


介绍PySpark GroupBy Agg
PySpark GroupBy是PySpark数据模型中的一个分组函数,它使用一些列值将行分组。它的工作模式是根据一些列值条件对数据进行分组,并将数据聚合为最终结果。它是一个聚合函数,能够一起计算许多聚合,这个Agg函数一次占用几个聚合函数,然后使用其中的值对分组的数据记录进行聚合。这些函数可以是最大、最小、总和、平均值等。
语法。
PySpark GroupBy AGG函数的语法是。
>>> from pyspark.sql.functions import sum,avg,max,min,mean,count
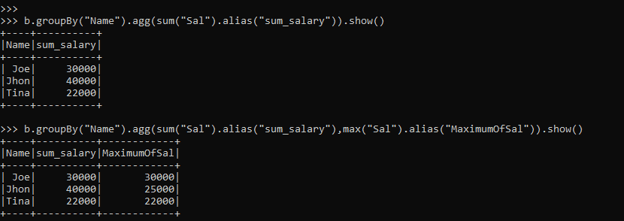
>>>b.groupBy("Name").agg(sum("Sal").alias("sum_salary"),max("Sal").alias("MaximumOfSal")).show()
- B:- 用于Group By Agg函数的数据框架。
- GroupBy ("ColName"):-需要用于数据分组的Group By函数。
- Agg:- Aggregate函数可以把多个agg函数放在一起,结果可以一次性计算出来。
屏幕截图。

在PySpark中使用GroupBy的聚合函数的工作原理
GroupBy函数遵循在PySpark RDD/数据框架模型上操作的键值方法。
具有相同键的数据使用分区进行洗牌,并在PySpark集群的一个分区上被分组。洗牌操作被用来移动数据进行分组。相同的关键元素被分组并返回值。Group By函数中的聚合函数可以用来取多个聚合函数,在该函数上进行计算,然后只一次性返回结果。该函数可以是sum、max、min等,可以在被分组的数据框架的列上触发。
该函数将与列名一起提供的函数应用于所有分组的列数据,并返回结果。
示例
让我们先在PySpark中创建一个样本数据框。
>>> data1 = [{'Name':'Jhon','Sal':25000,'Add':'USA'},{'Name':'Joe','Sal':30000,'Add':'USA'},{'Name':'Tina','Sal':22000,'Add':'IND'},{'Name':'Jhon','Sal':15000,'Add':'USA'}]
该数据包含姓名、工资和地址,将被用作创建数据框的样本数据。
>>> a = sc.parallelize(data1)
sc.parallelize将被用于创建具有给定数据的RDD。
>>> b = spark.createDataFrame(a)
创建后,我们将使用createDataFrame方法来创建数据框。
这就是数据框架的样子。
>>> b.show()
屏幕截图。

首先,让我们开始导入所需的必要导入。
>>> from pyspark.sql.functions import sum,avg,max,min,mean,count
让我们把Group By函数与几个Agg放在一起,一次性计算,分析结果。
>>> >>> b.groupBy("Name")
<pyspark.sql.group.GroupedData object at 0x00000238AAAAD3C8>
屏幕截图。

这将根据名称对数据进行分组,作为SQL.group.groupedData。
我们将使用聚合函数sum来对按Name列分组的工资列进行求和。
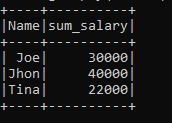
>>> b.groupBy("Name").agg(sum("Sal").alias("sum_salary")).show()
这将返回按Name列分组的工资列的总和。这是我们应用的一个函数,并分析了结果。
Jhon, Joe, Tine的工资被分组,工资的总和将分别作为Sum_Salary返回。
屏幕截图。
多重 Agg 函数示例
这里我们将在列值上使用多个不同的Agg函数,并分析其结果。
>>>b.groupBy("Name").agg(sum("Sal").alias("sum_salary"),max("Sal").alias("MaximumOfSal"),min("Sal").alias("MinOfSal")).show()
这里使用的三个Agg函数是SUM SALARY,MIN SAL和SAL的MAX,这将被一次性计算出来,其结果被计算在一个单独的列中。
输出分析。
屏幕截图。

这些列的值和AGG函数可以根据分析要求进行改变。
屏幕截图。
这些是PySpark GroupBy AGG的一些例子。
请注意。
1.PySpark GroupBy Agg是PySpark数据模型中的一个函数,用于将多个Agg函数结合在一起并分析结果。
2.2.PySpark GroupBy Agg可以用来计算聚合,并在一次计算中轻松分析数据模型。
3.3.PySpark GroupBy Agg将多行数据转换为单一输出。
4.4.PySpark GroupBy Agg包括网络上的数据洗牌。
总结
从上面的文章中,我们看到了GroupBy AGG在PySpark中的工作。从各种例子和分类中,我们试图了解GroupBy AGG是如何在PySpark中使用的,以及在编程层面上是如何使用的。所用的各种方法显示了它是如何简化数据分析的模式和一个具有成本效益的模型。
我们也看到了GroupBy AGG在PySpark数据框架中的内部工作和优势,以及它在各种编程目的中的使用。此外,语法和例子帮助我们准确地理解了这个功能。
