SQL(结构化 查询语言)是一种ANSI/ISO标准的编程语言,旨在为关系型数据库编程,而T-SQL(Transact-SQL)是微软SQL Server数据库的SQL的扩展实现。当数据库人员想要编程或管理SQL Server数据库时,T-SQL被高度使用。然而,初学者在用SQL写查询时可能会不自觉地犯一些错误。在本文的下一节中,我们将看一下新手可能犯的常见错误。
前提条件
在本文的例子中,我们将使用以下表格,并使用Adventureworks2019的样本数据库。
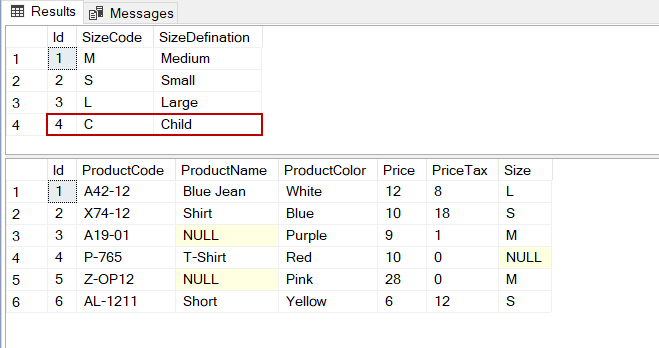
CREATE TABLE Products (
Id INT IDENTITY(1, 1) PRIMARY KEY
,ProductCode VARCHAR(100)
,ProductName VARCHAR(100)
,ProductColor VARCHAR(50)
,Price INT
,PriceTax INT
,Size VARCHAR(1)
)
INSERT INTO Products
VALUES ('A42-12','Blue Jean','White',12,8,'L')
, ('X74-12','Shirt','Blue',10,18,'S')
, ('A19-01',NULL,'Purple',9,1,'M')
, ('P-765','T-Shirt','Red',10,0,NULL)
, ('Z-OP12',NULL,'Pink',28,0,'M')
, ('AL-1211','Short','Yellow',6,12,'S')
CREATE TABLE SizeTable(
[Id] [int] IDENTITY(1,1) PRIMARY KEY NOT NULL,
[SizeCode] [varchar](1) NULL,
[SizeDefination] [varchar](100) NULL)
INSERT INTO SizeTable
VALUES ('M','Medium') ,('S','Small'),('L','Large'),('C','Child')
计算SQL的NULL值
NULL值指定了一个未知的值,但这个未知的值并不等同于一个零值或一个包含空格的字段。该 COUNT() 函数返回查询结果集中的行数。然而,当我们用一个特定的列名使用这个函数时,它在执行计数操作时忽略了NULL值。让我们考虑下面这个简单的例子。
SELECT * FROM Products
SELECT COUNT(ProductName) AS 'Number Of Product' FROM Products
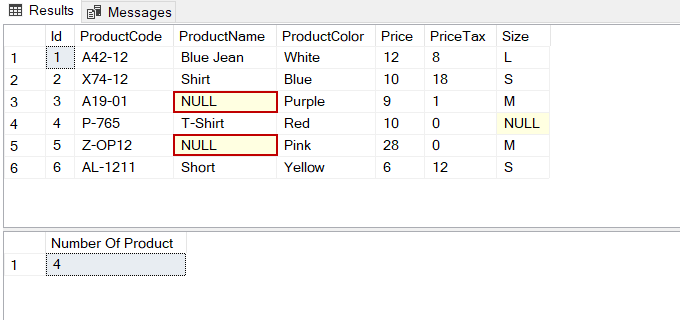
我们可以看到ProductName列包括两个NULL值,但是count函数并没有计算这些行。我们可以使用ISNULL函数将这些NULL值纳入计数操作中。
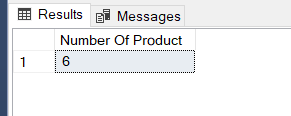
