

如何在 Python 中使用一个任意的条件来过滤一个列表?最pythonic和高效的方法是使用列表理解[x for x in list if condition] 来过滤一个列表的所有元素。
用列表理解法进行过滤
在我看来,过滤列表的最Pythonic方式是列表理解语句[x for x in list if condition] 。你可以用x 中任何你想用作过滤条件的函数来替换该条件。
例如,如果你想过滤掉所有小于10的项目,你可以使用列表理解语句[x for x in list if x<10] ,创建一个新的列表,其中包含所有小于10的列表项目。
这里有三个过滤列表的例子。
- 获得小于8的元素:
[x for x in lst if x<8]。 - 获取偶数元素:
[x for x in lst if x%2==0]。 - 获得奇数元素:
[x for x in lst if x%2]。
lst = [8, 2, 6, 4, 3, 1]
# Filter all elements <8
small = [x for x in lst if x<8]
print(small)
# Filter all even elements
even = [x for x in lst if x%2==0]
print(even)
# Filter all odd elements
odd = [x for x in lst if x%2]
print(odd)
其结果是。
# Elements <8
[2, 6, 4, 3, 1]
# Even Elements
[8, 2, 6, 4]
# Odd Elements
[3, 1]
这是最有效的过滤列表的方法,也是最pythonic的方法。但如果你正在寻找替代方案,请继续阅读,因为我将在这个全面的指南中解释Python列表过滤的每一个细微差别。
用 filter() 在 Python 中过滤一个列表
函数filter(function, iterable) ,作为输入,接收一个参数(一个列表项),并返回一个关于这个列表项是否应该通过过滤器的布尔值。所有通过过滤器的项目将作为一个新的对象(过滤器对象)返回。 [iterable](https://blog.finxter.com/iterators-iterables-and-itertools/)(一个过滤器对象)。
你可以使用一个函数声明lambda ,在你作为参数传递的地方直接创建函数。lambda函数的语法是lambda x: expression,意味着你用x作为输入参数,返回表达式作为结果(可能用x来决定返回值,也可能不用)。更多信息,请参阅我关于lambda函数的详细博文。
lst = [8, 2, 6, 4, 3, 1]
# Filter all elements <8
small = filter(lambda x: x<8, lst)
print(list(small))
# Filter all even elements
even = filter(lambda x: x%2==0, lst)
print(list(even))
# Filter all odd elements
odd = filter(lambda x: x%2, lst)
print(list(odd))
其结果是。
# Elements <8
[2, 6, 4, 3, 1]
# Even Elements
[8, 2, 6, 4]
# Odd Elements
[3, 1]
该函数filter() ,返回一个可迭代的过滤器对象。要将其转换为一个列表,请使用构造函数 [list(...)](https://blog.finxter.com/python-list/).
相关文章。
在Python中用map()过滤一个列表。
我添加这个选项只是因为有些人仍然试图使用map() 功能来过滤列表中的项目。这显然是错误的做法。原因是 [map()](https://blog.finxter.com/daily-python-puzzle-string-encrpytion-ord-function-map-function/)只允许你将一个列表中的每个元素转化为一个新的元素。但你仍然会有相同数量的元素在列表中。因此,你需要一个额外的步骤来过滤所有的元素(例如,使用列表理解)。但是,如果你愿意多走这一步,你也可以在一开始就使用列表理解来过滤。
这就是我的意思。
lst = [8, 2, 6, 4, 3, 1]
# Filter all elements <8
small = list(map(lambda x: x if x<8 else None, lst))
small = [x for x in small if x!=None]
print(small)
# Filter all even elements
even = list(map(lambda x: x if x%2==0 else None, lst))
even = [x for x in even if x!=None]
print(even)
# Filter all odd elements
odd = list(map(lambda x: x if x%2 else None, lst))
odd = [x for x in odd if x!=None]
print(odd)
其结果又是一样的。
[2, 6, 4, 3, 1]
[8, 2, 6, 4]
[3, 1]
但得到这个结果的方法显然是低效的,也是不可读的。
相关文章。
在Python中用生成器过滤一个列表
生成器表达式在一个值的序列上创建一个迭代器。它的工作原理与列表理解一样,但没有创建一个列表数据类型。这样做的效率更高一些。
你可以在任何需要迭代器作为输入的函数调用中使用生成器表达式。例如,如果你想计算一个列表中满足某个条件的所有数值的总和。
- 首先,确定满足特定条件的值的可迭代性。
- 第二,用函数将所有这些值加起来
[sum()](https://blog.finxter.com/python-sum/).
