

在本教程中,我将向你展示如何使用Sklearn predict方法来预测Python中机器学习模型的输出。
所以我将快速回顾该方法的作用,解释其语法,并展示一个如何使用该技术的例子。
如果你需要具体的东西,只需点击这里的相应链接。 该链接将带你到本教程的特定部分。
目录。
Sklearn Predict的快速介绍
为了理解Sklearn predict方法的作用,你需要了解整个机器学习过程。
创建和使用一个机器学习模型有几个阶段,但我们可以把它分成两个主要步骤。
- 训练模型
- 使用模型
当然,这比这更复杂一些。 我们经常需要评估模型,或者做一些小的改变或修改。
但在一个非常高的水平上,我们首先训练模型,然后我们可以使用模型来做事情。
通常情况下,我们使用模型来对输出进行预测,给定新的输入。
许多机器学习模型 "预测 "新的输出值
一旦经过训练,许多机器学习模型主要用于进行预测。
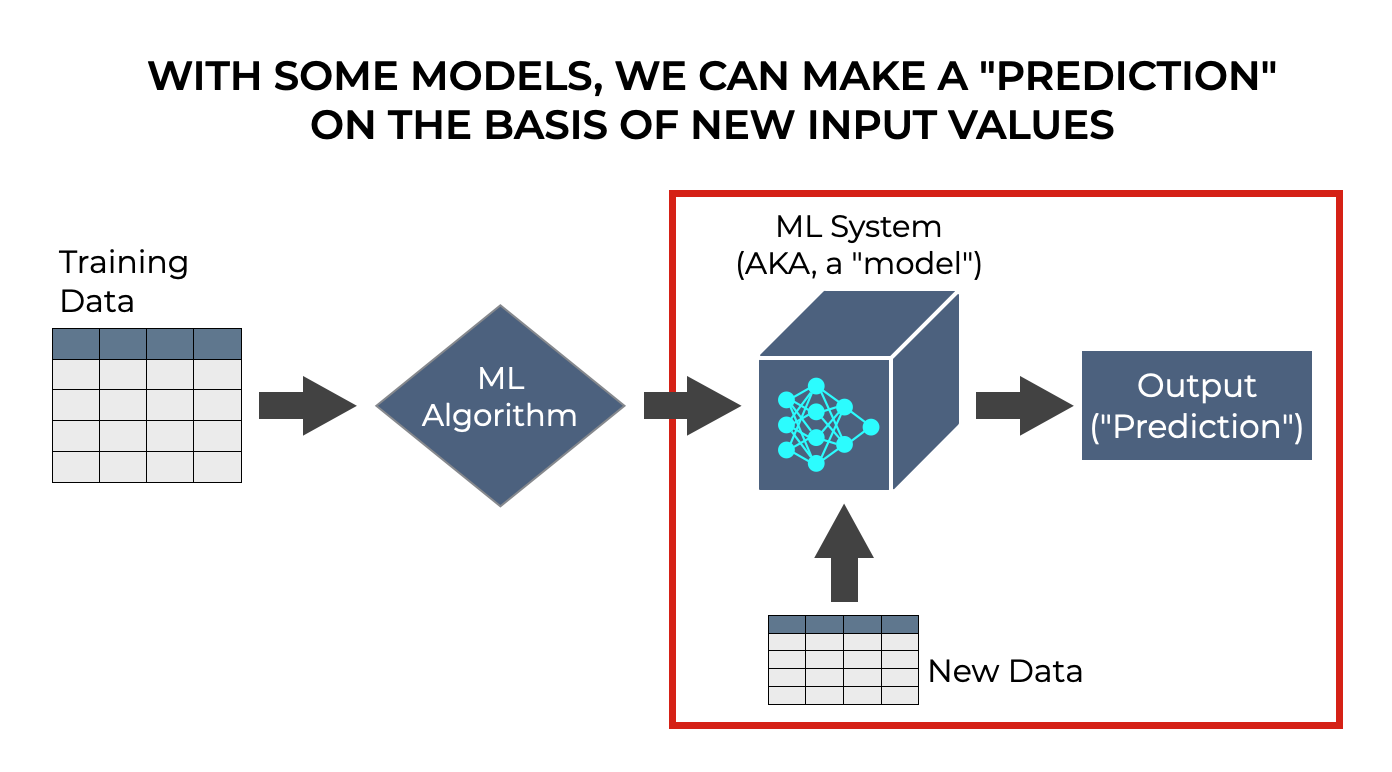
我们预测一个输出值,给定一组输入值。
因此,举例来说,我们有一个预测住房价格的模型。 输入值(通常称为特征),可能是像邮政编码、平方英尺、房间数量、浴室数量以及关于房屋的各种其他东西。
如果我们有这样一个已经被训练过的模型,那么我们可以提供新的输入数据,而模型应该产生一个输出。 它根据输入的数据,对房价进行 "预测"。
许多机器学习算法就是这样工作的。 我们可以使用机器学习系统对一些事情进行预测,比如。
- 预测一个人是否会对营销活动作出反应
- 预测一个电子邮件是否是 "垃圾 "信息
- 预测一个输入图片是猫还是狗
对于许多机器学习系统,包括回归和分类系统,其任务涉及到某种预测。
Sklearn的 "Predict "方法预测了一个产出
现在,让我们把这个问题带回scikit learn。
Scikit learn是一个用于Python的机器学习工具包。
既然如此,它提供了一套工具来做诸如训练和评估机器学习模型的事情。
一旦模型训练完成,它也有工具来预测输出值(对于真正进行预测的ML技术)。
这基本上就是predict() 方法所做的。 一旦模型被训练好,我们可以使用predict() ,在输入值的基础上预测一个输出值。
Sklearn Predict方法的语法
现在我们已经讨论了Sklearn预测方法的作用,让我们看看其语法。
提醒一下:这里的语法解释假定你已经导入了scikit-learn,并且你已经初始化了一个模型,比如LinearRegression ,RandomForestRegressor ,等等。
Sklearn'Predict'语法
当我们调用predict 方法时,我们需要从一个已经用训练数据训练过的机器学习模型的现有实例中调用它。例如,LinearRegression,LogisticRegression,DecisionTreeRegressor,SVM 都是scikit learn中有效的机器学习模型类型。
