

由于其快速的响应性、先进的版本、可持续性和强大的索引能力,MongoDB是最著名的NoSQL数据库之一。在许多情况下,MongoDB的查询通过寻找精确的匹配、利用明显大于和小于的比较,或采用正则表达式来对数据进行分类就足够了。然而,当涉及到对具有丰富文本数据的字段进行筛选时,这些策略就显得不足了。本指南将帮助我们创建一个MongoDB文本索引,并使用它来搜索采用普通全文搜索查询和标准的文档。
当我们看到采用短语或关键词的材料时,最好的例子是谷歌搜索。通过MongoDB全文搜索,我们可以使用字符串或字符串数组在文档的任何列上建立文本索引。
Ubuntu 20.04中MongoDB全文搜索的语法?
所述的语法如下。
db.Collection_Name.find({text:{search:"string"}})
在上面的语法中,find()函数是与以下参数一起使用的。
- Collection_Name:指的是现有集合的名称。
- 查找:进行使用查找的搜索。
- $text:用于进行满足我们目标的集合搜索。
- $search:用于执行搜索。
- String:指的是我们要在集合中寻找的某个字符串,我们可以使用搜索功能来寻找精确的词。
在Ubuntu 20.04的MongoDB中研究$text操作符。
文本列表是由MongoDB提供的,以协助对字符串内容进行文本搜索。任何具有字符串值的字段或字符串成分的范围都可以包含在文本记录中。你应该在你的集合里有一个文本记录来做文本搜索问题。甚至一个集合只有一条主题搜索记录。一个列表可以跨越多个字段。
全文搜索在Ubuntu 20.04中的MongoDB中是如何执行的
现在,看看某些例子来更好地理解事情。首先,我们创建了一个名字为 "myDemo "的数据库。在这个数据库中,我们定义了一个集合为 "水果"。然后,insertMany查询被用来插入集合文件,截图显示了下面 "水果 "集合文件的字段和针对这些字段的值。
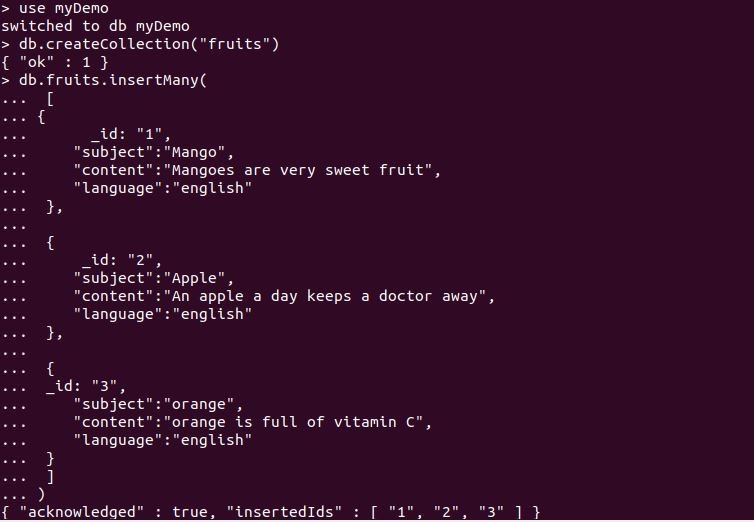
查询 "db.fruit.find() "的结果是 "fruit "这个集合的属性和实体,如下所示。我们为 "水果 "这个集合记录了三个文档。

现在,让我们研究一下如何进行全文搜索。
例子#1:在Ubuntu 20.04的MongoDB中创建文本索引。
在你使用MongoDB的全文搜索功能之前,我们必须在数据集上建立一个文本索引。索引是独特的数据结构,它将一个集合中的每个文本的有限数据与文档本身隔离开来。让我们来看看如何进行全文搜索。
文本索引的建立方式与传统索引相同,它不是定义升/降序,而是定义文本关键词。

上面,我们有一个全文搜索的查询。我们使用了createIndex()方法来创建一个文本索引。我们将两个字段 "主题 "和 "内容 "设置为索引型文本。
通过在MongoDB shell上运行createIndex查询,下面的输出证实了索引的创建。

例#2:在Ubuntu 20.04中从MongoDB的全文中搜索一个单词或短语。
查询由一个或多个单字组成的文档可能是最普遍的搜索挑战。用户可能希望网络浏览器能够适应选择特定搜索短语的显示位置。当采用文本索引时,MongoDB以同样的方式处理常见的搜索查询。通过几个例子,这一步解释了MongoDB如何处理搜索请求。

这里,我们有一个查询 "db.fruit.find()"。该查询采用了text操作符里面,我们还有一个叫做$search的操作符,用来从给定的文档中搜索值 "sweet"。
正如你所看到的,我们只有一个文本内容为 "sweet "的文档。通过运行上述查询,文本内容为 "sweet "的文档的全部细节显示如下。

现在,我们通过使用下面的查询来搜索两个词。

我们把两个词 "维生素C "给了text运算符中被调用。当查询被运行时,它显示了文本中列有维生素C的文档记录,如下所示。

例子#3:对Ubuntu 20.04中MongoDB的全文搜索结果进行打分和排序。
每个文档都从文本搜索中得到一个分数,表明它与搜索查询的相关程度。这个分数被用来对搜索结果中的所有记录进行分类。分数越高意味着比赛越有意义。

我们有一个search操作符的帮助下搜索 "芒果 "和 "橙子 "这两个词。然后,我们有一个投影{score: meta: "textScore"},它利用meta运算符,从检索的文件中返回指定的元数据。textScore元数据是MongoDB全文搜索引擎的内置组件,持有搜索相关性分数,在这种情况下被返回。
正如在过滤文档中提到的,在执行查询后,结果文档将增加一个名为score的新字段。

现在,我们已经使用排序函数对投影{score: $meta: "textScore"}。排序文档使用的语法与投影文档相同。

文本芒果的相关度得分最高,所以它在输出屏幕上排在第一位。

结论。
通过本教程的学习,我们已经掌握了如何使用MongoDB的全文搜索功能。你建立了一个文本索引,并组成了文本搜索查询,包括一个和多个单词、整个短语和排除法。你还对返回的论文的相关性进行了分级,并对搜索结果进行了排序,首先显示最相关的项目。