下面是一个代码例子,显示了如何使用生成器表达式过滤掉非整数,对一个列表中的所有整数值进行求和(而忽略其余的)。
lst = [6, 8, 2, 8, 'Alice']
print(sum(x for x in lst if type(x) == int))
# 24
检查 [type(x)](https://blog.finxter.com/python-type/)的每个元素,并将其与整数类型进行比较。如果该元素实际上是整数类型,则该比较返回True。
在Python中用一个条件过滤一个列表
你可以在一个列表项上定义任何复杂的条件来决定是否过滤它。只要创建你自己的函数(例如condition(x) ),将一个列表项作为输入,如果满足条件则返回布尔值True ,否则返回False 。
下面是一些示例代码。
def condition(x):
'''Define your arbitrarily
complicated condition here'''
return x<10 and x>0
lst = [11, 14, 3, 0, -1, -3]
# Filter out all elements that do
# not meet condition
filtered = [x for x in lst if condition(x)]
print(filtered)
# [3]
所有小于10和大于0的元素都包括在过滤的列表中。因此,只剩下元素3了。
在Python中用多个条件过滤一个列表
如果你想结合多个条件,也同样适用。假设你想过滤所有的元素x>9 和x<1 。这是两个(简单的)条件。你可以在一个列表项上定义任何复杂的条件来决定是否进行过滤。只要创建你自己的函数(例如condition(x) ),将一个列表项作为输入,如果满足条件则返回布尔值 True,否则返回 False。
下面是和以前一样的代码例子。
def condition(x):
'''Define your arbitrarily
complicated condition here'''
return x<10 and x>0
lst = [11, 14, 3, 0, -1, -3]
# Filter out all elements that do
# not meet condition
filtered = [x for x in lst if condition(x)]
print(filtered)
# [3]
所有小于10和大于0的元素都包括在过滤的列表中。因此,只剩下元素3了。
在Python中用Regex过滤一个列表
问题:给定一个字符串列表,如何过滤掉符合某个正则表达式的字符串?
例子:假设你有一个列表['Alice', 'Anne', 'Ann', 'Tom'] ,你想舍弃不符合重码模式的元素'A.*e' 。你希望过滤后的列表是['Alice', 'Anne'] 。
解决方案:使用列表理解过滤框架[x for x in list if match] ,过滤掉所有不匹配给定字符串的元素。
import re
# Define the list and the regex pattern to match
customers = ['Alice', 'Anne', 'Ann', 'Tom']
pattern = 'A.*e'
# Filter out all elements that match the pattern
filtered = [x for x in customers if re.match(pattern, x)]
print(filtered)
# ['Alice', 'Anne']
使用re.match() 方法,如果有一个匹配对象,则返回一个匹配对象,否则返回无。在Python中,任何匹配对象都会评估为True(如果需要的话),只有少数例外(例如None ,0,0.0,等等)。如果你需要温习一下你对re.match() 函数的基本知识,请查看我的详细博文,它将带你一步步地了解这个强大的Python工具。
相关文章。
如何在 Python 中过滤一个列表?
