


用Python进行数据处理的定义
用Python进行数据处理是指在Python编程语言中,使用户在数据组织中能够使阅读或解释数据的见解更有条理,包括有更好的设计。例如,按字母顺序排列员工的名字,可以更快速地通过名字搜索到某个特定的员工。数据处理的主要特点是使业务运作更快,同时也强调了在这个过程中的优化。通过适当的数据处理,人们可以分析趋势,从财务数据中解释洞察力,分析消费者行为或模式,等等。不仅是分析,它还使用户能够忽略数据集中任何不必要的数据,这样就可以节省空间,只用重要和必要的数据来填补有限的空间。在这篇文章中,我们将研究Python中不同的操作方法,同时也会研究一些例子
用Python进行数据操作的方法
为了操作数据集中的数据,Python一直是开发人员中最著名和最常用的语言。通过Python的开源实现,我们有各种方法来帮助实现Python中的操作方法。对于以下所有方法,我们首先需要在Python中安装pandas,这可以通过在命令提示符下运行以下命令来实现。
pip install pandas
一旦pandas包安装到系统中,我们就需要通过运行pandas库导入到我们的代码库中。
import pandas as pd
之所以使用pd,是为了确保我们可以在任何需要调用相应软件包的地方使用简短的形式。现在我们已经安装并导入了pandas库,我们将使用它的一个函数来读取CSV文件,然后将返回的数据集存储到一个变量中。我们将运行以下代码。
variable_name = pd.read_csv(“file name.csv”)
至此,我们已经准备好探索用Python进行数据操作的不同方法,并在下一节中通过实际的例子来研究这些方法的实用性问题。
1.在给定条件的基础上过滤数值
- 为了只处理符合指南规定的标准的特定数据,我们需要使用相应的数据处理方法来坚持条件。在这种数据操作技术中,我们将使用.loc函数,它允许使用布尔数组或标签访问一组行和/或列。
2.应用某个函数来创建一个新的变量或执行相关操作
- 为了在行或列中应用一个特定的函数,我们将使用pandas中的apply函数。这个函数将相应的声明函数应用到各自的轴上(0代表列,1代表行),最后根据要求返回所需的变量。
3.使用透视函数在所需的列上进行聚合
- 这种方法类似于excel中的透视功能。在这里,我们将在索引中透视我们的数据,并根据要求在其他列上执行所需的聚合。我们在这里使用的函数是.pivot。
4.crosstab的功能
- 使用crosstab函数,人们将能够获得数据的原始视图。使用这一功能,人们可以验证一些潜在的假设,通过查看问题陈述和数据的初始部分,人们将有机会验证这些假设。
5.2个表的合并
- 在正常的现实生活场景中,几乎不可能将所有的数据都驻留在一个数据表中,因此这个功能非常方便,可以根据一个键来合并2个数据集,并且可以在函数".merge "中作为一个参数声明。
6.对表进行排序
- 使用这种数据处理方法,我们可以在键的基础上对表进行排序,这些键将作为参数传递给函数".sort_values"。我们还可以传递一个列的列表,在时间顺序的基础上,对表进行排序。
7.绘制图表和柱状图
- 这个列表的最后一个操作是绘制boxplot和直方图,以了解数据的不同统计参数及其推论,这在视觉上对解释数据集非常有趣。例如,使用boxplot,我们可以很容易地将数据集中的离群点的数量可视化。使用直方图,我们可以确定数据的分布和它的散布!
对于我们下面的例子,我们将使用两个公开可用的数据集,即虹膜数据集和泰坦尼克号数据集!当例子中的变量指的是数据时,我们指的是虹膜数据集!
例子
让我们来讨论一下用Python进行数据操作的例子。
例子#1
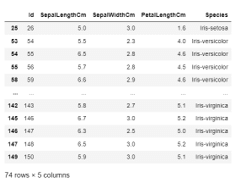
在特定列的条件基础上获取行。
语法。
data.loc[(data["SepalLengthCm"]>=5) & (data["SepalWidthCm"]<=3) & (data["PetalLengthCm"]>1.2), ["Id", "SepalLengthCm", "SepalWidthCm", "PetalLengthCm", "Species"]]
输出。
例子 #2
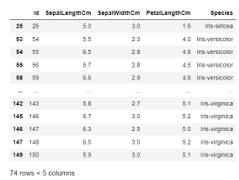
使用apply函数创建新的变量。
语法:
def missingValues(x):
return sum(x.isnull())
print("Number of missing elements column wise:")
print(data.apply(missingValues, axis=0))
print("\nNumber of missing elements row wise:")
print(data.apply(missingValues, axis=1).head())
输出。
例子#3
使用透视表找出每个物种类别的平均萼片宽度。
语法:
import numpy as np
pivot_table = data.pivot_table(values=["SepalWidthCm"], index=["Species"], aggfunc=np.mean)
print(pivot_table)
输出。