在你初始化和训练了模型之后,你可以使用 "dot "语法来调用预测方法。

在该方法的括号内,你提供新的输入数据的名称(即测试数据集的特征。 这个数据集通常被称为X_test 。
因此,举例来说,假设你正在用LinearRegression 的一个实例做普通线性回归。你已经用my_linear_regressor 的名字实例化了模型,并且你已经用Sklearn fit方法训练了这个模型。
然后要做一个新的预测,你可以使用代码。
my_linear_regressor.predict(X_test)
这很简单。
输入数据的格式
在我们继续前行之前,有一个最后的说明。
predict() 方法的输入--X测试数据--需要是二维的格式。 例如,它应该是一个二维的numpy数组。
如果你的X_test 数据不是二维格式的,你可能会得到一个错误。 在这种情况下,你需要将X_test 数据重塑为2维。
(我会在接下来的例子中这样做)。
例子:如何使用Sklearn Predict
现在我们已经研究了语法的工作原理,让我们通过一个例子来了解如何使用Sklearn预测。
在这个例子中,我将向你展示如何使用机器学习模型来进行 "预测"。当然,这是假设我们已经训练了模型,所以我们需要先训练模型。
说了这么多,这个例子有几个步骤。
步骤。
运行设置代码
在我们初始化、拟合或预测之前,我们需要运行一些设置代码。
我们需要
- 导入scikit-learn和其他软件包
- 创建一个训练数据集
- 初始化一个模型
让我们把这些都做了吧。
导入Scikit Learn和其他软件包
首先,让我们导入我们将使用的包。
我们将导入Scikit Learn、Numpy和Seaborn。
import sklearn
import numpy as np
import seaborn as sns
我们将使用Numpy来创建一个模拟的训练/测试数据集。 我们将使用Seaborn来实现数据的可视化。 显然,我们需要Scikit Learn来实际建立、拟合和预测一个模型。
创建训练数据
现在,我们将创建一个我们可以使用的数据集。
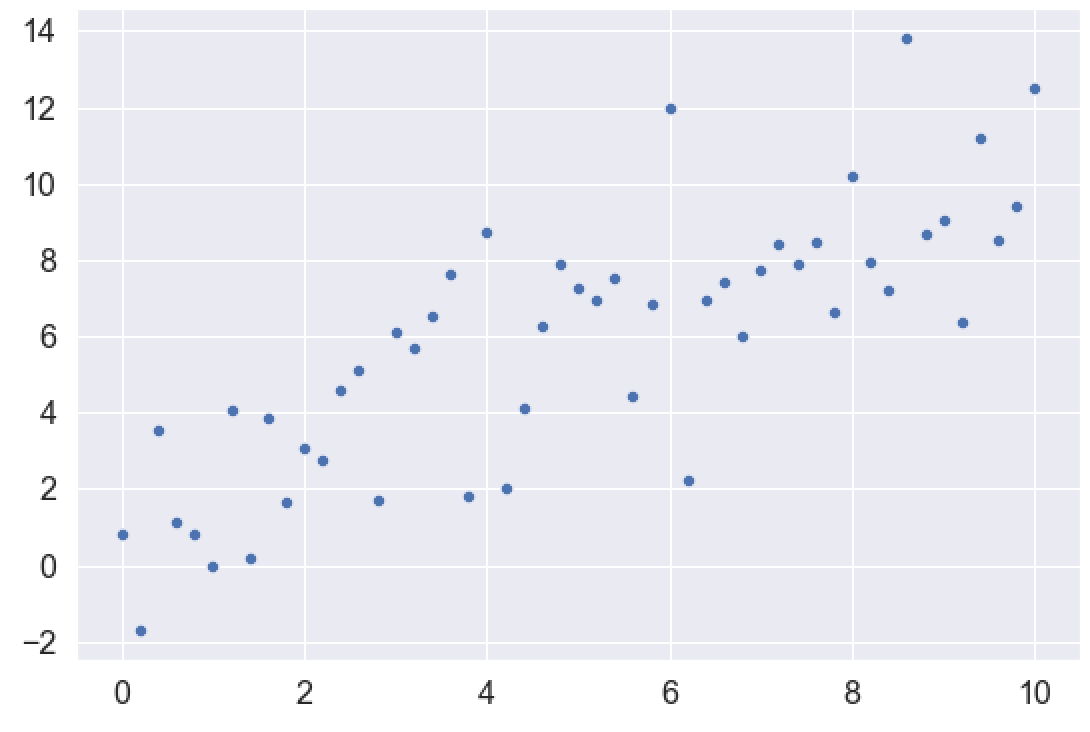
具体来说,我们要创建一个大致是线性的数据集,在Y值中加入一些噪音。
为了做到这一点,我们将使用Numpy linspace和Numpy random normal。
Numpy linspace将创建一个均匀分布的X轴变量。
而我们将创建一个与x轴变量线性相关的y轴变量,但我们将用Numpy随机正态加入一些随机正态噪声。注意,我们还将使用Numpy random seed来设置随机数发生器的种子。
observation_count = 51
x_var = np.linspace(start = 0, stop = 10, num = observation_count)
np.random.seed(22)
y_var = x_var + np.random.normal(size = observation_count, loc = 1, scale = 2)
