管理。Hevo不需要管理和维护,因为它是一个完全自动化的平台。
- 数据转换。Hevo提供了一个简单的界面来完善、修改和充实你要传输的数据。
- 更快的洞察力生成。Hevo提供近乎实时的数据复制,所以你可以获得实时的洞察力生成和更快的决策。
- 模式管理。Hevo可以自动检测传入数据的模式,并将其映射到目标模式。
- 可扩展的基础设施。Hevo有内置的100多个数据源的集成(有40多个免费的数据源),可以帮助你根据需要扩展你的数据基础设施。
- 实时支持。Hevo团队24小时不间断地通过聊天、电子邮件和支持电话向客户提供特殊支持。
使用Confluent CLI设置MySQL到Kafka的连接
你也可以使用Confluent CLI来设置MySQL到Kafka的连接。具体步骤如下。
第1步:显示所有可用的连接器
下面的命令可以帮助你列出所有可用的Kafka连接器。
confluent connect plugin list
第2步:建立所需的连接器配置属性
下面是一个通用命令,可以帮助你列出任何Kafka连接器的所有必要的连接属性。
confluent connect plugin describe <connector-catalog-name>
对于MySQL Kafka连接器,同样的命令变为。
confluent connect plugin describe MySqlSource
当你执行该脚本时,它将向你展示你需要指定的所有属性,以便配置你的MySQL Kafka连接器。
Following are the required configs:
connector.class
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
topic.prefix
connection.host
connection.port
connection.user
connection.password
db.name
ssl.mode
table.whitelist
timestamp.column.name
output.data.format
tasks.max
第3步:创建MySQL到Kafka的配置文件
Kafka Confluent是一个基于Java的平台,它通过JavaScript Object Notation(JSON)文件接收任何连接器的信息。如果你想使用Confluent CLI在Kafka Confluent中建立任何连接器,你就必须使用JSON文件指定连接器的配置。
同样,MySQL Kafka连接器的配置文件是JSON文件,其中包含在MySQL和Kafka主题之间创建连接所需的所有连接属性。下面是一个定义MySQL Kafka连接器配置属性的例子。
{
"name" : "confluent-mysql-source",
"connector.class": "MySqlSource",
"kafka.auth.mode": "Your_Kafka_API_Key",
"kafka.api.key": "<your-kafka-api-key>",
"kafka.api.secret" : "<your-kafka-api-secret>",
"topic.prefix" : "mysql_1",
"connection.host" : "<your-database-endpoint>",
"connection.port" : "3306",
"connection.user" : "<your-database-username>",
"connection.password": "<your-database-password>",
"ssl.mode": "prefer",
"db.name": "mysql-test",
"table.whitelist": "customers",
"timestamp.column.name": "created_at",
"output.data.format": "JSON",
"db.timezone": "UCT",
"tasks.max" : "2"
}
这段代码中包含的属性定义描述如下。
- "名称"。指的是你的MySQL Kafka连接器的名称。
- "连接器 类"。指定连接器插件的名称。
- "kafka.auth.mode"。指定连接器的认证属性。在这个属性中,你可以使用SERVICE_ACCOUNT或KAFKA_API_KEY(默认选项)。
- "topic.prefix"。指的是在命名Kafka主题时要使用的前缀,格式为<topic.prefix>。同样,你的表在创建时的属性是:topic.create.default.partitions=1和topic.create.default.replication.factor=4。
- "ssl模式"。启用与MySQL数据库服务器的加密连接。
- "db.name"。指的是你的MySQL数据库的名称。
- "timestamp.column.name"。代表一种从MySQL表中读取数据的方式。它使用一个时间戳列来检测新的和修改的行。将此属性与 "incrementing.column.name"一起使用,你可以启用时间戳和增量模式来处理更新,使用一个全局唯一的ID,可以分配一个唯一的流偏移。
- "schema.pattern"。从你的MySQL数据库中获取表元数据。
- "output.data.format"。指定Kafka记录(来自连接器的数据)的首选输出格式。可接受的格式是AVRO、JSON_SR、PROTOBUF或JSON。
- "db.timezone"。决定数据库的时区。默认的时区是UTC。
第4步:加载配置文件以创建MySQL Kafka连接器
一旦你以所需的JSON格式设置了MySQL到Kafka连接器的属性定义,你需要将该文件加载到Kafka Confluent Cloud并启动你的连接器。
下面是这样做的命令。
confluent connect create --config <file-name>.json
你可以在-config后面指定你的MySQL到Kafka连接器文件名。假设你的文件名是 "mysql-to-kafka-source",你可以执行同样的命令,如下所示。
confluent connect create --config mysql-to-kafka-source.json
成功执行后,你会收到一条确认信息。
Created connector confluent-mysql-to-kafka-source lcc-zl7ds
第5步:检查你的连接器状态
现在我们已经加载了我们的配置文件并启动了我们的连接器,我们需要验证我们新配置的连接器是否已经启动并运行。你可以通过使用下面的命令来检查你的MySQL Kafka连接器的状态。
confluent connect list
如前所述,该命令将列出所有已经在你的仪表板中配置的可用的Kafka连接器。
对于我们的情况,你可能会收到这样的输出。
ID | Name | Status | Type
+-----------+---------------------------------+---------+-------+
lcc-zl7ds | confluent-mysql-to-kafka-source | RUNNING | source
这就是你的成果。你已经成功地配置和设置了你的MySQL到Kafka连接器。
关于MySQL到Kafka连接器配置属性的广泛细节,你可以访问Kafka Confluent的官方文档页面。
相关的。
总结
使用MySQL Kafka连接器将数据从MySQL源传输到Kafka只是一个开始,当涉及到利用实时流处理功能和探索洞察力来推动和实现业务运营的成功。在本指南中,我们讨论了两种创建和配置MySQL到Kafka连接器的方法:一种是使用Confluent Cloud Console,另一种是使用Confluent CLI工具箱。
对于大多数企业来说,真正的问题是如何利用这些数据并使其具有意义。虽然很多人知道商业分析系统,但为了能够利用这些系统,你需要在一个像数据仓库一样的单一存储库中整合数据。从MySQL或Kafka复制数据到数据仓库需要制作复杂的ETL管道,而这些管道本身也需要持续监测和日常维护。