SELECT COUNT(ISNULL(ProductName,'')) AS 'Number Of Product' FROM Products
避免除以零错误的风险
在T-SQL查询中,我们可以将一个列的值除以另一个列。在这一点上,我们需要考虑除数列值,因为当一个数字被除以0时,结果是未定义的,查询会返回除以0的错误。
SELECT ProductName
, Price
, (Price / PriceTax) * 100 AS [PriceTaxRatio]
FROM Products
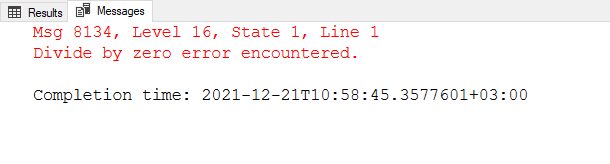
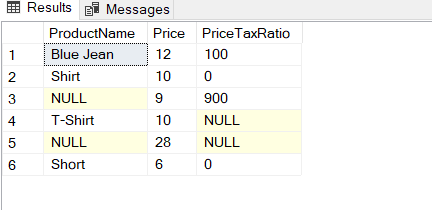
在执行查询后,由于PriceTax列的一些零值,发生了一个错误。为了解决这个问题,我们可以对除数列使用NULLIF函数。NULLIF函数需要两个参数,如果这些参数相等,则返回一个NULL值。这样,零除法的结果将等于NULL,而不是返回一个错误。
SELECT ProductName
, Price
, (Price / NULLIF(PriceTax,0)) * 100 AS [PriceTaxRatio]
FROM Products
不要使用 "+"运算符来连接表达式
加号可能被用来组合字符串列的值,但是如果这些列的任何一行包括一个NULL值,结果将是NULL。这种情况在下面的查询结果中可以清楚地看到,一些长的产品名称结果是NULL,因为产品的名称是NULL。
SELECT ProductName, ProductColor ,
ProductName + '-' + ProductColor AS [Long Product Name]
FROM Products

我们需要使用 CONCAT 函数,而不是使用 "+"运算符来合并字符串。CONCAT函数接收一组字符串参数并返回这些参数的组合形式。
SELECT ProductName, ProductColor ,
CONCAT(ProductName , '-' , ProductColor) AS [Long Product Name]
FROM Products

正如我们所看到的,CONCAT函数在组合字符串表达式时忽略了NULL值。同时,如果我们想用一个分隔符来分隔组合的表达式,我们可以使用CONCAT_WS函数。
SELECT ProductName, ProductColor ,
CONCAT_WS( '-',ProductName , ProductColor) AS [Long Product Name]
FROM Products

在T-SQL查询中明确定义列名
星号(*)可以用来返回一个表或连接表的全部列。不必要的使用星号符号会导致查询中的一些性能问题。
- 导致更多的网络流量
- 导致多余的I/O操作
除了这些性能问题,阅读和维护T-SQL代码将变得更加困难,需要更多的时间,因为解释哪些列是应用程序需要的,不容易理解。