简要回答:要通过对内部列表的条件来过滤列表,使用列表理解语句[x for x in list if condition(x)] ,用你的过滤条件替换condition(x) ,返回True ,以包括内部列表x ,否则False 。
列表属于Python中最重要的数据结构:每个专家级的程序员都对它们了如指掌。令人惊讶的是,即使是中级程序员也不知道过滤一个列表的最佳方法,更不用说在Python中过滤一个列表了。 本教程告诉你如何进行后者的操作
问题:比方说,你有一个列表。你想对列表进行过滤,以便只保留满足某个条件的内部列表。该条件是内列表的一个函数,例如内列表元素的平均数或总和。

例子:给定以下有每周温度测量的列表,以及每周的内部列表。
# Measurements of a temperature sensor (7 per week)
temperature = [[10, 8, 9, 12, 13, 7, 8], # week 1
[9, 9, 5, 6, 6, 9, 11], # week 2
[10, 8, 8, 5, 6, 3, 1]] # week 3
如何过滤掉平均温度值<8的最冷星期?这是你想要的结果。
print(cold_weeks)
# [[9, 9, 5, 6, 6, 9, 11], [10, 8, 8, 5, 6, 3, 1]]
有两种语义上相等的方法来实现这一点:列表理解和函数map()。
相关文章。
在Python中对字符串列表进行过滤
问题:给定一个字符串列表和一个搜索字符串,如何过滤出包含搜索字符串的字符串?
例子:假设你有一个列表['Alice', 'Anne', 'Ann', 'Tom'] ,你想获得所有包含子串'An' 的项目。你希望过滤后的列表是['Anne', 'Ann'] 。
解决方案:使用列表理解过滤方案[x for x in list if condition] ,放弃所有不包含其他字符串的项目。
import re
# Define the list
customers = ['Alice', 'Anne', 'Ann', 'Tom']
# Filter out all elements that contain 'An'
filtered = [x for x in customers if 'An' in x]
print(filtered)
# ['Anne', 'Ann']
使用基本的字符串成员操作"[in](https://blog.finxter.com/python-membership-in-operator/)"来检查一个元素是否通过过滤器。
在Python中过滤列表以去除空字符串
问题:给定一个字符串列表,如何删除所有空字符串?
例子:假设你有一个列表['Alice', 'Anne', '', 'Ann', '', 'Tom'] ,你想得到一个新的非空字符串的列表['Alice', 'Anne', 'Ann', 'Tom'] 。
解决方案:使用列表理解过滤方案[x for x in list if x] ,过滤掉所有空字符串。
import re
# Define the list
customers = ['Alice', 'Anne', '', 'Ann', '', 'Tom']
# Filter out all elements that contain 'An'
filtered = [x for x in customers if x]
print(filtered)
# ['Alice', 'Anne', 'Ann', 'Tom']
你利用了Python将布尔值False 赋给空字符串'' 的特点。
在Python中用enderswith()和startswith()过滤一个列表
问题:给定一个字符串列表,如何过滤掉以另一个字符串开始(或以另一个字符串结束)的字符串?换句话说,你想获得所有有另一个字符串作为前缀或后缀的字符串。
例如:假设你有一个列表['Alice', 'Anne', 'Ann', 'Tom'] ,你想获得所有以'An' 开始的项目。你希望过滤后的列表是['Anne', 'Ann'] 。
解决方案:使用列表理解过滤方案[x for x in list if x.startswith('An')] ,过滤所有以 'An'开始的元素。如果你想检查以另一个字符串结尾的字符串,你可以使用函数 [str.endswith()](https://blog.finxter.com/regex-endswith-python/)而代之以函数。
import re
# Define the list
customers = ['Alice', 'Anne', 'Ann', 'Tom']
# Filter out all elements that start with 'An'
filtered = [x for x in customers if x.startswith('An')]
print(filtered)
# ['Anne', 'Ann']
# Filter out all elements that end with 'e'
filtered = [x for x in customers if x.endswith('e')]
print(filtered)
