

ML.NET是一个面向.NET开发者的开源、跨平台的机器学习框架,能够将自定义的机器学习模型集成到.NET应用程序中。
几周前,我们分享了一篇博文,介绍了我们在ML.NET的框架和工具方面的工作进展。其中一些更新包括我们深度学习计划的组成部分。该计划的一个重要部分包括在ML.NET中引入注重场景的API。
经过几个月的工作以及与TorchSharp和微软研究院的合作,今天我们很高兴地宣布文本分类API。
文本分类API是一个API,它使你更容易在ML.NET中使用最新的最先进的深度学习技术来训练自定义文本分类模型。
什么是文本分类?
文本分类,顾名思义,就是将标签或类别应用于文本的过程。
常见的用例包括。
- 将电子邮件归类为垃圾邮件或非垃圾邮件
- 分析客户评论中的情绪是积极的还是消极的
- 将标签应用于支持票据
用机器学习解决文本分类问题
分类是机器学习中一个常见的问题。你可以使用各种算法来训练分类模型。文本分类是分类的一个子类别,专门处理原始文本。文本带来了有趣的挑战,因为你必须考虑到文本出现的背景和语义。因此,对意义和背景进行编码可能会很困难。近年来,深度学习模型已经成为解决自然语言问题的一种有前途的技术。更具体地说,一种被称为变换器的神经网络已经成为解决自然语言问题的主要方式,如文本分类、翻译、总结和问题回答。
变换器是在《注意就是一切》一文中介绍的。一些用于自然语言任务的流行转化器架构包括。
- 变换器的双向编码器表示法(BERT)
- 稳健优化的BERT预训练方法(RoBERTa)
- 生成式预训练变换器2(GPT-2)。
- 生成式预训练变换器3 (GPT-3)
在高层次上,转化器是一个由编码和解码层组成的模型结构。编码器将原始文本作为输入,并将输入映射到数字表示(包括上下文)以产生特征。解码器使用来自编码器的信息来产生输出,如文本分类中的类别或标签。使这些层如此特别的是注意力的概念。注意力是指根据输入的上下文与序列中其他输入的关系的重要性来关注输入的特定部分的想法。例如,假设我正在根据标题对新闻文章进行分类。并非标题中的所有字都是相关的。在 "汽车销售创历史新高 "这样的标题中,像 "销售 "这样的词可能会得到更多的关注,并导致将该文章标记为商业或金融。
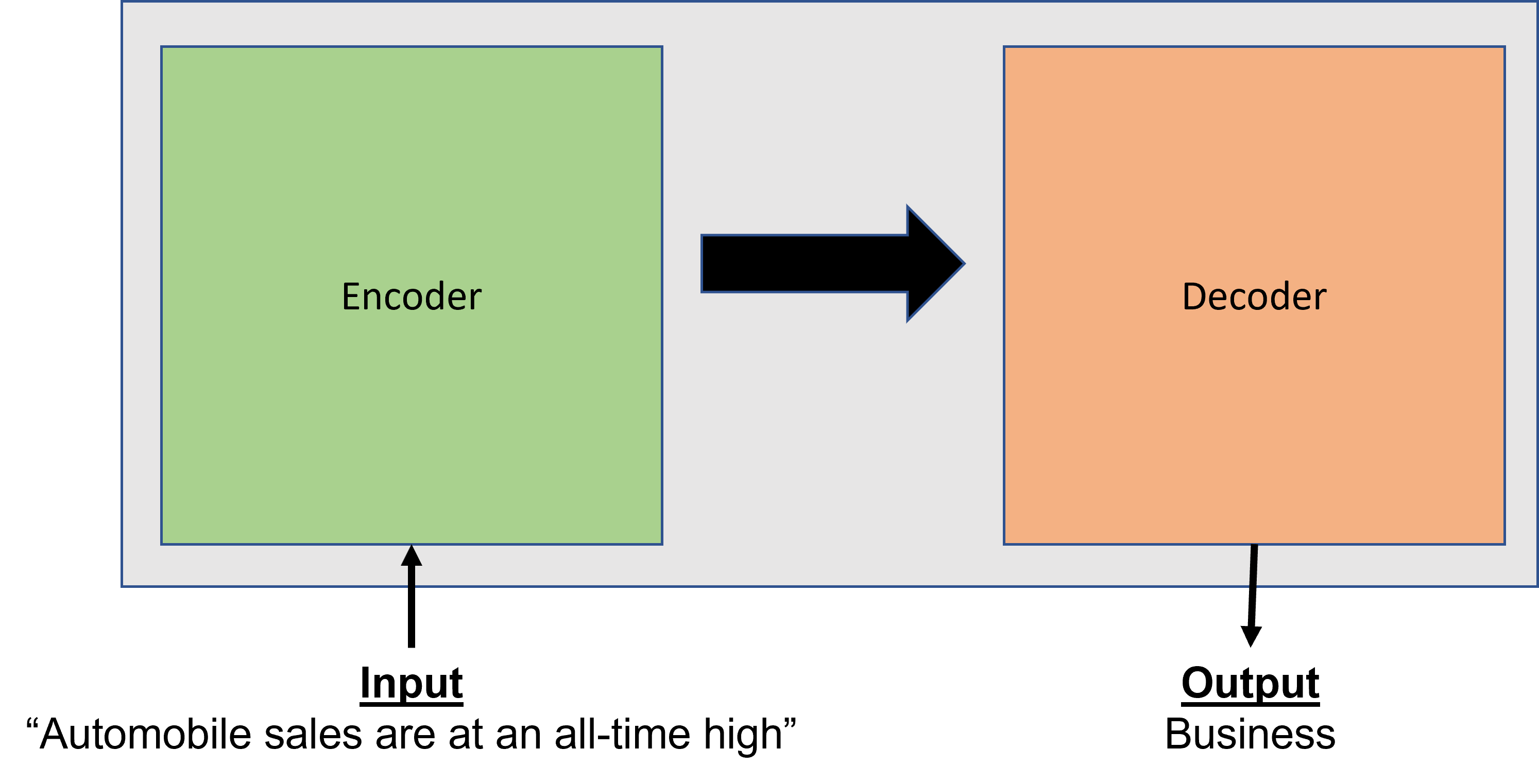
像大多数神经网络一样,从头开始训练转化器可能很昂贵,因为它们需要大量的数据和计算。然而,你并不总是要从头开始训练。使用一种被称为 "微调 "的技术,你可以使用一个预先训练好的模型,并使用你自己的数据重新训练特定于你的领域或问题的层。这样做的好处是,你可以拥有一个更适合解决你的问题的模型,而不必经历从头开始训练整个模型的过程。
