

这是我参与「第三届青训营 -后端场」笔记创作活动的第5篇笔记
经典案例
一条数据从产生、流动,最后持久化的全生命周期
注册App -> 用户名密码 ->数据库
一条用户注册结构化数据 -> 后端服务器 -> 数据库系统 -> 其他系统
数据的持久化
- 校验数据的合法性
- 修改内存:用高效的数据结构组织数据
- 写入存储介质:以寿命 & 性能友好的方式写入硬件(有时候关注硬件寿命)
潜在的问题
数据库怎么保证数据不丢?
数据库怎么处理多人同时修改的问题?
除了数据库还能存到别的存储系统吗?
数据库只能处理结构化数据吗?
有哪些操作数据库的方式,要用什么编程语言?
存储 & 数据库系统简介
存储系统
系统概览
什么是存储系统?
一个提供读写、控制类接口,能够安全有效地把数据持久化的软件,就可以称为存储系统。
需要和用户,存储介质,内存,网络编程打交道。
系统特点
- 作为后端软件的底座,性能敏感
- 存储系统代码,既“简单”又“复杂”:复杂在非IO处理必须要考虑多重情况,各种异常
- 存储系统软件架构,容易受硬件影响
存储器层级结构(存储天梯图)
高容量往往低性能
数据怎么从应用到存储介质
第一条规律:从内存写入存储介质时,有的硬件可能只允许一个byte一个byte进行读写,所以「缓存」很重要,贯穿整个存储体系。
第二条规律:「拷贝」很昂贵,应该尽量减少。拷贝需要占用cpu,降低机器性能。
第三条规律:Disk代指任何存储介质,硬件设备五花八门,需要有统一抽象的接入层
RAID技术
单机存储系统怎么做到高性能 / 高性价比 / 高可靠性?
R(edundant) A(rray) of I(nexpensive) D(isk)
RAID0
- 多块磁盘简单组合
- 数据条带化存储,提高磁盘带宽
- 没有额外的容错设计
RAID1
一块磁盘对应一块额外镜像盘
真实空间利用率仅50%
容错能力强
RAID 0 + 1
结合 RAID 0 和 RAID 1
数据库 vs 经典存储
数据库和存储系统不一样吗?
把数据库分两大类来谈:关系型数据库、非关系型数据库
关系是什么?
关系= 集合 = 任意元素组成的若干有序偶对反应了事物间的关系
关系型数据库是存储系统, 但在存储之外,又发展出其他能力
- 结构化数据友好
- 支持事务(ACID)
- 支持复杂查询语言,如SQL
非关系数据库也是存储系统,但是一般不要求「严格」的结构化
- 半结构化数据友好
- 可能支持事务
- 可能支持复杂查询语言
结构化数据管理比较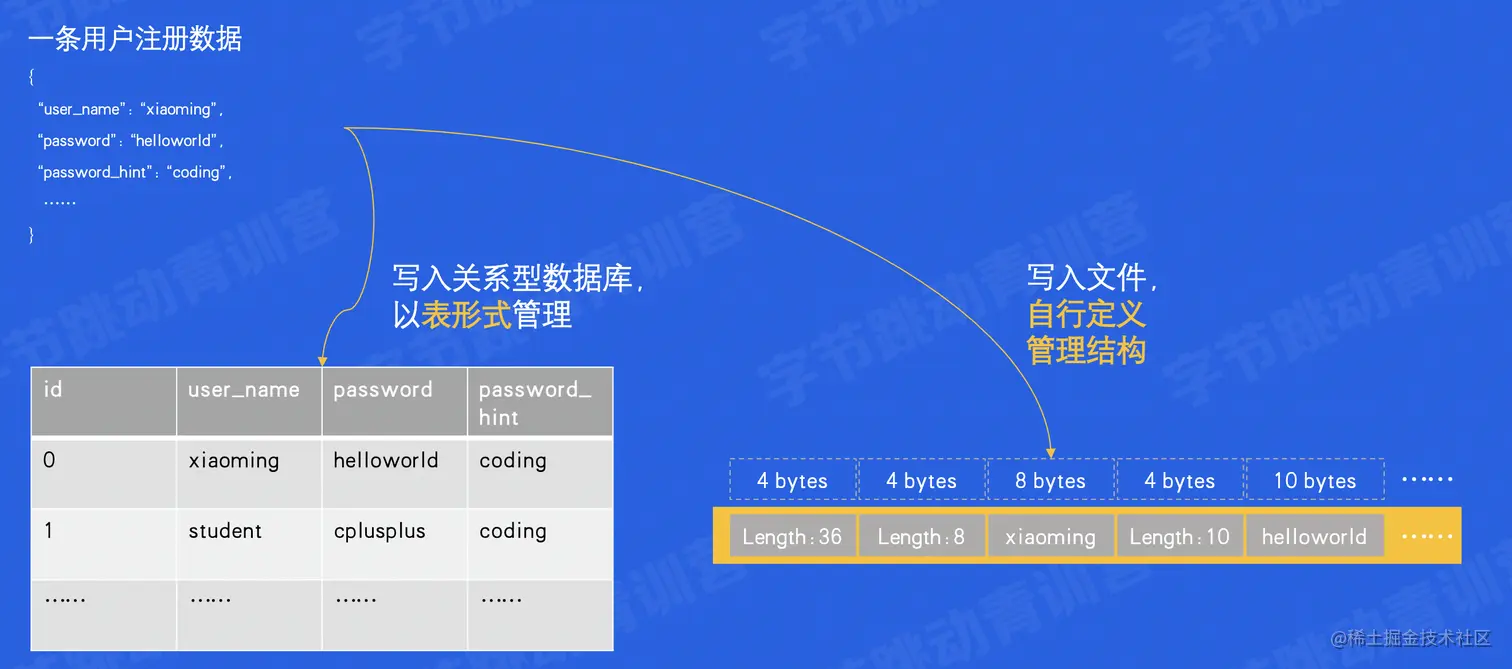
经典存储需要设计一个结构体
事务能力
- A(tomicity), 原子性,事务内的操作要么全做,要么不做
- C(onsistency),一致性,事务执行前后,数据状态是一致的
- I(solation),隔离性,可以隔离多个并发事务,避免影响
- D(urability),持久性,事务一旦提交成功,数据保证持久性
数据库支持事务,有优越性。
复杂查询能力
数据库:灵活简洁
经典存储:需要写多行代码,僵化复杂
主流产品剖析
单机存储
从单机存储系统到分布式存储系统
单机存储:单个计算机节点上的存储软件
本地文件系统