# ['Alice', 'Anne']
使用函数startswith() 和endswith() 作为过滤条件。
在Python中用lambda过滤一个列表
函数filter(function, iterable) ,其参数是一个过滤函数,该函数接收一个列表项作为输入,如果满足条件,则返回布尔值True ,否则返回False。这个函数决定一个项目是否被包括在过滤的列表中。
为了定义这个函数,你可以使用关键字lambda。lambda函数是一个匿名函数:把它看作是一个被抛弃的函数,在代码中只需要作为一个参数,而不需要做其他事情。
这段代码显示了如何使用lambda函数来过滤一个列表并只返回列表中的奇数值。
# Create the list
lst = [1, 2, 3, 4]
# Get all odd values
print(list(filter(lambda x: x%2, lst)))
# [1, 3]
函数lambda x: x%2 ,接受一个参数x ,即要用过滤器检查的元素,并返回表达式的结果x%2 。如果整数是奇数,这个modulo表达式返回1,如果是偶数,返回0。因此,所有奇数元素都通过了测试。
在Python中用另一个列表过滤一个列表
问题:给定一个数值列表lst 和一个布尔运算列表filter 。如何用第二个列表过滤第一个列表?更具体地说,你想创建一个新的列表,包括i-th element oflst ,如果i-th element of filter是True 。
例子:这里有两个列表的例子。
lst = [1, 2, 3, 4]
filter_lst = [True, False, False, True]
而你想得到这份名单。
[1, 4]
解决方案:使用一个简单的列表理解语句[lst[i] for i in range(len(lst)) if filter_lst[i]] ,为每个索引i检查相应过滤器的布尔值是否为True 。在这种情况下,lst中索引为i 的项目被添加到新的过滤列表中。这就是代码。
lst = [1, 2, 3, 4]
filter_lst = [True, False, False, True]
res = [lst[i] for i in range(len(lst)) if filter_lst[i]]
print(res)
# [1, 4]
布尔列表作为一个 "掩码",决定哪个元素通过过滤器,哪个不通过。
另一种方法是使用zip() ,在不触及任何索引的情况下对多个序列进行迭代。
lst = [1, 2, 3, 4]
filter_lst = [True, False, False, True]
res = [x for (x, boo) in zip(lst, filter_lst) if boo]
print(res)
# [1, 4]
需要提高你对zip() 的理解吗?请查看我们的综合博文。
在Python中用索引过滤一个列表
问题:给定一个值的列表和一个索引的列表,如何在第二个列表中过滤所有有索引的元素?
例如:你有一个列表['Alice', 'Bob', 'Ann', 'Frank'] ,索引[1, 2] 。你要找的是过滤后的列表['Bob', 'Ann'] 。
解决方法:通过简单的列表理解语句[lst[i] for i in indices] ,遍历第二个列表的所有索引并包含相应的列表项。
lst = ['Alice', 'Bob', 'Ann', 'Frank']
indices = [1, 2]
res = [lst[i] for i in indices]
print(res)
# ['Bob', 'Ann']
只有指数为1和2的两个元素通过过滤器。
在Python中过滤一个字典列表
问题:给定一个字典的列表。每个字典由一个或多个(键,值)对组成。你想通过某个字典的键值*(属性*)来过滤它们。 你怎样才能实现这一点?
简约的例子:考虑下面的例子,你有三个用户字典,键是用户名,age 和play_time 。你想得到一个满足某个条件的所有用户的列表,比如play_time > 100 。这就是你所要实现的目标。
users = [{'username': 'alice', 'age': 23, 'play_time': 101},
{'username': 'bob', 'age': 31, 'play_time': 88},
{'username': 'ann', 'age': 25, 'play_time': 121},]
superplayers = # Filtering Magic Here
print(superplayers)
结果应该是这样的,其中play_time属性决定了一个字典是否通过过滤器,即play_time>100 。
[{'username': 'alice', 'age': 23, 'play_time': 101},{'username': 'ann', 'age': 25, 'play_time': 121}]
解决方案:使用列表理解 [x for x in lst if condition(x)] ,创建一个新的符合条件的字典列表。lst 中所有不符合条件的词典都被过滤掉了。你可以在列表的x 元素上定义你自己的条件。
这里的代码告诉你如何过滤掉所有不符合至少玩过100小时条件的用户字典。
