本文已参与「新人创作礼」活动,一起开启掘金创作之路。
Introduction to RNN
在传统的前馈神经网络中,我们假定所有的输入(和输出)相互之间都是独立的。因此,前馈神经网络不能记住最近的历史训练信息,于是在处理序列模型时效果不佳。循环神经网络的提出就是为了解决这个问题的(Jordan et al. 1986, Elman et al. 1990)。RNN可以通过在隐藏层维护一个“状态向量”来充分利用序列的信息,状态向量可以隐式地包含序列中的所有元素。
RNN模型的输入是一个序列,这个模型一步处理序列中的一个元素。在计算完每一步后,更新的状态向量会传递给下一步的计算过程。下图是一个典型的RNN模型:
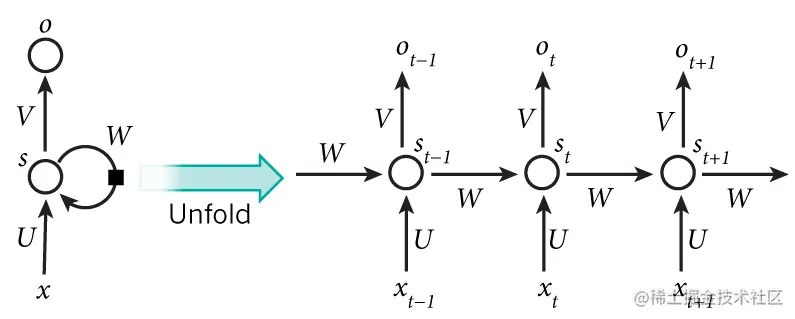
一个隐藏层单元数为1的RNN模型(左)以及它的在时间上的展开形式(右)
t时刻隐藏层的状态st 的输入来自t时刻的输入值xt 和t−1时刻的状态 st−1。 通过这种方式,RNN模型可将输入序列 {xt} 映射到输出序列 {ot}, 其中每个输出 ot 取决于所有的输入 xt′(t′≤t)
然而,理论和实践都表明RNN很难学习到长期的依赖关系(Bengio et al, 1994),因为当你利用基于梯度的方法来训练时,梯度会消失或爆炸。为了解决这个问题,一种更复杂的RNN模型——LSTM网络被提出来了.
Introduction to LSTM
所有的RNN都具有包含重复模块的链式结构网络。在RNN中,这种重复模块比较简单,例如通常为一个tanh函数。