文本分类API(预览)
现在你对如何使用深度学习解决文本分类问题有了一个大致的了解,让我们来看看我们是如何将这些技术纳入文本分类API的。
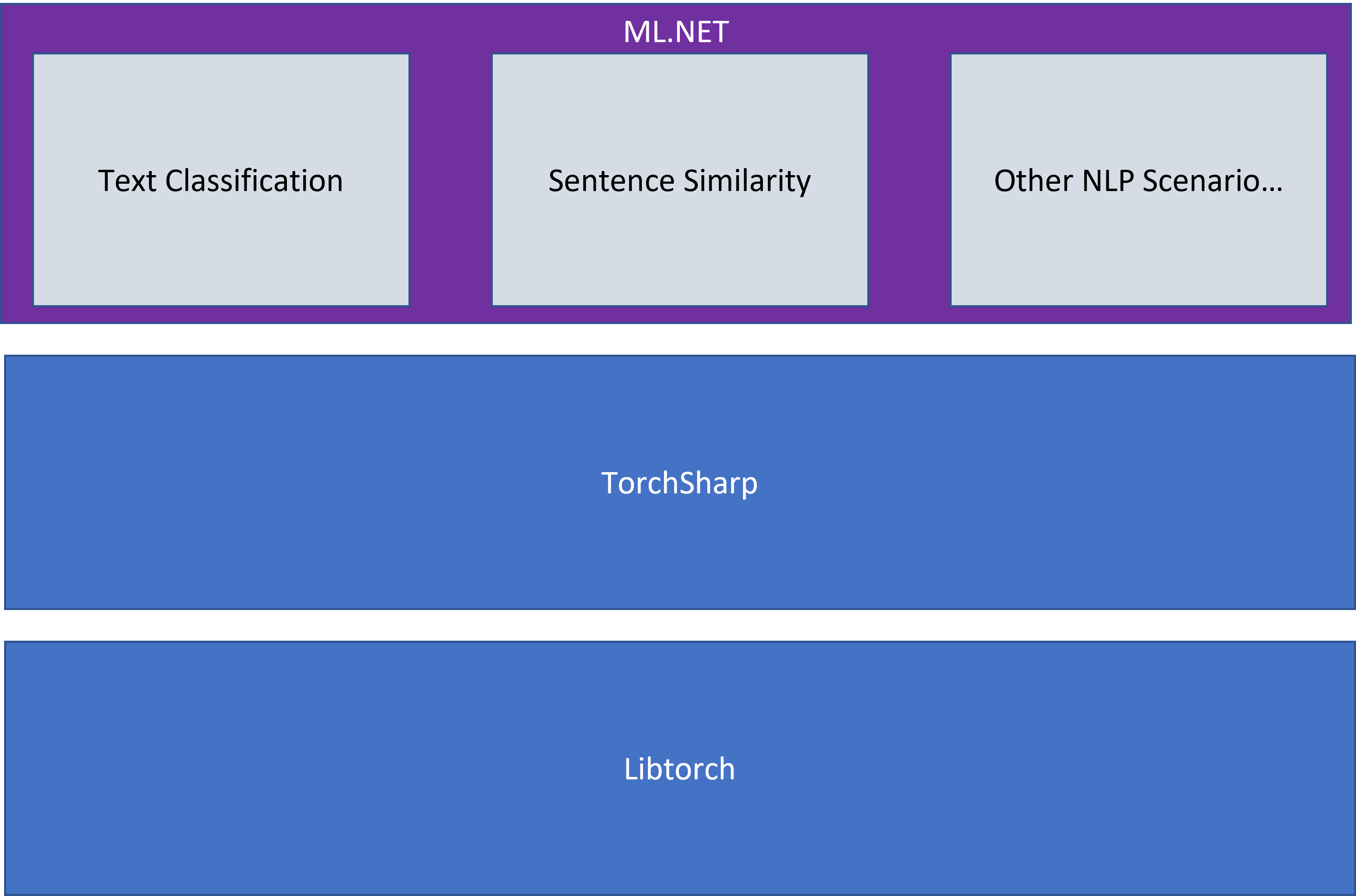
文本分类API是由TorchSharp提供的。TorchSharp是一个.NET库,它提供了对libtorch的访问,libtorch是支持PyTorch的库。TorchSharp包含了在.NET中从头开始训练神经网络的构建块。然而,TorchSharp组件是低级别的,从头开始构建神经网络有一个陡峭的学习曲线。在ML.NET中,我们已经把一些复杂的东西抽象到了场景层面。
在与微软研究院的直接合作中,我们采用了NAS-BERT的TorchSharp实现,这是一个用神经结构搜索获得的BERT的变种,并将其添加到ML.NET中。使用这个模型的预训练版本,文本分类API使用你的数据来微调这个模型。
开始使用文本分类API
有关文本分类API的完整代码样本,请参见文本分类API笔记本。
文本分类API是ML.NET最新的2.0.0和0.20.0预览版本的一部分。
要使用它,你必须安装以下软件包,此外还有 Microsoft.ML:
Microsoft.ML.TorchSharpTorchSharp-cpu如果使用CPU或TorchSharp-cuda-windows/TorchSharp-cuda-linux如果使用GPU。
使用Visual Studio中的NuGet包管理器或dotnet CLI来安装这些包。
dotnet add package Microsoft.ML --prerelease
dotnet add package Microsoft.ML.TorchSharp --prerelease
// If using CPU
dotnet add package TorchSharp-cpu
// If using GPU
// dotnet add package TorchSharp-cuda-windows
// dotnet add package TorchSharp-cuda-linux
然后,引用这些包,在你的管道中使用文本分类API。
//Reference packages
using Microsoft.ML;
using Microsoft.ML.TorchSharp;
