

[
关注
6月15日
-
10分钟阅读
用Plotly Dash建立一个通货膨胀跟踪仪表板

信用: Kenny Eliason
随着美国的通货膨胀率达到数十年来的高点,许多追踪价格的长期措施被经济观察家和政策制定者密切关注。即使是普通人也可以从了解最新的数据是否显示环境在改善或恶化中受益,以便他们能够相应地计划和预算他们的财务。然而,跟踪不同的通货膨胀措施可能很困难,如果能建立一个单一的仪表板来跟踪它们,那就更方便了。
值得庆幸的是,这一切都可以用Plotly Dash和一点点Python来完成。
第一步将是确保安装必要的Python库。虽然根据具体的目标,这些库中的一些 不是绝对必要的,但它们对于快速建立仪表盘的基础是有用的,可以在以后进行完善或调整。Dash还为应用程序的最终风格和布局提供了大量的控制。
这些Python库应该在继续进行之前安装。
这些都可以通过运行命令提示符和使用pip ,就像下面的例子一样,进行安装。
pip install dash
一旦所有的东西都安装好了,现在是时候为这个项目提供所需的数据来源了。
商品价格
第一步将是为整个项目编写所有必要的导入语句。创建这个Dash应用程序所需的一切都在下面列出。
import pandas as pdimport pandas_datareader as pdrimport plotly.express as pximport datetimefrom datetime import dateimport dashfrom dash import dcc, htmlfrom dash.dependencies import Output, Inputimport dash_bootstrap_components as dbcfrom bs4 import BeautifulSoupfrom urllib.request import Request, urlopen
从这里开始,是时候采购和建立不同的元素,这些元素将组合成仪表板。
开始和结束日期将需要被定义,因为许多正在采购的数据是历史数据,可以追溯到比需要的更远的地方。这个仪表板的主要目的是在COVID-19大流行之前、期间和之后跟踪相同的通货膨胀措施。为了做到这一点,开始日期将被定义为2019年3月,结束日期将是现在,因为经济仍处于大流行后的阶段。
start = datetime.datetime(2019, 3, 1)end = date.today()
在使用Pandas Datareader从雅虎财经等来源收集数据时,定义日期范围很有帮助。
仪表板的第一个组成部分是一个带有商品选择下拉菜单的线形图,追踪大多数主要商品的收盘价。追踪商品价格的意义在于,输入价格有助于成品价格的形成。在现实世界中,很少有商品广泛反弹而成品价格不随之上涨的情况。
com = pdr.DataReader(['GC=F', 'SI=F', 'PL=F', 'HG=F', 'PA=F', 'CL=F', 'HO=F', 'NG=F', 'RB=F', 'ZC=F', 'SB=F', 'ZO=F', 'ZS=F', 'LE=F', 'HE=F', 'CC=F', 'KC=F', 'CT=F', 'LBS=F'], 'yahoo', start, end)['Adj Close']
使用Pandas Datareader,可以使用每种商品的适当符号从雅虎财经收集商品的调整后收盘价。在结尾处定义'Adj Close' ,将确保只收集调整后的收盘价,而不是其他。
com = com.rename(columns={'GC=F': 'Gold', 'SI=F': 'Silver', 'PL=F': 'Platinum', 'HG=F': 'Copper', 'PA=F': 'Palladium', 'CL=F': 'Crude Oil', 'HO=F': 'Heating Oil', 'NG=F': 'Natural Gas', 'RB=F': 'Gasoline Futures', 'ZC=F': 'Corn', 'SB=F': 'Sugar', 'ZO=F': 'Oat', 'ZS=F': 'Soybean', 'LE=F': 'Live Cattle', 'HE=F': 'Lean Hogs', 'CC=F': 'Cocoa', 'KC=F': 'Coffee', 'CT=F': 'Cotton', 'LBS=F': 'Lumber'})
上面的代码将包含价格数据的每一列重命名为更方便用户的格式。它还使用.stack(),将数据框架从多指标重塑,并通过.rename(),将收盘价列重命名,使数据框架适合Plotly。这个可视化将在以后建立,因为它需要Dash Callbacks来完全发挥作用。
通过Pandas Datareader从Yahoo Finance获得的数据框架的初始形状
在应用.stack()和重设索引之后
汽油零售价格
汽油价格在塑造消费者情绪方面发挥着重要作用,因为每次人们出去开车时都能看到它们。由于一些原因,包括目前俄罗斯对乌克兰的入侵,汽油价格比前几年高得多。