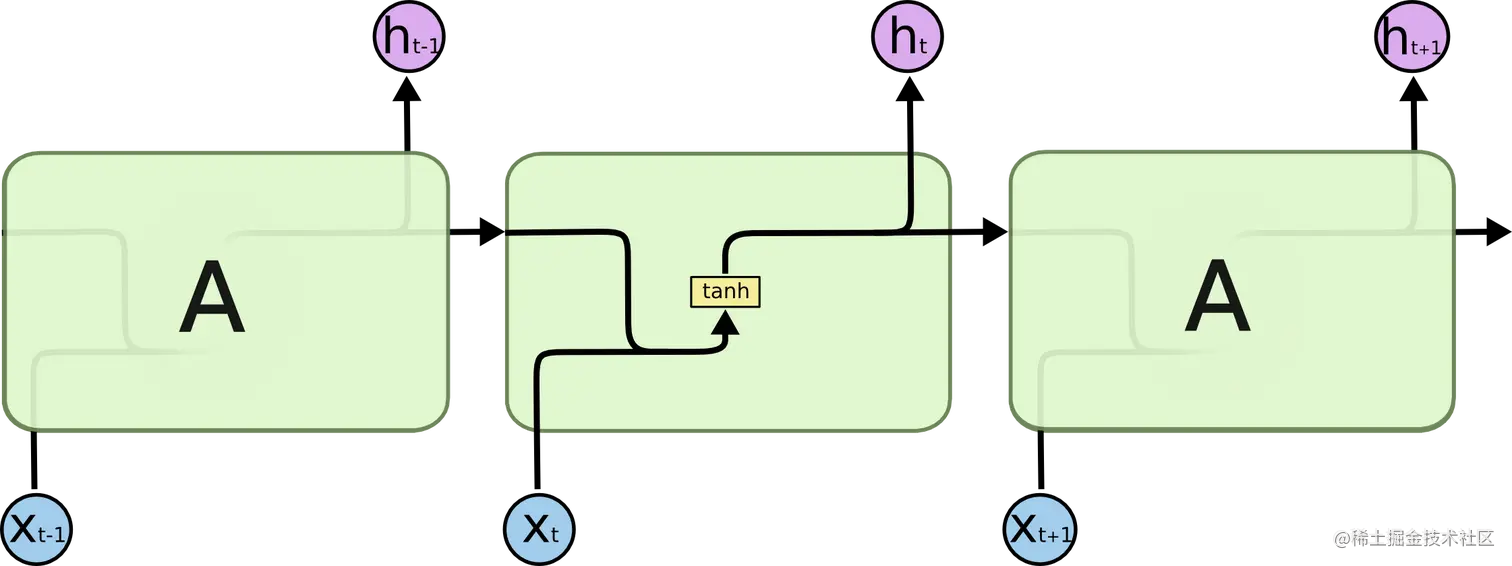 LSTM也有这种链式结构, 但是它的重复模块的结构比标准的RNN要复杂许多,有4个小的结构。
LSTM也有这种链式结构, 但是它的重复模块的结构比标准的RNN要复杂许多,有4个小的结构。
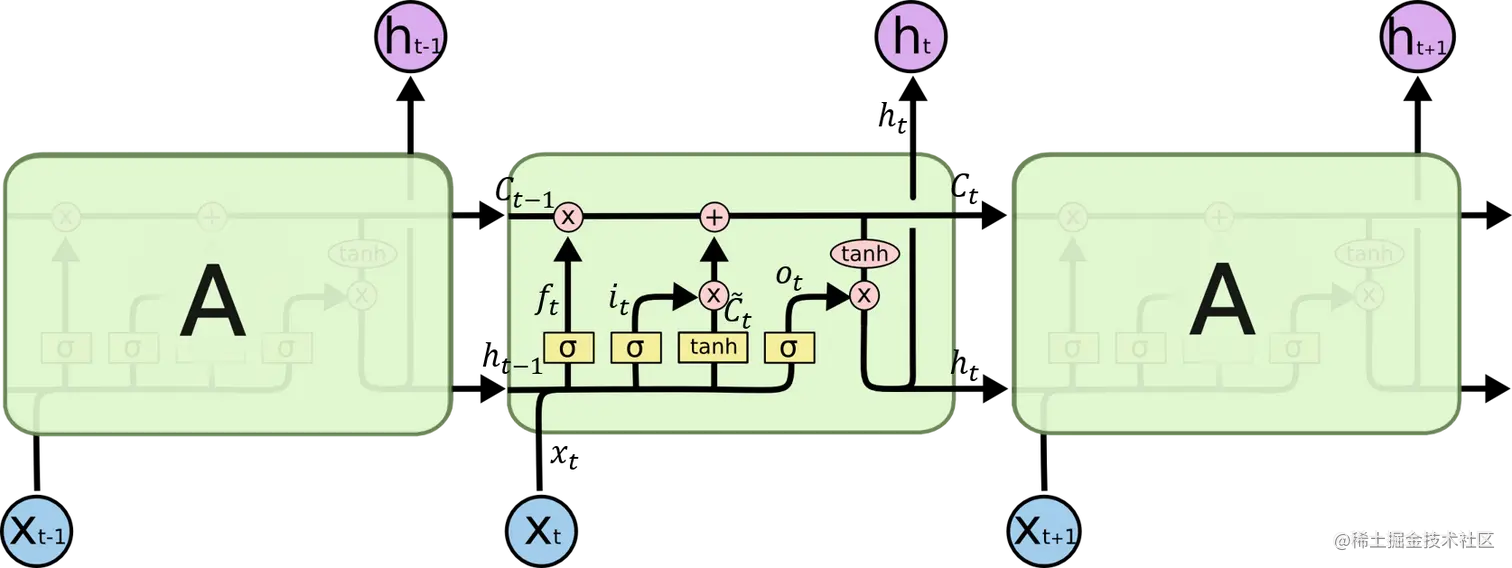 通过合理地组织和开启一种称为“门”的结构,LSTM可以学习到它应该学习多久的信息, 什么时候开始遗忘, 什么时候学习新的信息, 以及如何将旧的信息和新的输入合理地结合起来。
通过合理地组织和开启一种称为“门”的结构,LSTM可以学习到它应该学习多久的信息, 什么时候开始遗忘, 什么时候学习新的信息, 以及如何将旧的信息和新的输入合理地结合起来。
forget gate:ftinput gate:itcandidate cell state:C~tnew cell state:Ctoutput gate:otnew hiddenvalue:ht=σ(Wf⋅[ht−1,xt]+bf)=σ(Wi⋅[ht−1,xt]+bi)=tanh(WC⋅[ht−1,xt]+bC)=ft∗Ct−1+it∗C~t=σ(Wo⋅[ht−1,xt]+b0)=ot∗tanh(Ct)
关于上图中LSTM结构的详细介绍见 Understanding LSTM Networks.
LSTM Variants
LSTM有许多变种,其中一种就是将输入门和遗忘门结合起来。 Gated Recurrent Unit(GRU) 就是这样的一个例子。它将输入门和遗忘门合并成一个更新门,并且它把隐藏层状态和细胞状态合并起来。