在没有明确定义列名的情况下,我们将提到的第二个不正确的用法是在ORDER BY之后使用列的位置号。列的位置号可以在T-SQL查询中的ORDER BY子句之后使用。在这种用法中,SQL Server会根据位置号指定的列对查询的结果集进行排序。
SELECT ProductCode, Price FROM Products
ORDER BY 2
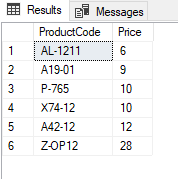
查询结果根据Price列以升序方式排序,因为该列被放在查询结果的第二个位置。这种使用类型的主要缺点是降低代码的可读性。由于这个问题,在ORDER BY子句后明确定义列名将使查询获得更多的可读性。
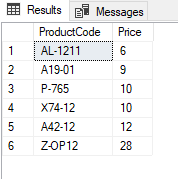
SELECT ProductName, Price FROM Products
ORDER BY Price ASC
不对可忽略的列使用NOT IN操作符
NOT IN操作符是用来从一个列表或子查询数据集中过滤出不匹配的记录值。然而,NOT IN操作符不能正确处理NULL值,因为与任何值比较的NULL结果总是NULL。当我们想获得产品表中没有尺寸代码的行的列表时,我们可以考虑使用下面的查询。
SELECT * FROM Products
WHERE Size NOT IN (SELECT
SizeCode FROM SizeTable)
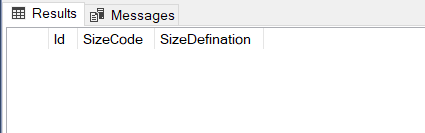
该查询没有返回任何行,但我们已经预料到它将返回图片中的画好的行。这个问题的原因与Size!=NULL表达式的结果总是NULL有关,因此整个WHERE子句总是FALSE。
SELECT * FROM SizeTable
WHERE SizeCode!= NULL
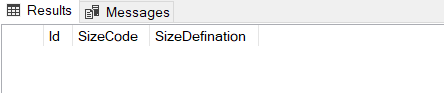
我们可以使用NOT EXIST操作符来克服这个问题。
SELECT * FROM SizeTable AS S
WHERE
NOT EXISTS (SELECT * From Products AS P
WHERE S.SizeCode = P.Size)
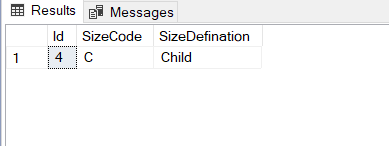
避免T-SQL查询中的隐性转换
在执行T-SQL查询的过程中,当SQL Server比较不同的数据类型值时,可以将一种数据类型转换为另一种。这种操作被称为隐式转换,隐式转换会对查询的性能产生负面影响,因为数据转换操作是针对查询的所有行进行的,需要一些资源。下面的示例查询正在比较数据类型为varchar的列和数据类型为int的列。
SELECT ProductCode, Price FROM Products WHERE Price>'1'
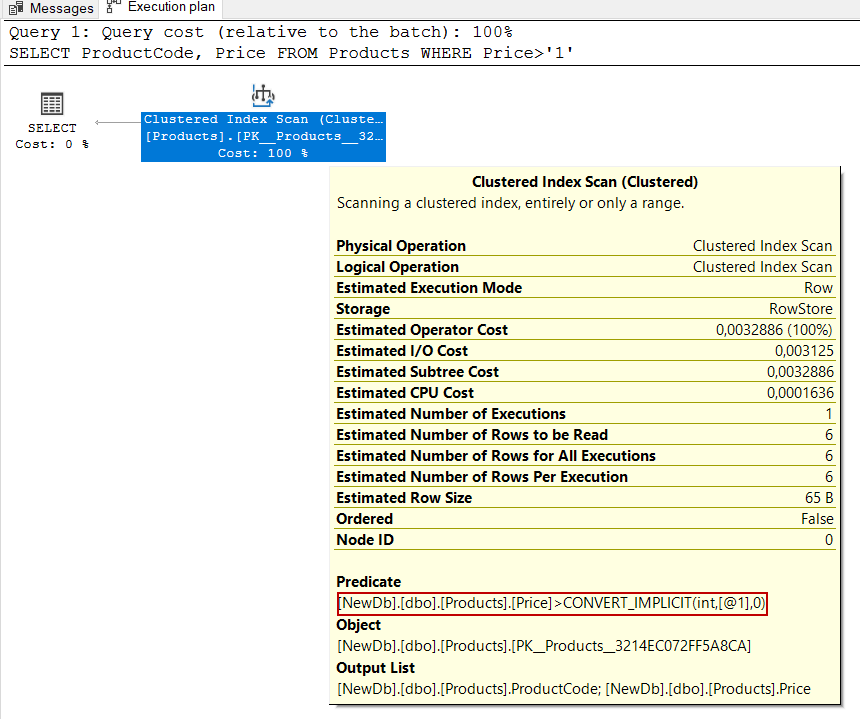
我们可以在查询的执行计划的细节上看到隐式转换。
隐式转换对查询计划的影响