users = [{'username': 'alice', 'age': 23, 'play_time': 101},
{'username': 'bob', 'age': 31, 'play_time': 88},
{'username': 'ann', 'age': 25, 'play_time': 121},]
superplayers = [user for user in users if user['play_time']>100]
print(superplayers)
输出是过滤后的符合条件的字典列表。
[{'username': 'alice', 'age': 23, 'play_time': 101},{'username': 'ann', 'age': 25, 'play_time': 121}]
芬克斯特博客上的相关文章。
在Python中过滤列表中的唯一项目--去除重复的项目
天真的做法是浏览每个元素,检查这个元素是否已经存在于列表中。如果是这样,就把它删除。然而,这需要几行代码。
一个更短、更简洁的方法是用列表项创建一个字典。列表中的每一项都成为一个新的字典键。所有多次出现的项目将被分配到同一个键。字典只包含唯一的键,不能有几个键是相同的。
作为字典值,你只需采取假的(默认)值。
相关的博客文章。
然后,只需将字典转换回列表,丢掉假值。由于字典中的键保持相同的顺序,原始列表项的顺序信息就不会丢失。
以下是代码。
>>> lst = [1, 1, 1, 3, 2, 5, 5, 2]
>>> dic = dict.fromkeys(lst)
>>> dic
{1: None, 3: None, 2: None, 5: None}
>>> duplicate_free = list(dic)
>>> duplicate_free
[1, 3, 2, 5]
Python过滤列表中的一个范围
过滤一个列表中在给定的开始和停止索引之间的数值范围内的所有元素。
lst = [3, 10, 3, 2, 5, 1, 11]
start, stop = 2, 9
filtered_lst = [x for x in lst if x>=start and x<=stop]
print(filtered_lst)
# [3, 3, 2, 5]
你使用条件x>=start 和x<=stop 来检查x元素的列表是否在[start, stop] 范围内。
在Python中用大于和小于过滤一个列表
过滤一个列表中大于给定y值的所有元素。
lst = [3, 10, 3, 2, 5, 1, 11]
y = 2
filtered_lst = [x for x in lst if x>y]
print(filtered_lst)
# [3, 10, 3, 5, 11]
使用条件x > y ,检查列表项x ,是否大于y。在前一种情况下,它被包括在过滤的列表中。在后者,它不是。
你可以通过使用列表理解语句[x for x in lst if x<y] ,对运算符小于 < ,使用同样的想法。
在Python中计算过滤的列表
在Python中,如何在某一条件下计算元素?例如,如果你想计算一个列表中的所有偶数值,或所有质数,或所有以某个字符开始的字符串,该怎么办?有多种方法可以实现这一点,让我们逐一讨论。
假设你对每个元素都有一个条件x 。让我们把它变成一个名字为condition(x) 的函数。你可以定义任何你想要的条件,只要把它放在你的函数中。例如,这个条件对所有大于整数10的元素返回True。
def condition(x):
return x > 10
print(condition(10))
# False
print(condition(2))
# False
print(condition(11))
# True
但你也可以定义更复杂的条件,如检查素数。
在Python中用if对列表进行计数
如果条件满足,你如何计算列表中的元素?
答案是使用一个简单的生成器表达式 sum(condition(x) for x in lst) 。
>>> def condition(x):
return x>10
>>> lst = [10, 11, 42, 1, 2, 3]
>>> sum(condition(x) for x in lst)
2
结果表明,有两个元素大于10。 你使用了一个生成器表达式,该表达式返回一个布尔运算的迭代器。请注意,布尔值 "真 "由整数值1表示,布尔值 "假 "由整数值0表示。所以你可以简单地计算所有布尔运算的总和,得到满足条件的元素数量。
在Python中用大于/小于对列表进行计数
如果你想确定大于或小于指定值的元素的数量,只需修改本例中的条件。
>>> def condition(x):
return x>10
>>> lst = [10, 11, 42, 1, 2, 3]
>>> sum(condition(x) for x in lst)
2
例如,要找到小于5的元素数,在生成器表达式中使用条件x<5 。
>>> lst = [10, 11, 42, 1, 2, 3]
>>> sum(x<5 for x in lst)
3
计算Python零/非零列表。
要计算一个给定列表中的零的数量,使用方法调用 [list.count(0)](https://blog.finxter.com/python-list-count/).