例子 #4
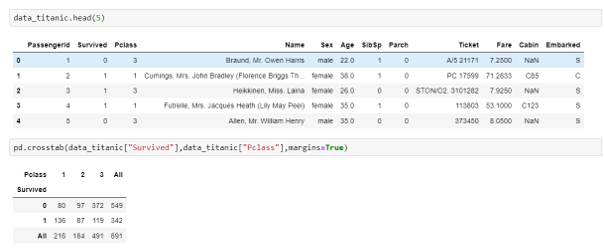
寻找2个分类列中的数据分布。
语法:
import pandas as pd
data_titanic = pd.read_csv("train.csv")
pd.crosstab(data_titanic["Survived"],data_titanic["Pclass"],margins=True)
输出。
例#5
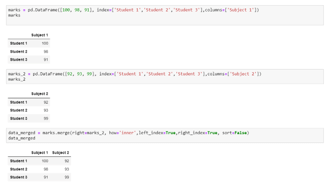
在各自表的索引的基础上合并2个表。
语法:
marks = pd.DataFrame([100, 98, 91], index=['Student 1','Student 2','Student 3'],columns=['Subject 1'])
marks
marks_2 = pd.DataFrame([92, 93, 99], index=['Student 1', 'Student 2', 'Student 3'],columns=['Subject 2'])
marks_2
data_merged = marks.merge(right=marks_2, how='inner', left_index=True, right_index=True, sort=False)
data_merged
输出。
例#6
以降序形式排列一个表,通过多列优先考虑一个列,然后是另一个。
语法:
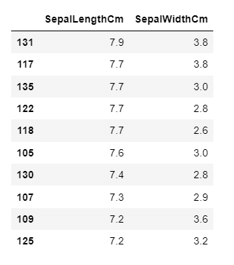
data_sorted = data.sort_values(['SepalLengthCm','SepalWidthCm'], ascending=False)
data_sorted[['SepalLengthCm','SepalWidthCm']].head(10)
输出。
例子 #7
在Iris的数据集上绘制boxplot。
语法:
import matplotlib.pyplot as plt
%matplotlib inline
data.boxplot(column="SepalLengthCm",by="Species")
输出。

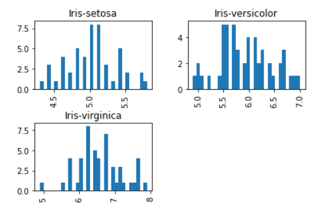
例子 #8
在虹膜数据集上绘制柱状图。
语法:
import matplotlib.pyplot as plt
%matplotlib inline
data.hist(column="SepalLengthCm",by="Species",bins=30)
输出。
结论
在这篇文章的帮助下,我们研究了可能的操作方法,以及每种方法的例子。尽管这些并不是一个详尽的清单,但我们已经尽力涵盖了行业内广泛使用的最大范围的方法。人们可以用其他的方法进行实验,显然需要学习更多的东西!
推荐文章
这是用Python进行数据操作的指南。在这里,我们讨论了定义、语法、用Python进行数据操作的方法,以及为了更好地理解而举的例子。你也可以看看下面的文章,以了解更多信息
The postData Manipulation with Pythonappeared first onEDUCBA.