美国汽车协会(AAA)跟踪汽油零售价格,并在其网站上公布了每日全国和各州的平均价格。通过网络刮取他们的州汽油价格平均值表,我们可以在仪表盘中加入一个汽油价格的全景图。
url = 'https://gasprices.aaa.com/state-gas-price-averages/'req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
上面的片段将AAA的州汽油价格平均表解析并加载为一个数据框架。请注意,必须设置'User-Agent' ,以使请求不出错。在这种情况下,'Mozilla/5.0' 工作得很好,数据几乎已经准备好用于可视化。
AAA网站上的表格
被网络抓取后的数据框架
为了让Plotly正确识别这些数据,我们仍然需要去掉每个价格前面的美元符号,用每个州名的缩写创建一个相应的列,并将价格列转换成float 数据类型。
def remove_dollar(sign): sign = sign.str.replace('$', '', regex=True) return sign
上面的函数将替换一个字符串中的任何美元符号。然而,在继续进行之前,它需要使用.apply() 应用于整个数据框架。
gas = gas.apply(remove_dollar)
接下来是用每个州的两个字母缩写创建一个列,因为Plotly会用这个方法识别位置。在这种情况下,它只需要一个包含每个州的名称和缩写的字典。
abbv = {'Alabama': 'AL', 'Alaska': 'AK', 'Arizona': 'AZ', 'Arkansas': 'AR', 'California': 'CA', 'Colorado': 'CO', 'Connecticut': 'CT', 'Delaware': 'DE', 'District of Columbia': 'DC', 'Florida': 'FL', 'Georgia': 'GA', 'Hawaii': 'HI', 'Idaho': 'ID', 'Illinois': 'IL', 'Indiana': 'IN', 'Iowa': 'IA', 'Kansas': 'KS', 'Kentucky': 'KY', 'Louisiana': 'LA', 'Maine': 'ME', 'Maryland': 'MD', 'Massachusetts': 'MA', 'Michigan': 'MI', 'Minnesota': 'MN', 'Mississippi': 'MS', 'Missouri': 'MO', 'Montana': 'MT', 'Nebraska': 'NE', 'Nevada': 'NV', 'New Hampshire': 'NH', 'New Jersey': 'NJ', 'New Mexico': 'NM', 'New York': 'NY', 'North Carolina': 'NC', 'North Dakota': 'ND', 'Ohio': 'OH', 'Oklahoma': 'OK', 'Oregon': 'OR', 'Pennsylvania': 'PA', 'Rhode Island': 'RI', 'South Carolina': 'SC', 'South Dakota': 'SD', 'Tennessee': 'TN', 'Texas': 'TX', 'Utah': 'UT', 'Vermont': 'VT', 'Virginia': 'VA', 'Washington': 'WA', 'West Virginia': 'WV', 'Wisconsin': 'WI', 'Wyoming': 'WY'}
通过使用.map() ,用每个州的相应缩写来创建一个新的列。
gas['Abbreviation'] = gas.State.map(abbv)
所有这些都完成后,最后一步将是确保每个价格栏只包含float ,并且价格被四舍五入到小数点后一位。
最后的结果
现在,圆形地图已经准备好被定义和构建。
fig2 = px.choropleth(gas, locations='Abbreviation', color='Regular', color_continuous_scale='spectral_r', locationmode='USA-states', scope='usa', title='Price of Regular Unleaded Gasoline', height=1000)
这个可视化的构建可以总结为三个步骤。首先,使用.choropleth() 来识别正在使用的Dataframe和地图的特征,如颜色、标题、范围和高度。第二,通过.add_scattergeo() 添加状态标签,在地图上撒上另一层视觉信息。第三,使用.update_layout() ,更新地图本身的标题和价格的颜色条,使其更加美观。
地图本身可以在下面的图片中看到,但仍有更多的内容可以添加到这个仪表板上......