要计算一个给定的列表中的非零点的数量,你必须使用条件性计数,如上所述。
def condition(x):
return x!=0
lst = [10, 11, 42, 1, 2, 0, 0, 0]
print(sum(condition(x) for x in lst))
# 5
使用lambda + map的Python列表计数。
另一种方法是使用map和lambda函数的组合。
相关文章。
- [完整教程]map函数:操作一个可迭代的每个元素。
- [完整教程] Lambda函数:创建一个匿名函数。
以下是代码。
>>> sum(map(lambda x: x%2==0, [1, 2, 3, 4, 5]))
2
计算列表中偶数整数的数量。
- lambda函数为一个给定的元素返回一个布尔值
x。 - map函数将每个列表元素转化为一个布尔值(1或0)。
- 和函数将 "1 "相加。
其结果是条件评估为 "真 "的元素的数量。
在Python中通过字符串的长度过滤一个列表
给定一个字符串的列表,如何获得所有超过x个字符的元素?换句话说:如何通过字符串长度来过滤一个列表?
coders = ['Ann', 'Alice', 'Frank', 'Pit']
filtered = [x for x in coders if len(x)>3]
print(filtered)
# ['Alice', 'Frank']
列表理解语句[x for x in coders if len(x)>3]过滤掉所有长度超过三个字符的字符串。
在Python中从一个列表中过滤无元素
如何从一个列表中删除所有的无值?例如,你有一个列表['Alice', None, 'Ann', None, None, 'Bob'] ,你希望列表['Alice', 'Ann', 'Bob'] 。你如何做到这一点?
coders = ['Alice', None, 'Ann', None, None, 'Bob']
filtered = [x for x in coders if x]
print(filtered)
# ['Alice', 'Ann', 'Bob']
在Python中,每个元素都有一个与之相关的布尔值,所以你可以使用任何Python对象作为一个条件。值None ,与布尔值False 。
在Python中过滤一个JSON列表
问题:假设你有一个JSON列表对象。你想根据一个属性来过滤列表,如何做呢?
例子:给定以下JSON列表。
json = [
{
"user": "alice",
"type": "free"
},
{
"user": "ann",
"type": "paid"
},
{
"user": "bob",
"type": "paid"
}
]
你想找到所有账户类型为'paid' 的用户。
[ { "user": "ann", "type": "paid" }, { "user": "bob", "type": "paid" }]
解决方法:使用list comprehension[x for x in json if x['type']=='paid'] 来过滤列表,得到一个新的json列表,其中有通过过滤器的对象。
json = [ { "user": "alice", "type": "free" }, { "user": "ann", "type": "paid" }, { "user": "bob", "type": "paid" }]
filtered = [x for x in json if x['type']=='paid']
print(filtered)
# [{'user': 'ann', 'type': 'paid'},# {'user': 'bob', 'type': 'paid'}]
只有Ann和Bob拥有付费账户并通过了测试x['type']=='paid' 。
在Python中单行过滤一个列表
想在一行代码中通过一个给定的条件来过滤你的列表吗?使用列表理解语句[x for x in list if condition] ,其中条件部分可以是x上的任何布尔表达式。这个单行语句返回一个新的列表对象,其中包含所有通过 "测试 "过滤的项目。
下面是一个例子。
lst = ['Alice', 3, 5, 'Bob', 10]
# ONE-LINER:
f = [x for x in lst if type(x)==str]
print(f)
# ['Alice', 'Bob']
该语句过滤列表中的所有元素,并检查它们是否为字符串类型。如果它们是,它们就通过了测试,并被列入新的名单。
如果你喜欢单行语句,你会喜欢我的书Python One-Liner(NoStarch Press 2020)。它准确地告诉你如何编写Python代码,并将你的思考和编码压缩到最简约的形式。
如何在Python中有效地过滤一个列表:filter()与list comprehension的比较。
[Spoiler] 筛选列表时,哪种方法更快:filter() 还是列表理解?对于有一百万个项目的大型列表,用列表理解法过滤列表比内置的filter() 方法快40%。
为了回答这个问题,我写了一个简短的脚本,测试了使用filter() 和列表理解方法过滤越来越大的列表的运行时性能。
我的论点是,对于较大的列表大小,列表理解方法应该稍微快一些,因为它利用了cPython对列表理解的有效实现,不需要调用额外的函数。
我使用的笔记本电脑配备了英特尔(R)酷睿(TM)i7-8565U 1.8 GHz处理器(带涡轮增压功能,最高可达4.6 GHz)和8 GB内存。
然后我用这两种方法创建了100个列表,规模从10,000项到1,000,000项不等。作为元素,我只是将整数从0递增1。
这是我用来测量和表示结果的代码:哪种方法更快:filter() 还是列表理解?