Linux:一切皆文件
Linux文件系统两大数据结构:Index Node 和 Directory Entry
Key-value存储
世间一切皆key-value
常见数据结构 LSM-Tree,某种程度上牺牲读性能,追求写入性能 (Append顺序写)
产品:RocksDB
分布式存储
在单机储存基础上实现了分布式协议,涉及大量网络交互。
HDFS:大数据时代的基石
2002-2003时代背景:
专用的高级硬件很贵,同时数据存量很大,要求超高吞吐
HDFS核心特点:
- 支持海量数据存储
- 高容错性
- 弱POSIX语义
- 普遍使用x86服务器,性价比高
Ceph:开源分布式存储系统万金油
特点:
- 一套系统支持对象接口、块接口、文件接口,但是「一切皆对象」
- 数据写入采用主备复制模型
- 数据分布模型采用CRUSH算法
单机数据库
单机数据库 = 单个计算机节点的数据库系统
关系型数据库
Query Engine:复杂解析query,生成查询计划
Txn Manager:复杂事务并发管理
Lock Manager:负责锁相关的策略
Storage Engine:复杂组织内存/磁盘数据结构
Replication:复杂主备同步
关键内存数据结构:B-Tree B+ tree LRU list等
关键磁盘数据结构:WriteAheadLog(RedoLog) Page
左边内存中:
用户想要更新一套数据,本质上就是想要更新内存上Page节点中的数据,还需要写入操作到Redo Log,保证数据不会丢失。
内存中除了Page数据,还有大量临时数据Temp data,防止内存不够用,把各种结果存储成临时数据,到合适时机再把temp data拼接起来。
右边磁盘结构中:
Page File对应树结构的Page
Redo Log File
Others存临时数据文件,内存不够用,把查询过程中的数据先放进来。
非关系型数据库
MongoDB、Redis、Elasticsearch
- 交互方式各不相同
- schema相对灵活
- 尝试支持SQL查询和事务
Elasticsearch
模糊匹配方面做得好,并且能自动算出关联程度,内嵌的,不需要用户配置
mongoDB
纯C,非常灵活
Redis
纯C,超高性能,支持多种数据结构
\
分布式数据库
MIT 6.824
为什么需要引入分布式架构?
- 容量问题
单点:容量有限,受硬件限制
分布式:能存储节点池化,动态扩缩容
- 解决弹性问题
单点:CPU资源不够,扩容后需要搬迁全量数据,时间长,缩容,Disk问题难以解决
分布式:池化解决以上问题
- 解决性价比问题
分布式:池化解决问题
More to Do
单写 vs 多写
磁盘弹性 to 内存弹性
新技术演进
概览
- 软件结构变更:Bypass OS kernel(已经成为趋势)
- AI增强: 智能存储格式转换
- 新硬件革命: 存储介质变更,计算单元变更,网络硬件变更
SPDK
Storage Performance Development Kit
- Kernel Space -> User Space
- 中断 -> 轮询
- 无锁数据结构
AI & Storage
行存 列存 混合
高性能硬件
