

什么是 递归?
编程中的递归是一个解决问题的概念。
在递归中,一个函数通过调用自己一次或多次来找到解决方案。这种函数调用可以是显性的,也可以是隐性的。
 信息。递归,根据(Tang 2013),是指一个函数或算法调用自己一次或多次。这些调用会发生,直到程序满足一个指定的条件。当满足条件时,就会发生从最后一次调用到第一次调用的重复调用的处理。
信息。递归,根据(Tang 2013),是指一个函数或算法调用自己一次或多次。这些调用会发生,直到程序满足一个指定的条件。当满足条件时,就会发生从最后一次调用到第一次调用的重复调用的处理。
请看下面一个递归阶乘函数的例子。
def factorial(n):
"""
Calculate n!
Args:
n(int): factorial to be computed
Returns:
n!
"""
if n == 0:
return 1
return n * factorial(n-1)
print(factorial(3))
# 6
在上述片段中的高亮行中,阶乘函数调用了自己。这个函数一次又一次地调用自己。
这一直持续到第10行的条件得到满足。
然后,之前的函数调用被评估,直到最初的调用。条件n == 0 是一个 基本情况。
信息。基准案例在递归函数中是非常重要的,因为它定义了递归调用的结束。如果在递归函数中存在一个错误的基数 或不存在的基数 ,那么函数的调用将无限期地进行下去,就像一个无限的while循环。
递归在函数调用中利用了堆栈。因此,无限的函数调用会导致C(编程语言)栈溢出。这种堆栈溢出反过来又会使Python崩溃。引入到python解释器堆栈中的大小限制可以防止潜在的堆栈溢出。
参见:sys - 系统特定参数和函数,以及下面最后一行评估时全局框架中的调用栈。
你可以在内存可视化器中自己尝试一下。
或者你可以看一下我的执行流程中的截图。
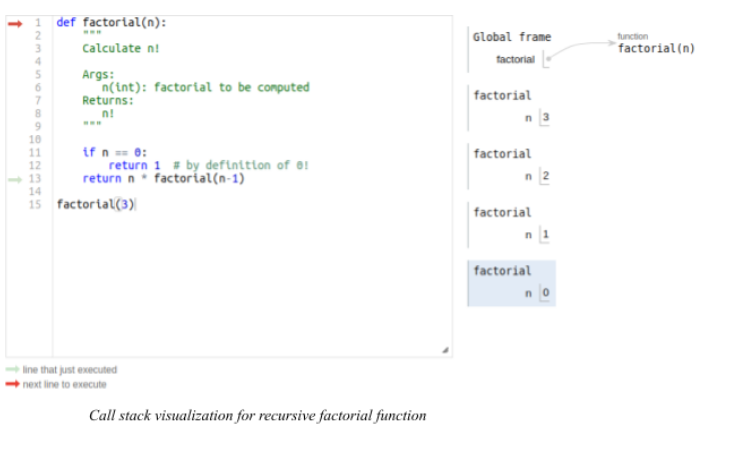
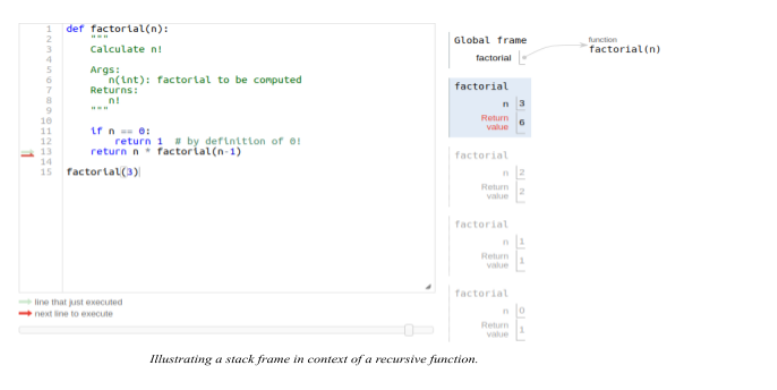
递归调用的堆栈框架是一个数据结构。它包含了特定函数调用时的函数调用参数变量。它持有递归函数在一个实例中的状态,并带有特定的参数。
正如下面所强调的,每次连续调用的返回值根据递归调用中传递的参数而变化。
当参数为0时,返回值为1;当参数为1时,返回值为1,以此类推,直到初始参数为3,其返回值为6。
递归的类型
主要有两种类型的递归。这些类型是直接递归和间接递归。
对于直接递归,递归调用是明确声明的(见下面的代码片断)。
def direct_recursion(n):
if n == 0:
return 0
return direct_recursion(n-1)
direct_recursion(4)
然而,在间接递归中,递归函数调用另一个函数,而后者又调用它。
例如,我们定义了一个名为indirect_recursion(n) 的新函数*。 indirect_recursion(n* ) 调用一个名为other_function(3)的函数。在other_function(n) 里面我们再次调用indirect_recursion(n )。