import time
# Compare runtime of both methods
list_sizes = [i * 10000 for i in range(100)]
filter_runtimes = []
list_comp_runtimes = []
for size in list_sizes:
lst = list(range(size))
# Get time stamps
time_0 = time.time()
list(filter(lambda x: x%2, lst))
time_1 = time.time()
[x for x in lst if x%2]
time_2 = time.time()
# Calculate runtimes
filter_runtimes.append((size, time_1 - time_0))
list_comp_runtimes.append((size, time_2 - time_1))
# Plot everything
import matplotlib.pyplot as plt
import numpy as np
f_r = np.array(filter_runtimes)
l_r = np.array(list_comp_runtimes)
print(filter_runtimes)
print(list_comp_runtimes)
plt.plot(f_r[:,0], f_r[:,1], label='filter()')
plt.plot(l_r[:,0], l_r[:,1], label='list comprehension')
plt.xlabel('list size')
plt.ylabel('runtime (seconds)')
plt.legend()
plt.savefig('filter_list_comp.jpg')
plt.show()
该代码比较了filter() 函数和列表理解变体的执行时间,以过滤一个列表。注意,filter() 函数返回一个过滤器对象,所以你必须使用list() 构造函数将其转换为一个列表。
下面是比较两种方法的执行时间的结果图。在X轴上,你可以看到列表的大小从0到1,000,000项。在Y轴上,你可以看到执行各自函数所需的执行时间,单位是秒。
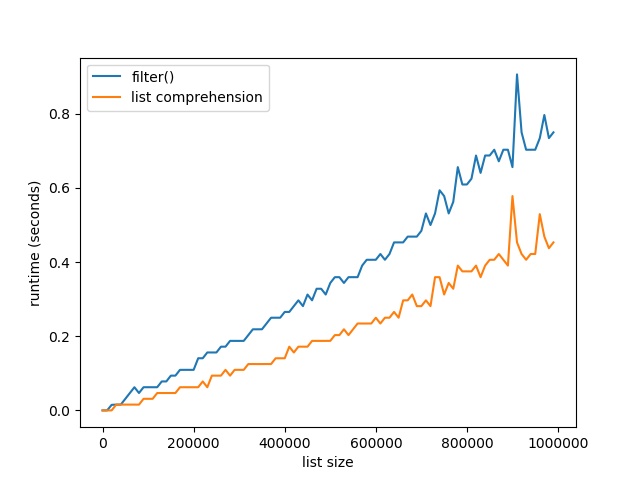
结果图显示,对于数以万计的项目,这两种方法都非常快。事实上,它们是如此之快,以至于时间模块的time() 功能无法捕捉到经过的时间。
但是当你把列表的大小增加到几十万个项目时,列表理解法开始获胜。
对于有一百万个项目的大型列表,用列表理解法过滤列表的速度比内置方法filter() 。
原因是列表理解语句的有效实现。然而,以下的观察是有趣的。如果你不把过滤函数转换为列表,你会得到以下结果。

突然间,函数filter() ,无论列表中有多少元素,其执行时间都接近0秒。 为什么会出现这种情况?
解释很简单:过滤器函数返回一个迭代器,而不是一个列表。迭代器不需要计算任何一个元素,直到它被要求计算元素next() 。因此,filter() 函数只有在需要时才计算下一个元素。只有当你把它转换为一个列表时,它才必须计算所有的值。否则,它不会事先计算任何数值。
今后的发展方向
本教程向你展示了Python中filter() 函数的来龙去脉,并将其与列表理解法的过滤方法进行了比较:[x for x in list if condition] 。你已经看到,后者不仅更具可读性和Pythonic性,而且速度也更快,所以采用列表理解的方法来过滤列表吧
如果你喜欢编程,并想在自己家里全职做这个工作,你很幸运。