// Initialize MLContext
var mlContext = new MLContext();
// Load your data
var reviews = new[]
{
new {Text = "This is a bad steak", Sentiment = "Negative"},
new {Text = "I really like this restaurant", Sentiment = "Positive"}
};
var reviewsDV = mlContext.Data.LoadFromEnumerable(reviews);
//Define your training pipeline
var pipeline =
mlContext.Transforms.Conversion.MapValueToKey("Label", "Sentiment")
.Append(mlContext.MulticlassClassification.Trainers.TextClassification(numberOfClasses: 2, sentence1ColumnName: "Text"))
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
// Train the model
var model = pipeline.Fit(reviewsDV);
在这个例子中,由于只有两个类("Positive "和 "Negative"),numberOfClasses 参数被设置为2 。API最多支持两个句子作为输入,每个句子限制为512个标记。一般来说,一个标记对应于一个句子中的一个词。如果句子长于512个令牌,它将自动为你截断。在这种情况下,由于只有一个句子,所以只设置sentence1ColumnName 。
训练产生一个ML.NET模型,你可以使用Transform 方法或PredictionEngine 来进行推断。
下一步是什么?
这是在ML.NET中实现自然语言场景的第一批步骤之一。在使用文本分类API时仍有一些限制,比如不能使用Evaluate 方法来计算评估指标。根据你的反馈,我们计划。
- 对文本分类API进行改进
- 引入其他基于场景的API
我们希望听到你的意见。通过在dotnet/machinelearningGitHub repo中提供反馈和提出问题,帮助我们确定优先次序并使这些体验达到最佳效果。