这是一个间接递归的例子。
def indirect_recursion(n):
if n == 0:
return 0
return n - other_function(n-1)
def other_function(n):
if n > 0:
n -= 2
return indirect_recursion(n)
indirect_recursion(3)
除了上述情况,还有其他类型的递归。
还有尾部递归和头部递归。
- 头部递归,是指递归调用在一个函数的开头。
- 尾部递归,顾名思义是指递归调用在函数的最后一行的情况。
在上面的直接递归片段中,函数的最后一行是唯一的递归调用。
这就是一个尾部递归函数的例子。因此,尾部递归是直接递归类型的一个特殊例子。
注意,在我们的递归因子函数中,最后一行包含递归调用。但是,它没有资格成为尾递归。这是因为该函数的最后一个操作是乘法。
尾部调用的优化
尾部调用不是递归函数所特有的。
它指的是一个函数或过程最终执行的最后一个动作。
如上所述,如果最后的动作是递归的,那么尾部调用可以是一个尾部递归。
一些编程语言,如scheme,设置了尾部调用优化。尾部调用优化确保了堆栈空间的持续使用。在("尾部调用 "2022)中,尾部调用优化,调用堆栈不再接收堆栈帧。
由于大部分当前函数状态不再需要,因此被尾部调用的堆栈帧所取代。
正如在递归函数背景下的堆栈帧的图像说明中所强调的*。*而不是每次调用都产生一个新的堆栈框架。这是通过修改当前的框架来实现的,以便与当前的参数保持一致。这是一个强大的技术,可以节约内存。
因此,在尾部递归函数的情况下防止堆栈溢出。正如这个答案中所强调的(Cronin 2008)。对于任何值的参数,递归阶乘函数所需的空间量是恒定的。
Python中的尾部调用优化
在设计上,Python 与像 scheme 这样的语言不同,不支持尾部调用优化。
对于所有的尾部调用,包括尾部递归调用,都是如此。其主要原因是 python 强调要有完整的调试信息。这种调试信息依赖于堆栈跟踪。
我们通过实施尾部调用优化,在丢弃的堆栈中失去了调试信息。这使得堆栈跟踪毫无用处。
目前,Python默认允许1000次递归调用。 超过这些调用后,Python会引发一个RecursionError: 超过了最大的递归深度。
如何在Python中获得你系统中的当前递归限制?
下面的代码列表显示了如何找出你系统中的当前递归限制。
import sys
print(sys.getrecursionlimit())
默认值通常是1000,但这取决于运行中的设置。
在我目前使用Anaconda的设置中,递归限制是3000。
递归限制是指python在递归时允许的函数调用的数量。
如何设置Python中的递归限制?
我们可以改变递归限制。通过添加以下代码,我们摆脱了 递归错误(RecursionError 如果解决方案在设定的限制范围内,就可以摆脱
sys.setrecursionlimit(3500)
值得注意的是,增加递归限制并不改变C栈的大小。
因此,即使增加限制,堆栈溢出仍然可能发生,因为限制是防止堆栈溢出的安全措施。
更好的选择可能是重构解决方案。例如,使用循环和其他内置Python序列的迭代解决方案。