一旦你运行这段代码,你会有两个变量。
- x_var
- y_var
我们可以用Seaborn绘制数据。
sns.scatterplot(x = x_var, y = y_var)
OUT。
分割数据
现在,让我们使用scikit learn中的train-test split函数,将我们的数据分成训练和测试数据。
from sklearn.model_selection import train_test_split
(X_train, X_test, y_train, y_test) = train_test_split(x_var, y_var, test_size = .2)
这就给了我们4个数据集。
- 训练特征(X_train)
- 训练目标(y_train)
- 测试特征(X_test)
- 测试目标(y_test)
初始化模型
接下来,我们将初始化一个模型对象。
在这个例子中,我们将使用Scikit Learn的LinearRegression 。
from sklearn.linear_model import LinearRegression
linear_regressor = LinearRegression()
在你运行之后,linear_regressor 是一个Sklearn模型对象。 有了这个模型对象,我们可以调用fit 方法,然后再调用predict 方法。
拟合模型
现在让我们在训练数据上拟合模型。
linear_regressor.fit(X_train.reshape(-1,1), y_train)
在这段代码中,我们要在训练数据上拟合我们的线性回归模型,X_train 和y_train 。
(注意:X_train已经被重塑为一个二维数组。 fit方法和predict方法期待二维输入数组)。
预测
现在我们已经训练了我们的回归模型,我们可以在新的输入值的基础上使用它来预测新的输出值。
要做到这一点,我们将用测试集的输入值调用predict() 方法,X_test 。(再次强调:我们需要使用Numpy reshape将输入值重塑为2D形状。)
让我们来做这件事。
linear_regressor.predict(X_test.reshape(-1,1))
OUT。
array([2.68333959, 7.55665544, 2.35845187, 8.20643088, 9.34353791,
5.76977296, 8.69376247, 2.84578345, 5.6073291 , 3.98289048,
4.79510979])
所以在这里,模型已经根据X_test 中的输入x轴值预测了输出y轴值。
然后我们可以将这些值与实际值进行比较,看看模型的表现如何。
在下面的评论中留下你的其他问题
你对Sklearn predict方法还有其他问题吗?
有什么是我漏掉的吗?
如果有,请在页面底部的评论区留下你的问题。