价格通常在加州最高
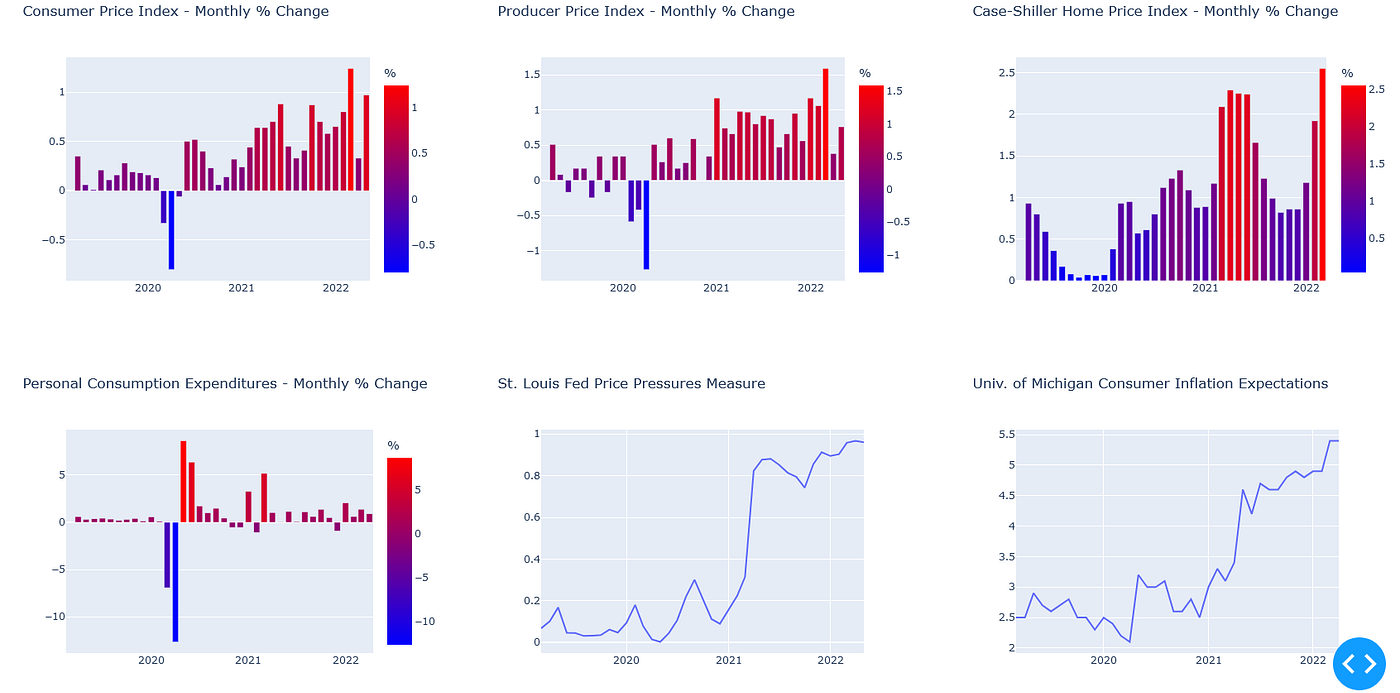
通货膨胀的主要宏观经济措施
在进入Dash应用程序本身的布局和创建之前,必须开发仪表板的最后一部分是一个2乘3配置的条形图和线形图,其中包含下面概述的一些最广泛关注的宏观经济通胀措施。
- 消费者价格指数
- 生产者价格指数
- 凯斯-席勒住房价格指数
- 个人消费支出
- 圣路易斯联储价格压力
- 密歇根大学消费者通胀预期
所有这些数据都可以通过Pandas Datareader使用圣路易斯联邦储备经济数据库(FRED)获得。就像股票和商品符号一样,FRED对每个指标都使用特定的代码。
代码在标题的最末尾的括号内
这些是上述相同的计量清单的六个独特代码,顺序相同。
- CPIAUCSL
- PPIFIS
- CSUSHPINSA
- PCE
- STLPPM
- 米歇尔
有了这些信息,我们就可以寻找我们所需要的数据,并在进一步研究之前进行一些轻微的数据处理。
除了密歇根大学的通胀预期和圣路易斯联储的价格压力之外,其余的数据通常是以月度和年度为基础进行衡量。这就是为什么要做一个新的栏目,应用.pct_change() ,以计算这些措施的每月百分比变化。
通过这些修改和列的重新命名,现在可以定义可视化了。
在创建每个可视化的过程中大多是重复的
当使用.bar() 来生成柱状图时,使用连续的色标来可视化每个数据点的相对高点和低点是有帮助的。
对于.line() 图表,没有那么多定制的需要,因为默认的Plotly设置对初学者来说已经足够了。
去掉x轴和y轴的标题可以消除一些不必要的杂乱,但不会使可视化的东西更难解释。
下面的图片展示了一旦成为仪表盘的一部分,最终的设置会是什么样子。
Dash Bootstrap布局和主题
虽然Dash作为一个框架,使基于数据的Web应用程序的创建更加简单,但这种简单性可以通过添加Dash Bootstrap组件来进一步提高。Bootstrap是基于行dbc.Row ,列dbc.Column ,包裹在一个容器dbc.Container ,所有这些都汇集在一起形成一个网格系统布局,从而实现了简单的风格设计。
在这个布局中,我们可以放置图形、文本、图像和其他组件。
要开始这样做,我们必须启动应用程序并声明一个主题。这个例子使用了这里的一个主题,但主题可以从任何地方获取。
在这个例子中使用主题FLATLY
meta_tags ,使应用程序能够响应,从而适应不同的屏幕尺寸并与移动设备兼容。