SQL Server的查询优化器是面向成本的。首先,优化器使用统计数据估计一个查询可以返回多少行,然后为执行的T-SQL查询生成各种查询计划候选。在最后一步,它使用执行查询成本最低的查询计划。隐式转换可能会导致优化器生成非最佳的查询计划,因为优化器不能准确地预测从一个查询中可以返回的行数。现在,我们将分析下面的查询执行计划。
SELECT NationalIDNumber FROM HumanResources.Employee
WHERE NationalIDNumber = 14417807
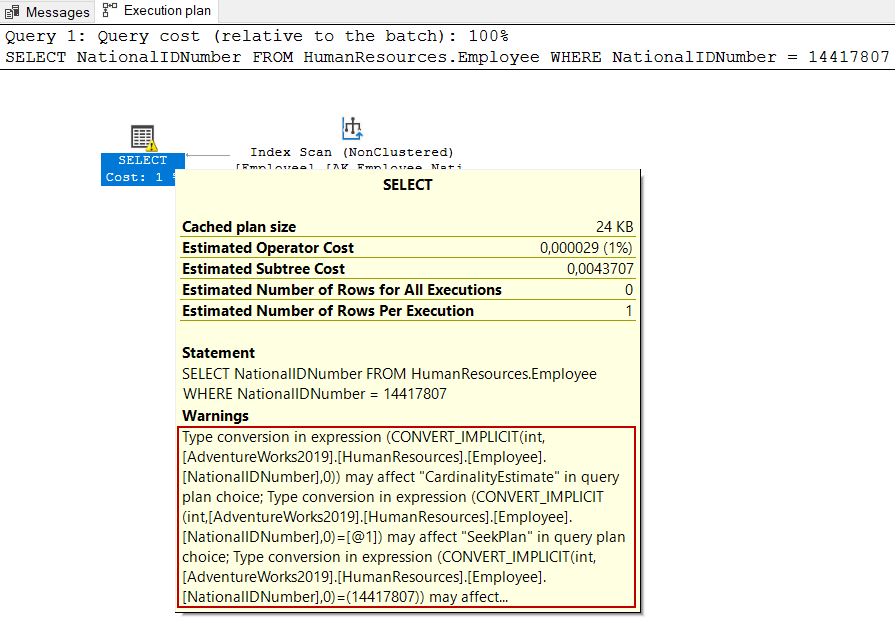
警告标志表明在查询中存在一个隐含的转换,这可能导致使用一个非最佳的查询计划。现在,我们将把WHERE表达式转换为适当的数据类型,并再次执行相同的查询。
SELECT NationalIDNumber FROM HumanResources.Employee
WHERE NationalIDNumber = N'14417807'
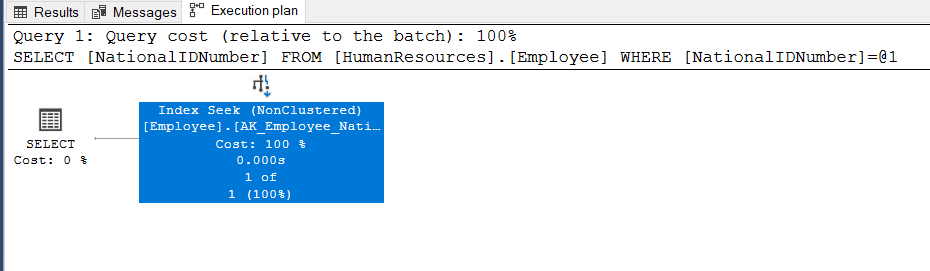
在数据类型改变后,优化器产生了最佳的查询计划,因为索引查找操作允许直接访问匹配的行。
注意不可收费谓词的副作用
SQL Server可以通过索引寻址操作更有效地访问符合过滤条件的行。然而,如果一个函数在WHERE子句里面,即使存在一个合适的索引,查询优化器也不能决定使用索引查找操作。这些类型的查询被称为非可收费查询。下面的查询是不可收费的。
SELECT SalesOrderDetailID ,ModifiedDate FROM Sales.SalesOrderDetail
WHERE YEAR(ModifiedDate)=2011
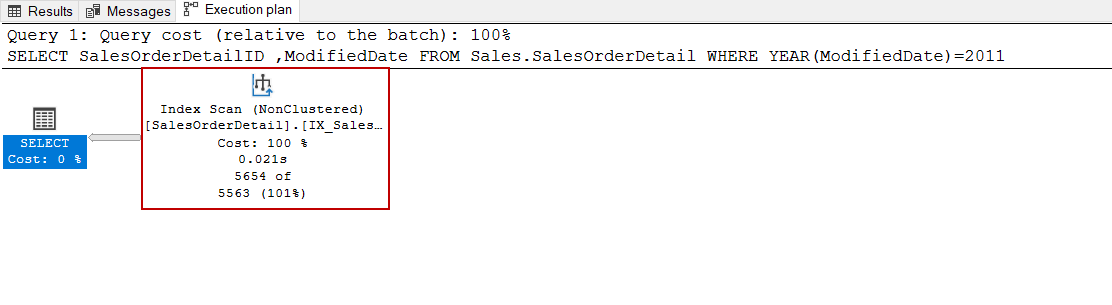
为这个查询创建一个索引不会改变它的性能,但我们还是要试一下。
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ModifiedDate
ON [Sales].[SalesOrderDetail] ([ModifiedDate])
创建索引后,我们重新执行了相同的查询,但是执行计划没有改变。
SELECT SalesOrderDetailID ,ModifiedDate FROM Sales.SalesOrderDetail
WHERE YEAR(ModifiedDate)=2011
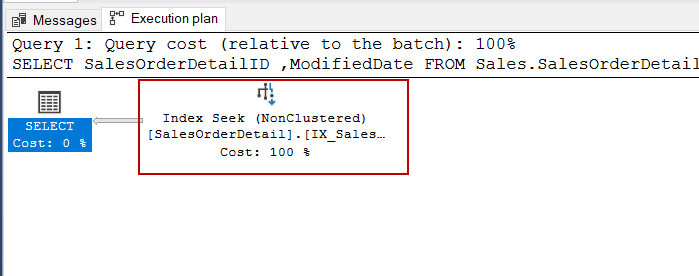
为了摆脱这个问题,我们可以在查询的WHERE子句中做一个小小的转换。我们将不使用YEAR函数,而是为指定的年份设置一个日期范围。
SELECT SalesOrderDetailID ,ModifiedDate FROM Sales.SalesOrderDetail
WHERE ModifiedDate >= '01-01-2011'
AND ModifiedDate < '01-01-2012'