使用app.layout 和dbc.Container 是添加行和列之前的第一步。第一行只是一个带有仪表板标题的HTML标题。
app.layout = dbc.Container([
下一行有一个下拉和一个图表,分别使用dbc.Dropdown 和dbc.Graph 。
商品选择下拉菜单将加载每种商品的价格图表。
一旦启动并运行,下拉菜单将允许仪表板应用程序的用户从可用的商品中进行选择,并为他们的选择加载一个价格图表。id 和figure 行是需要注意的重要部分,因为它们将在最后的回调中使用。
dbc.Row( dbc.Col([ dcc.Graph(id='gas_map', figure=fig2) ]), justify='center' ),
接下来的三行只是零售天然气价格和宏观经济措施的脉络图。由于这些都不需要回调功能,所以没有什么需要做的了。
随着布局的完成,剩下的任务就是创建商品价格图和设置Dash应用程序能够在本地运行的条件。
回调和启动应用程序
@app.callback(Output('commodity-select', 'figure'), Input('drpdwn', 'value'))
回调函数使仪表盘具有反应性,其中用户可以选择一个输入组件,并根据改变的属性出现不同的输出。在上面的例子中,Output() ,根据从下拉菜单中通过Input() 选择的商品,生成一个新的价格图表。先前创建的数据框架,包括所有商品的收盘价,最后在这里被使用。
下拉菜单和价格图表一起工作
一切准备就绪后,只需再加两行就可以确保这个仪表盘可以在本地运行并在网络浏览器中测试。
if __name__ == "__main__": app.run_server(debug=True, port=8080)
现在它已经准备好运行了。如果所有的东西都被保存到一个.py 文件中,并且该文件被运行,应该有一个命令行消息确认Dash正在运行。
Dash是由Flask驱动的
将该地址插入同一台机器上的任何网络浏览器,就会像下面的图片一样加载仪表盘。
在调试模式下运行
多年来,除了经济学家之外,很少有人追踪通货膨胀数据,而且肯定不会成为头条新闻,因为并没有太多的超额通货膨胀发生。当经济按计划运行时,没有什么能成为新闻。然而,在过去的几年里,发生了一系列事件,通货膨胀成为每个人心中的话题。像这样的仪表盘可以帮助显示通货膨胀是在升温还是降温。把所有的数据放在一个地方当然不会有坏处,Plotly Dash让任何人都能做到这一点。
